Download as PDF, PPTX










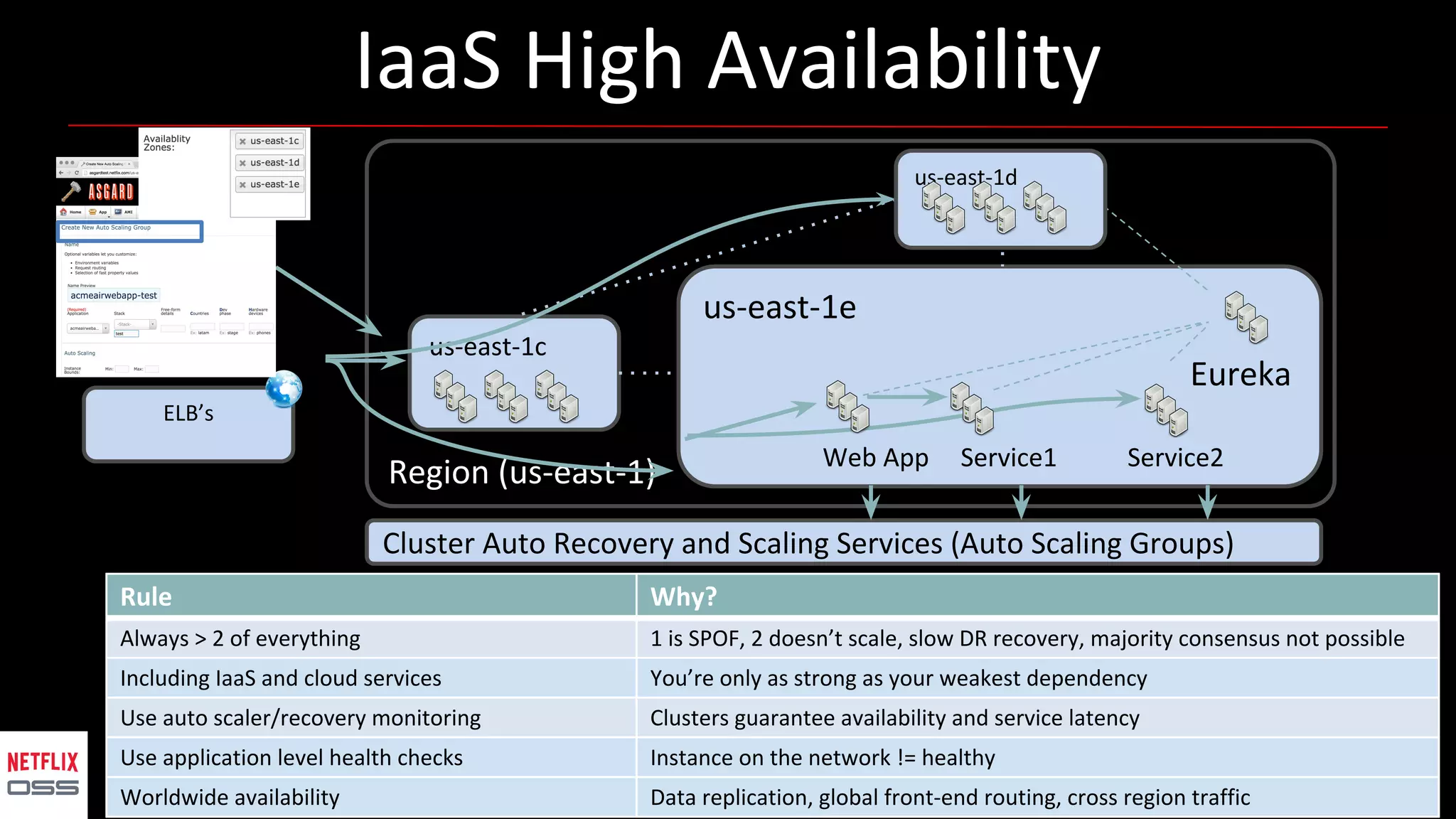
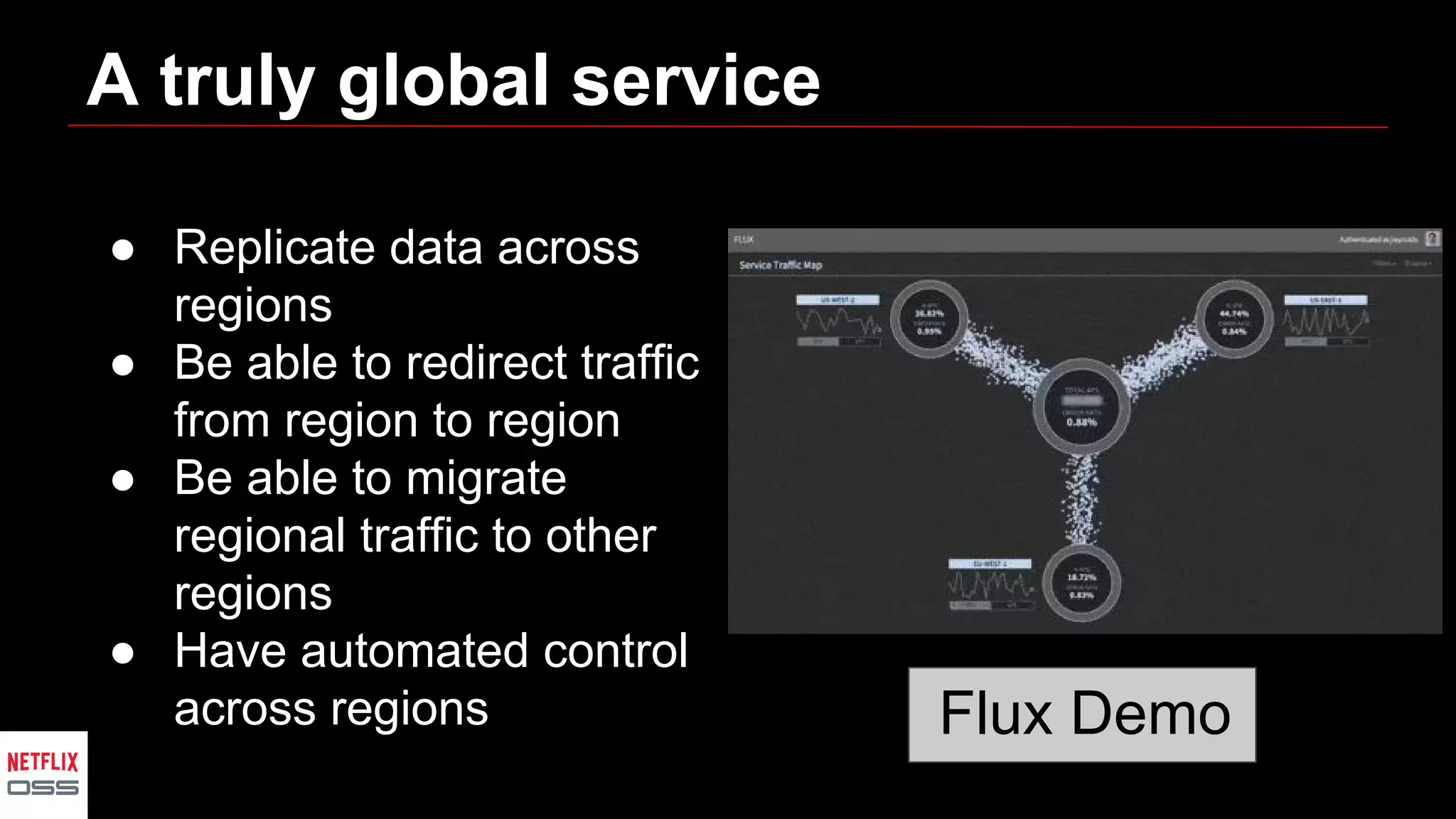


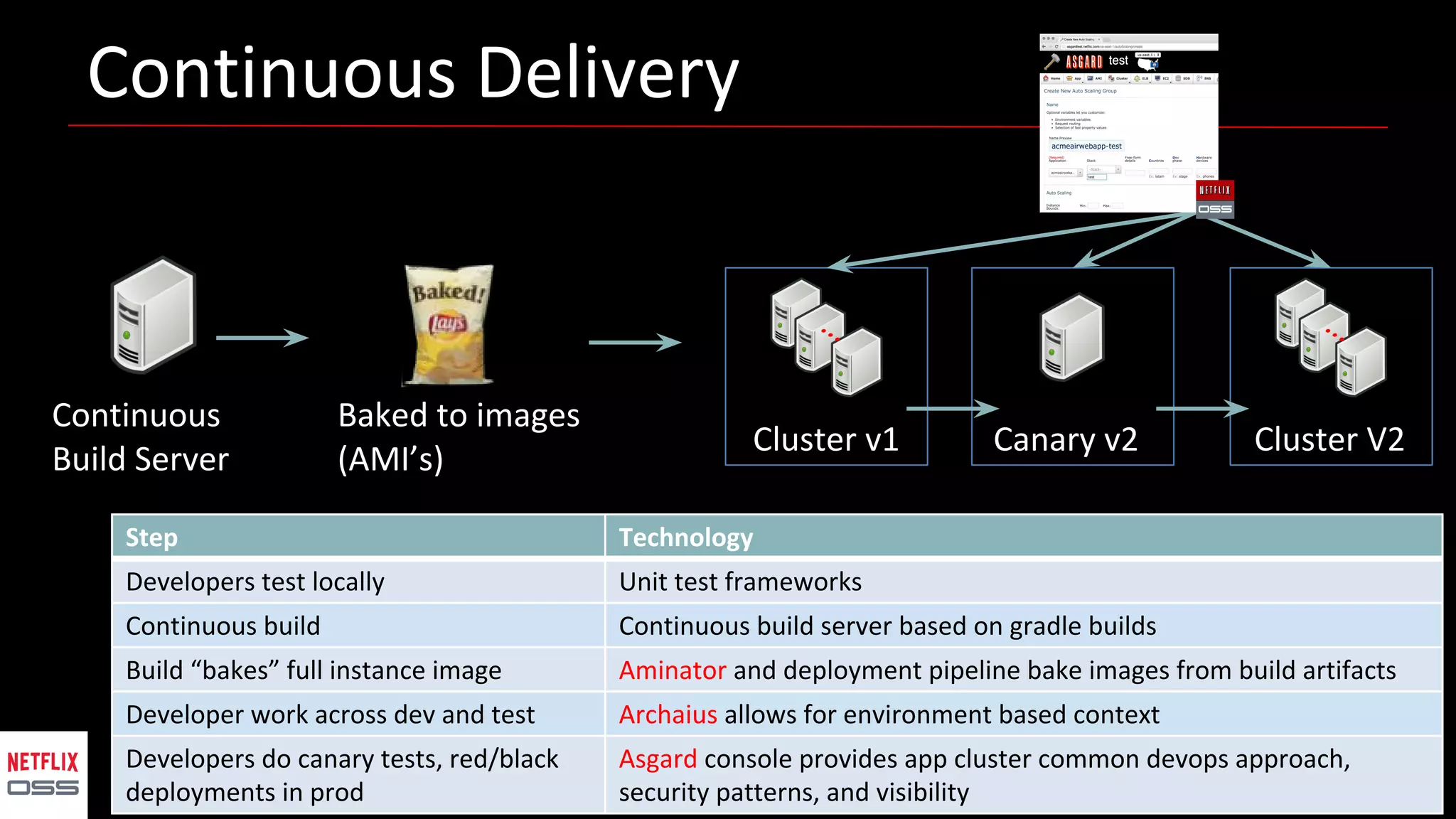

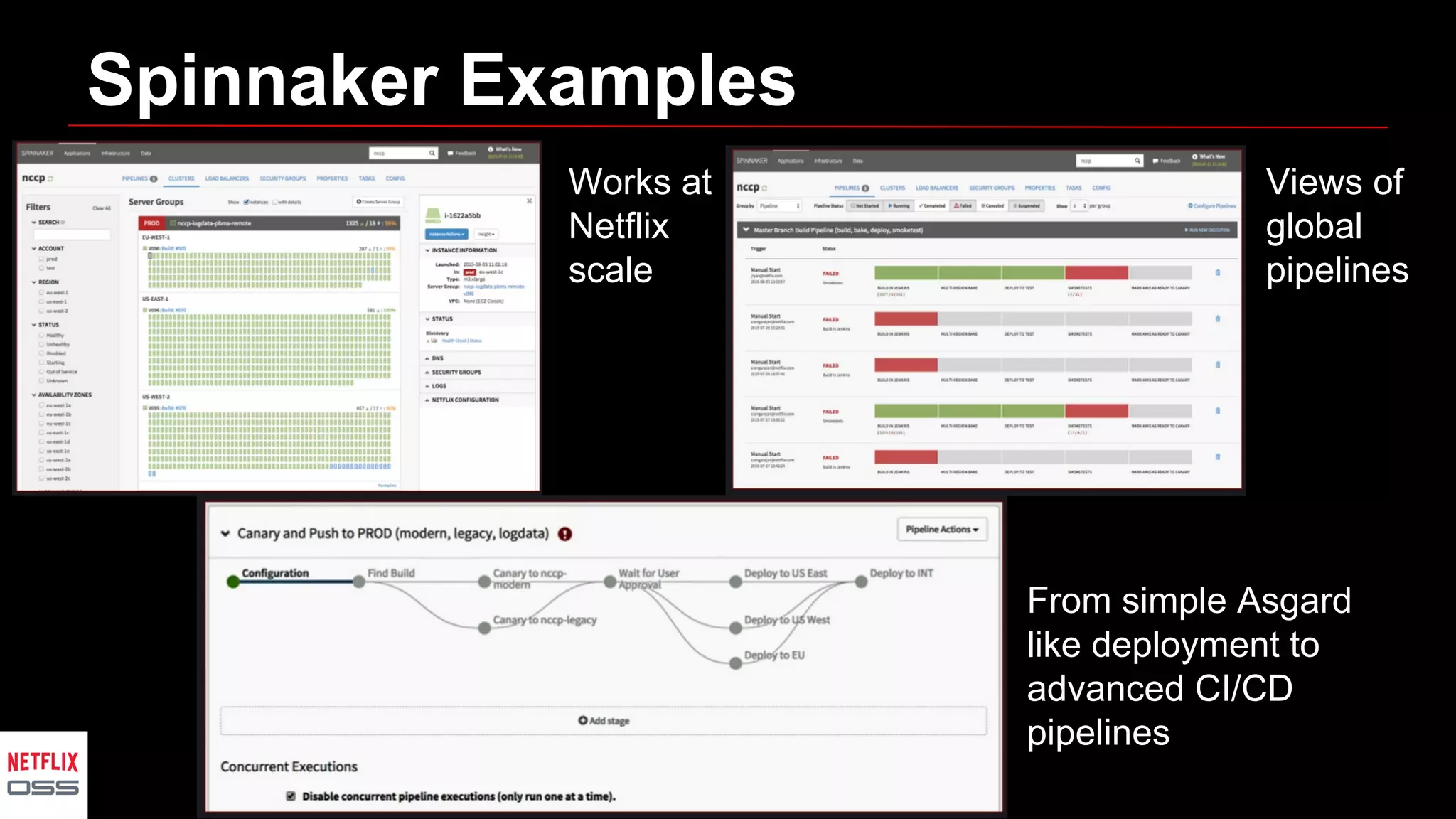

