Download as PDF, PPTX















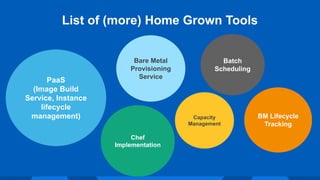










The document outlines Workday's next-generation private cloud, focusing on the fifth generation of its OpenStack platform, emphasizing improved customer satisfaction and high service reliability. It discusses various technical components, including cluster configurations, development environments, and home-grown tools used for managing the infrastructure while maintaining high security and performance standards. The document also highlights unique development practices and challenges faced during the evolution of Workday's private cloud.



































































