


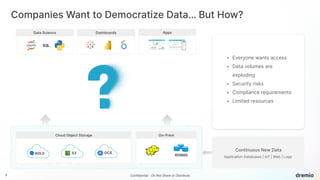
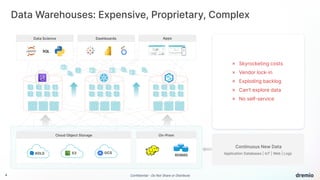
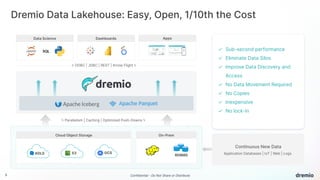
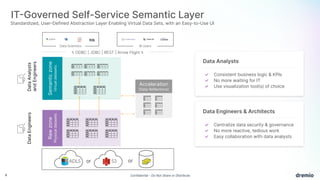

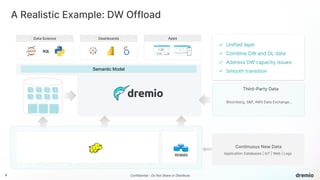
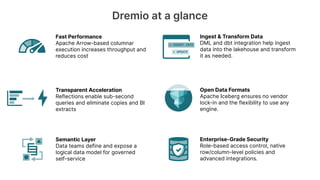



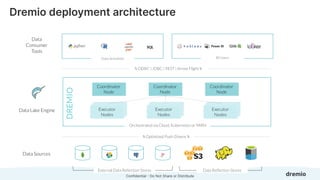
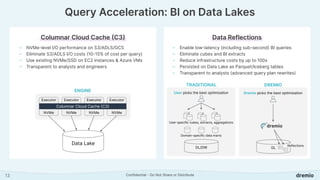
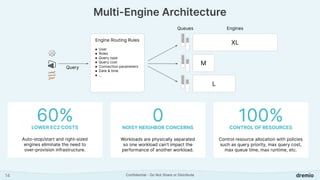
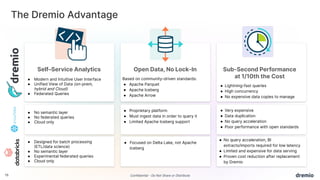

Dremio is an open data lakehouse platform that enhances data accessibility and performance while reducing costs, enabling companies to eliminate data silos and improve self-service analytics. It utilizes technologies like Apache Arrow and Iceberg to provide sub-second query performance, and its architecture supports federated queries across various data sources with enterprise-grade security features. Dremio aims to address issues like skyrocketing data warehouse costs, compliance risks, and limited resources so organizations can effectively democratize data access.












![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)



























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)














