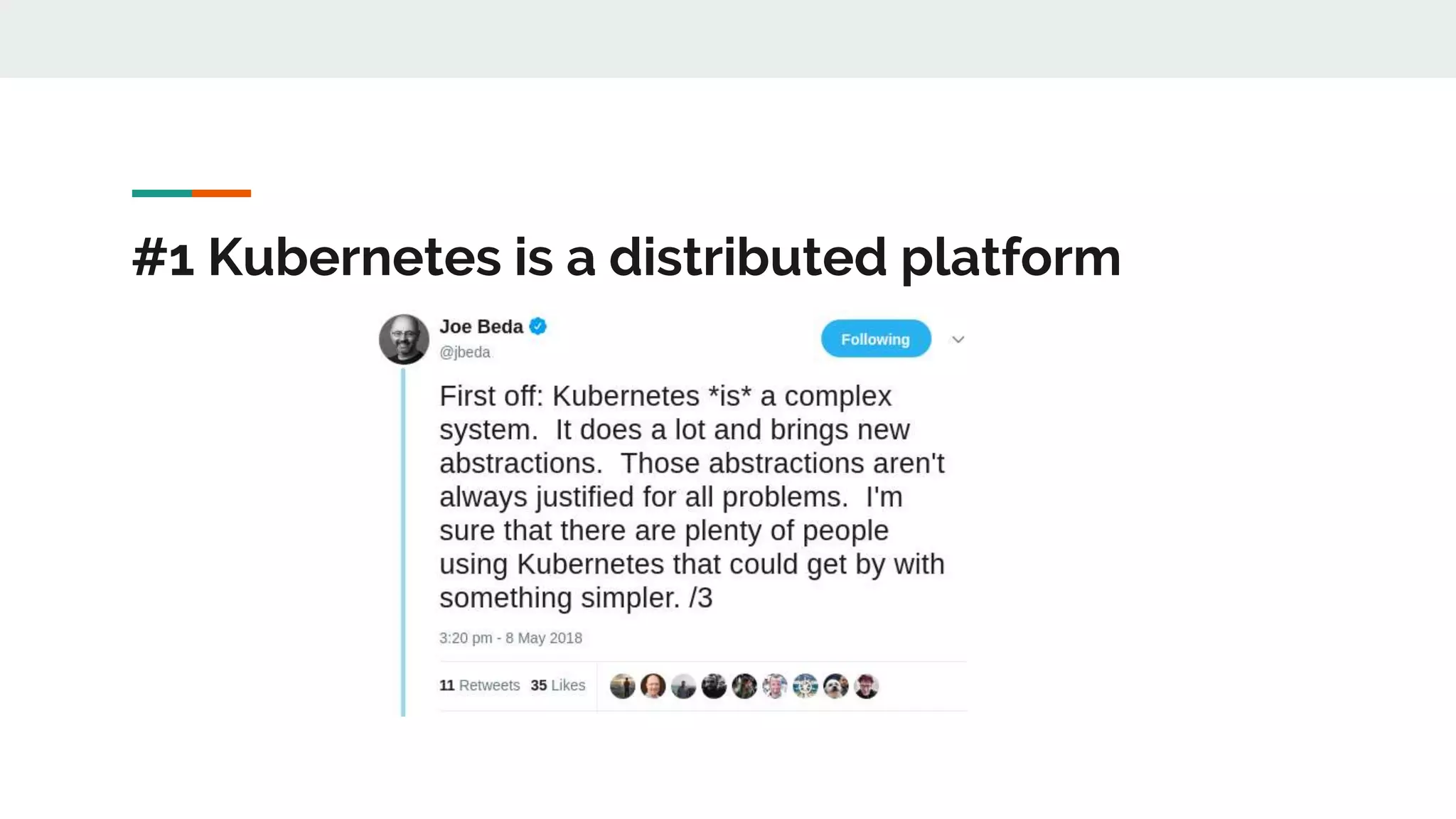
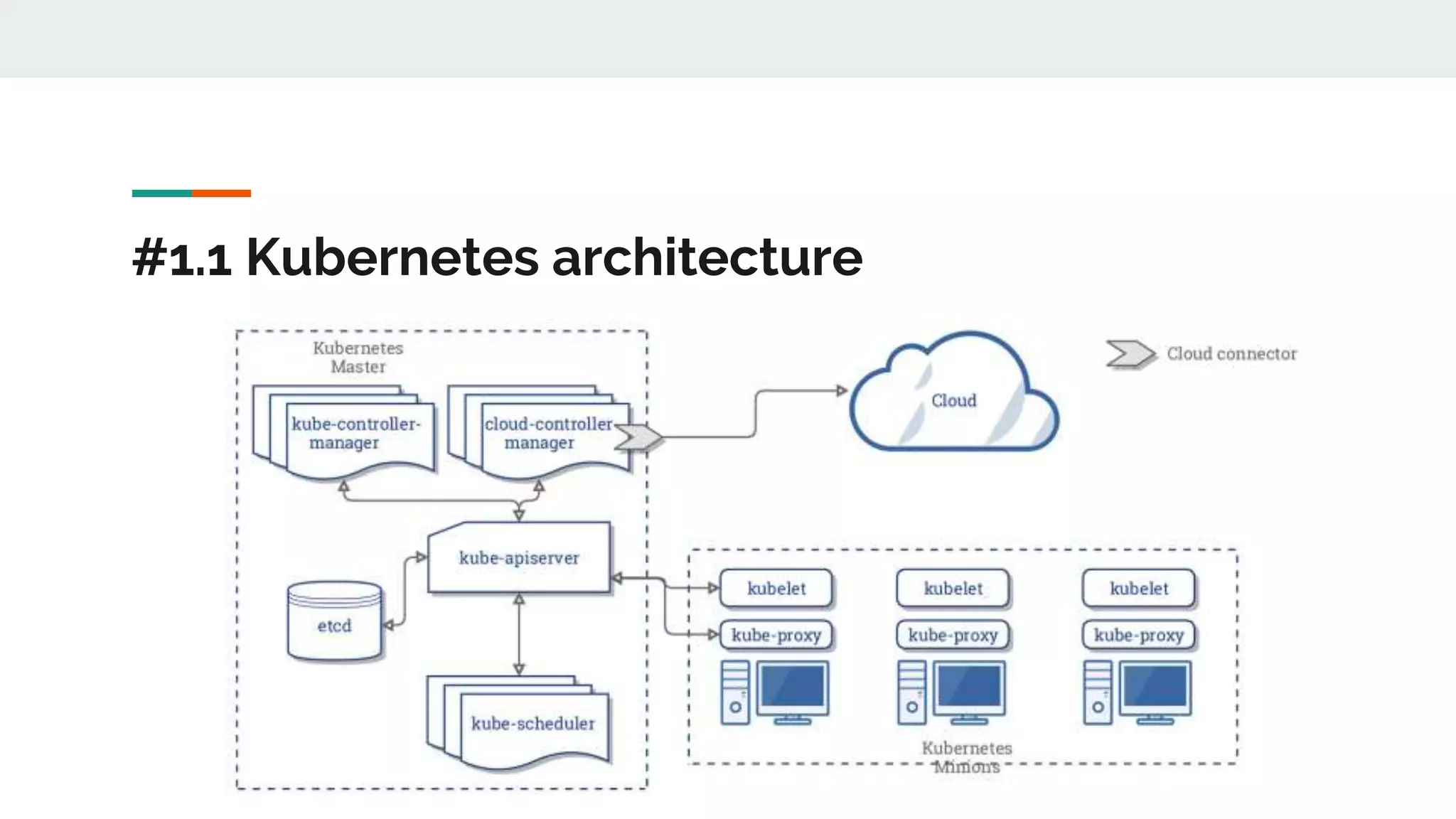
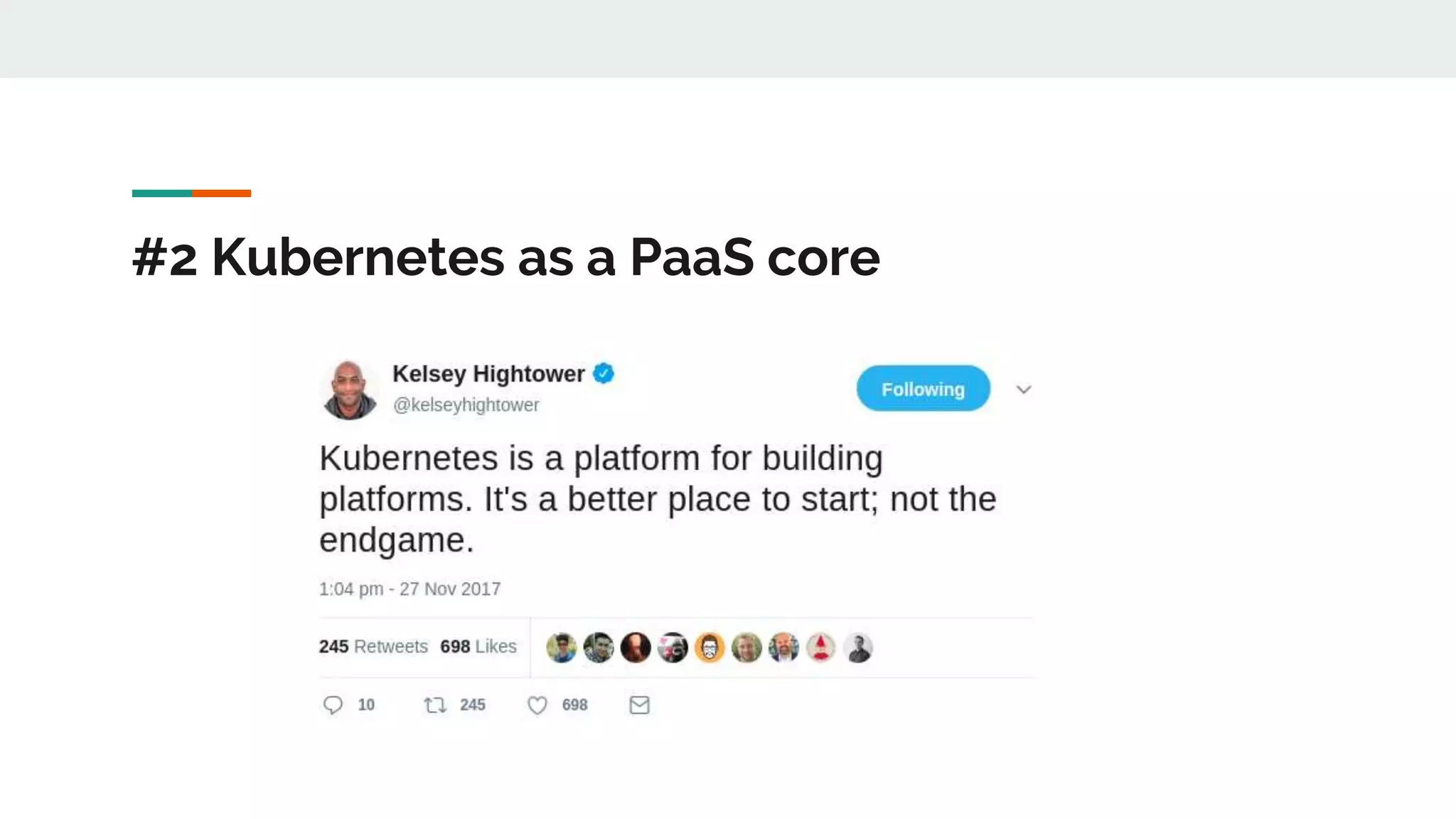