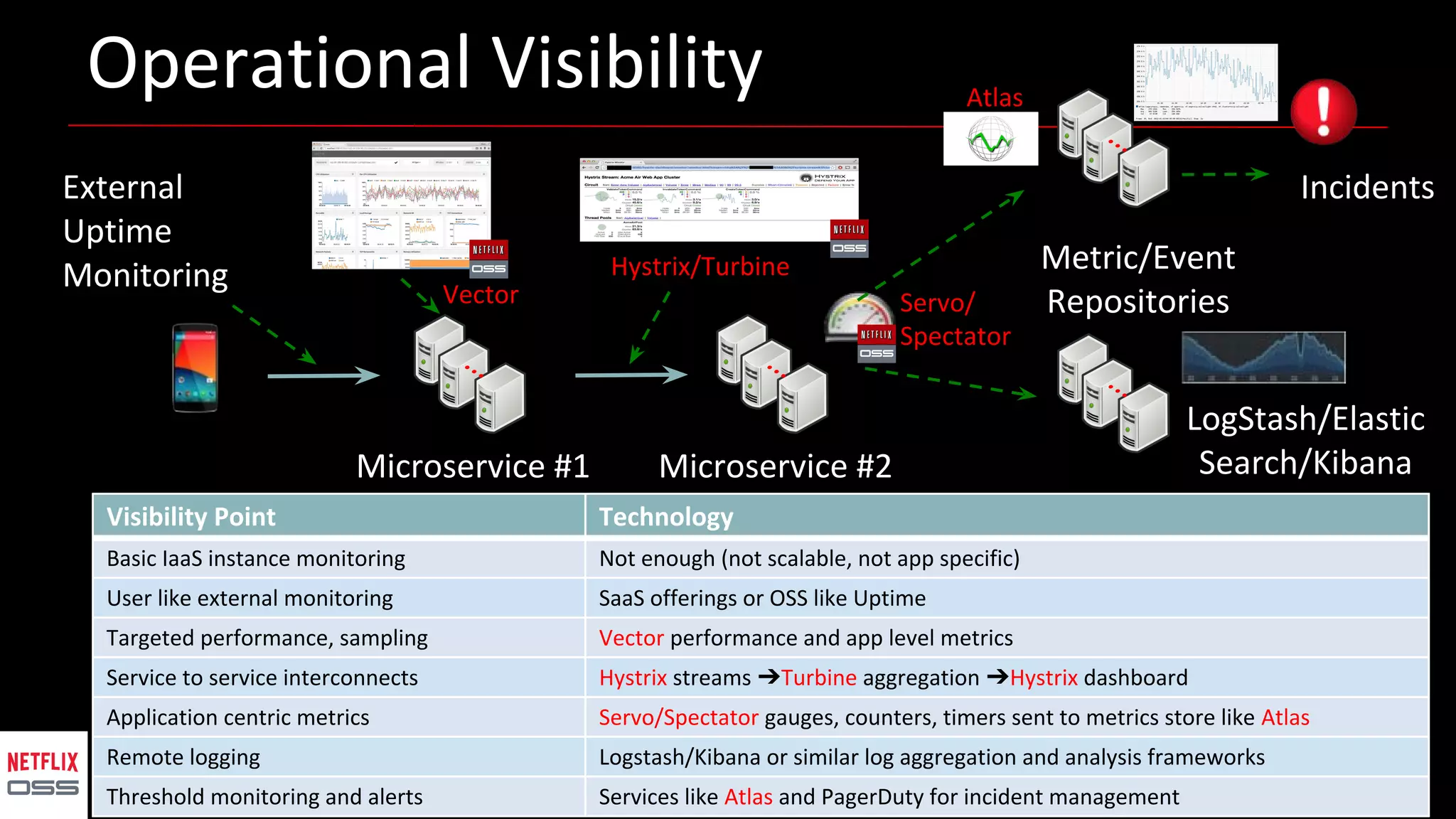
















Andrew Spyker's presentation discusses Netflix's open source initiatives, detailing the architecture, performance improvements, and cloud infrastructure that support its massive scale. The talk emphasizes the culture of collaboration and the use of proven external open source technologies, as well as the development of tools like Spinnaker for CI/CD processes. Additionally, Spyker highlights ongoing projects and the importance of operational visibility and automated performance measurement in enhancing Netflix's technical capabilities.









































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










