



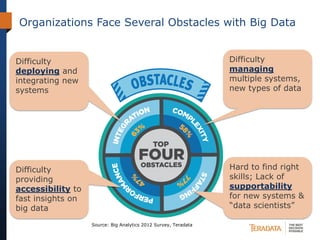
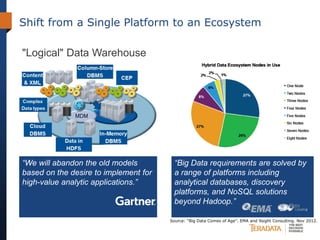
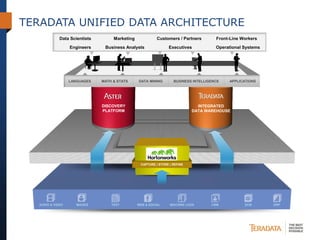

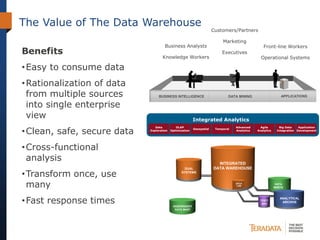


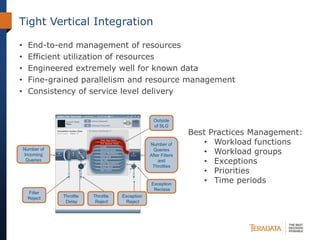
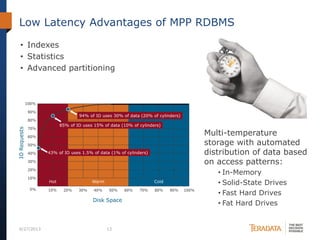





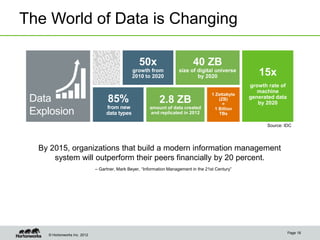
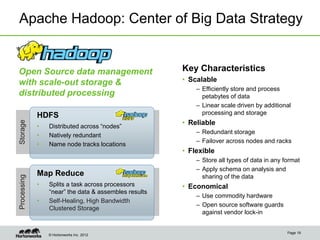

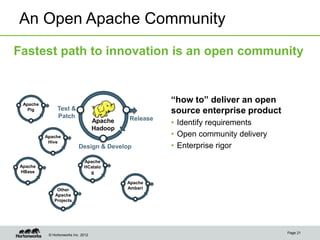
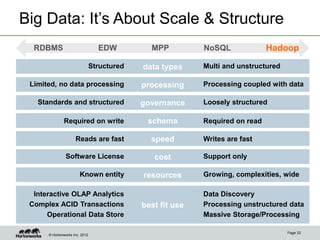
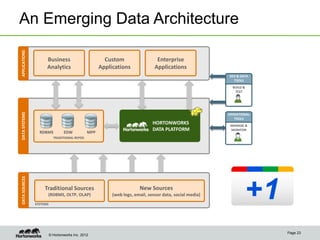
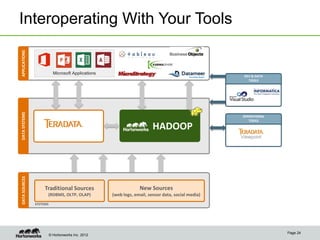
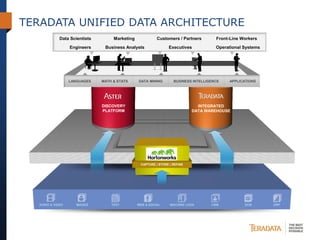


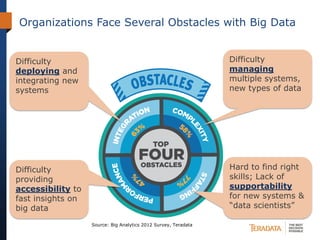

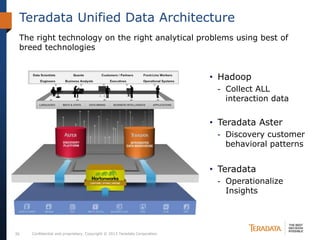
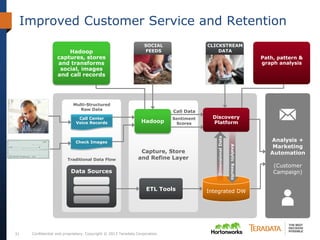

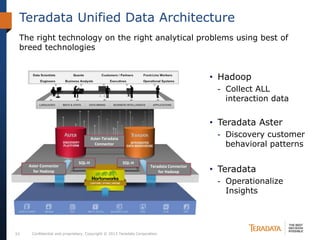
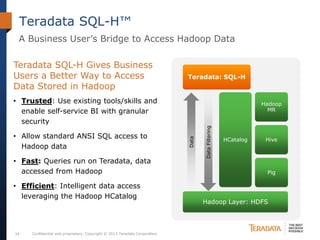
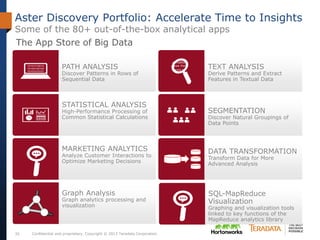

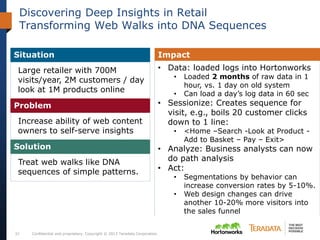





The document discusses the evolving landscape of enterprise data architectures, comparing the functions and values of integrated data warehouses and Hadoop. It highlights challenges organizations face in managing big data, the benefits of different platforms for various analytical needs, and predicts that by 2015, a significant portion of data will be processed through Hadoop. Additionally, it emphasizes the importance of leveraging the right technology for appropriate analytical problems to improve operational efficiency and customer insights.





































![[RakutenTechConf2013] [B-3_2] DWH/Hadoop in Rakuten Ichiba](https://cdn.slidesharecdn.com/ss_thumbnails/techconf2013b3-2-131119004921-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



































