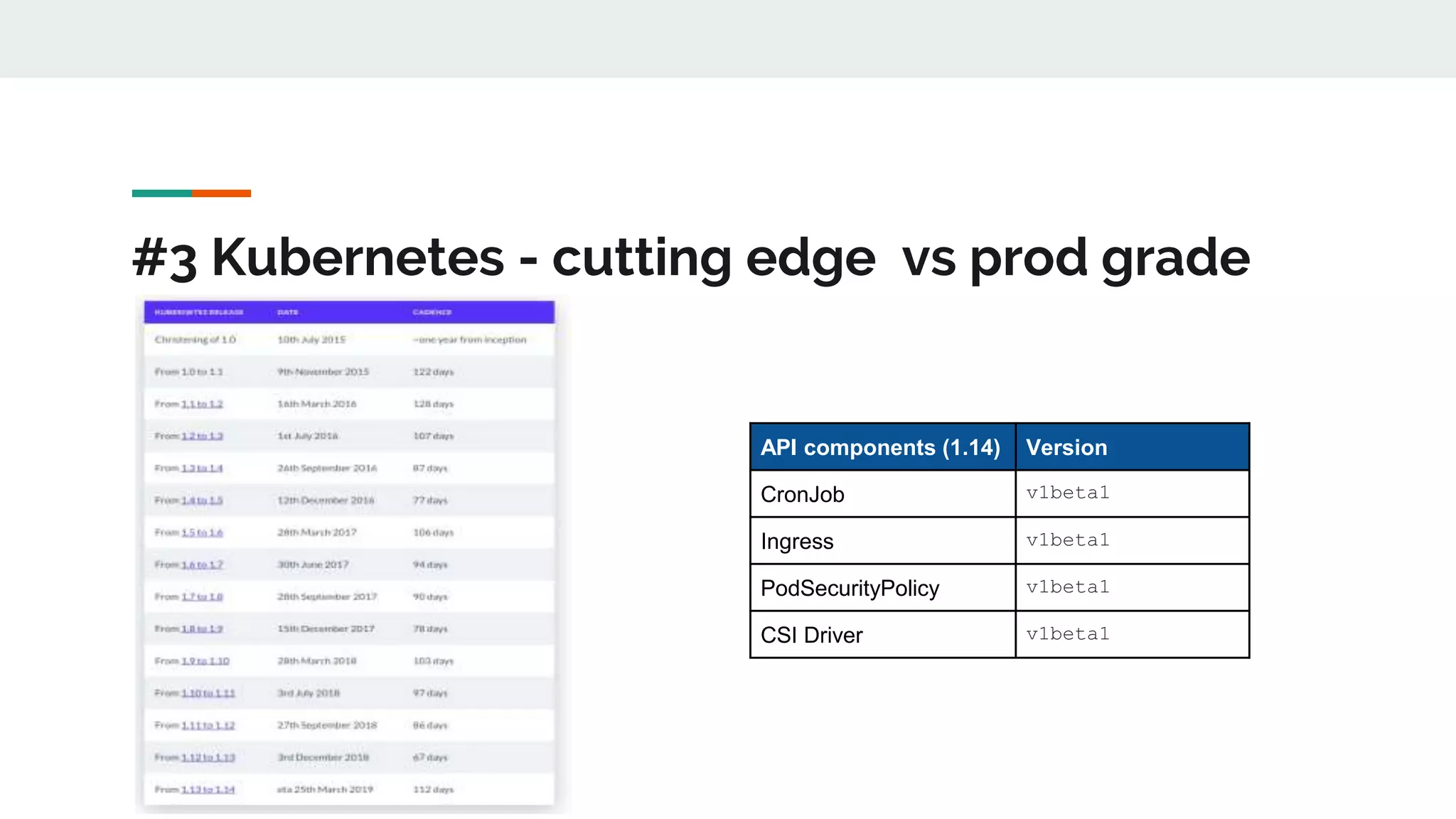
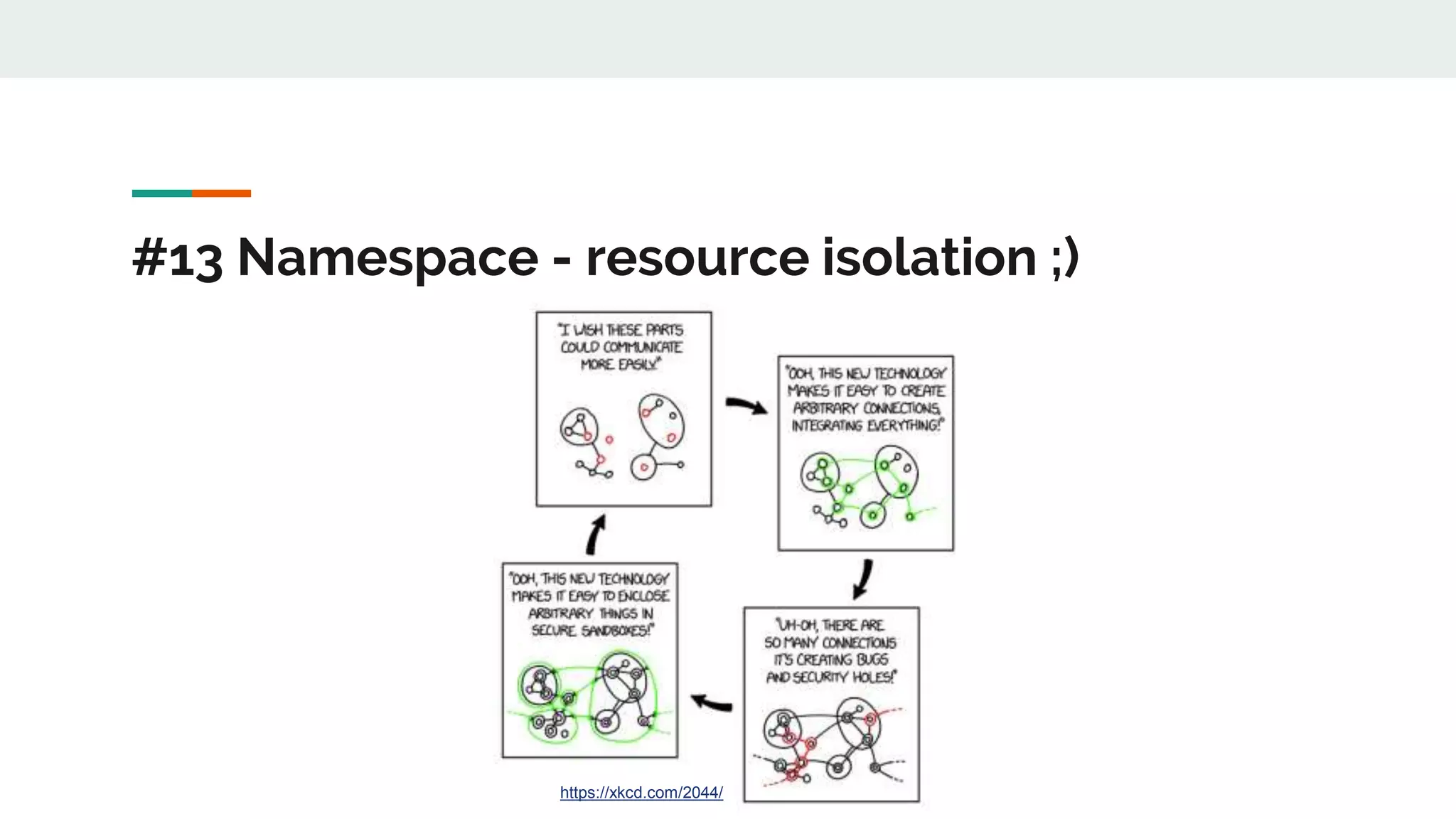
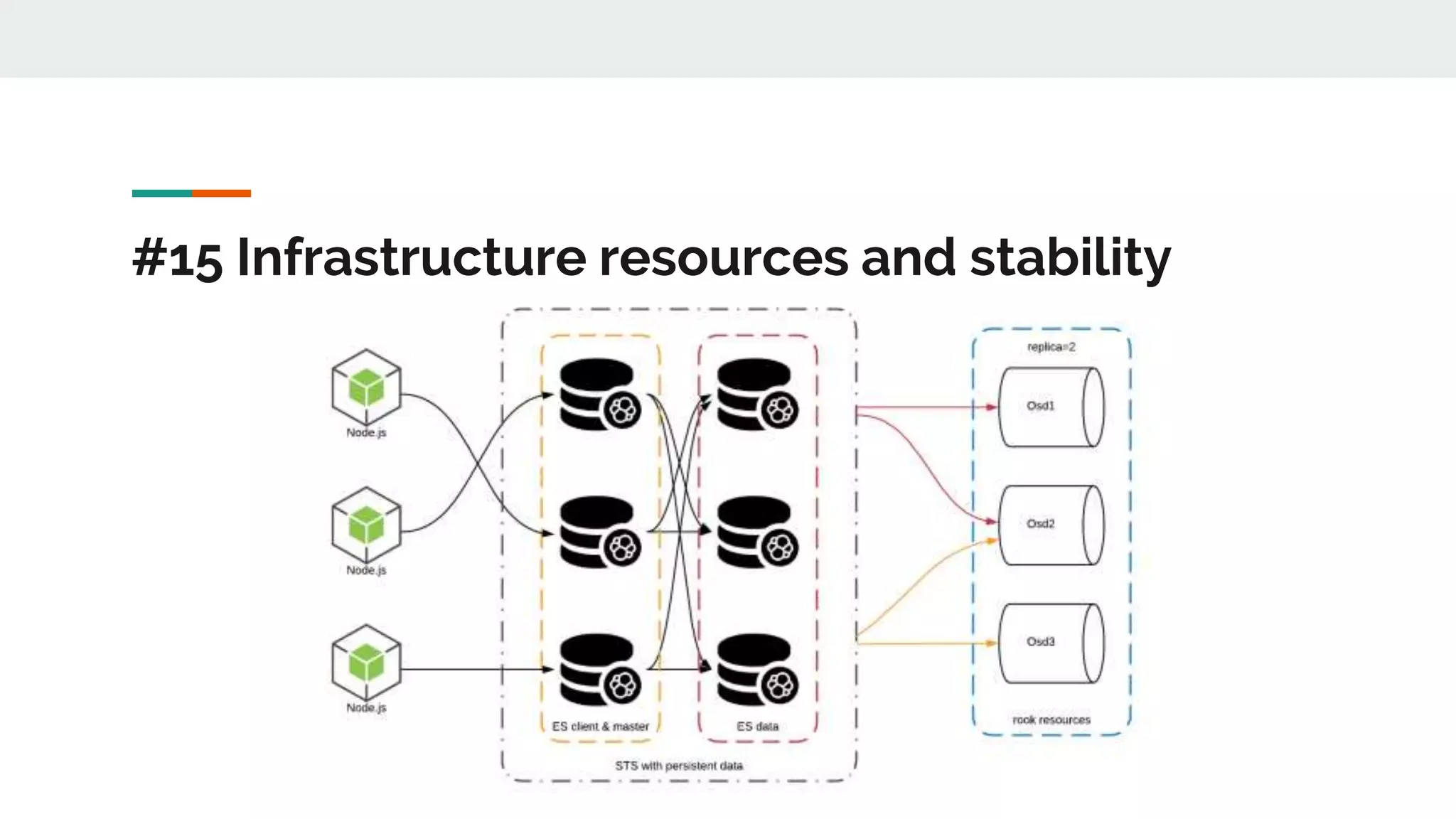
This document discusses Novomatic Technologies Poland's adoption of container orchestration using Kubernetes. It provides background on Novomatic, explains why containers and Kubernetes were adopted, and summarizes the evolution of Kubernetes usage at Novomatic over time. Key points discussed include setting up development environments with Kubernetes, requirements for a PaaS platform, and lessons learned along the way in areas like infrastructure resources, application deployment, telemetry, and managing stateful applications.






![#2.1 Kubernetes as a PaaS core
Platform [1]:
- Distribution (55)
- Hosted (34)
- Installer (18)
Others:
- Application definition
& Image Build [2]
- Service Proxy [3]
- Service Mesh [4]
- Network [5]
- Security [6]
- Observability [7]
- Storage [8]
1 7
2
3 4
5
6
8](https://image.slidesharecdn.com/containerorchestrationandmicroservicesworld-190619062356/75/Container-orchestration-and-microservices-world-14-2048.jpg)
![#4 Etcd - replication and consistency
Problems:
● Etcd size sometimes starts growing and grows … [#8009]
● Network glitch reducing etcd cluster availability seriously [#7321]
● Test clientv3 balancer under network partitions, other failures [#8711]
@jevans](https://image.slidesharecdn.com/containerorchestrationandmicroservicesworld-190619062356/75/Container-orchestration-and-microservices-world-16-2048.jpg)
![#5 Kubernetes API
● CoreDNS crash when API server down [#2629]
● CVE-2018-1002105 [#71411]
● When API server down operators and some sidecars /init containers could crash (always HA)
● Kubernetes scheduler and controller crash when they are connected to localhost [#22846 and
#77764 ]
@jevans](https://image.slidesharecdn.com/containerorchestrationandmicroservicesworld-190619062356/75/Container-orchestration-and-microservices-world-17-2048.jpg)
![#7 Enforcing default limits for containers
>Ja [2:20 PM]
ale widze ostatnio masz twardą rękę do podziałów zasobów po zespołach :)
ja mysle ze w tym tygodniu poprawie te limity i konfiguracje
….
bo mi trochę głupio, że z prostymi problemami się borykamy:
>Kolega XYZ [3:23 PM]
moja babcia zawsze mówiła, że głupio to jest kraść](https://image.slidesharecdn.com/containerorchestrationandmicroservicesworld-190619062356/75/Container-orchestration-and-microservices-world-19-2048.jpg)
![#10 Persistence volumes and k8s on-premise
● NFS - replication is tricky
● Rook operator [ceph or edgeFS] - complex
● Local volume still in Beta https://kubernetes.io/blog/2018/04/13/local-persistent-volumes-beta/
● Expanding Persistent Volumes Claims still in beta
● Flexvolume and CSI driver](https://image.slidesharecdn.com/containerorchestrationandmicroservicesworld-190619062356/75/Container-orchestration-and-microservices-world-22-2048.jpg)



![#1 Application deployment
Happy helming:
● The syntax in hard, especially when you start.
● Secret storing required extra plugin. [helm-secrets]
● Umbrella charts are always tricky. [#4490]
● Helm upgrade failed when new objects added [#4871]
● Tiller and RBAC [Tiller was removed from Helm3, discussion here #1918]](https://image.slidesharecdn.com/containerorchestrationandmicroservicesworld-190619062356/75/Container-orchestration-and-microservices-world-29-2048.jpg)






















![[20200720]cloud native develoment - Nelson Lin](https://cdn.slidesharecdn.com/ss_thumbnails/20200720cloudnativedeveloment-200824031228-thumbnail.jpg?width=640&height=640&fit=bounds)















































