Download as PDF, PPTX

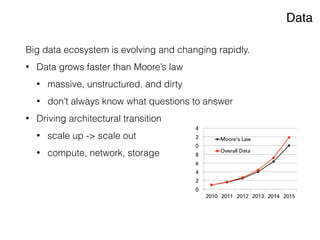

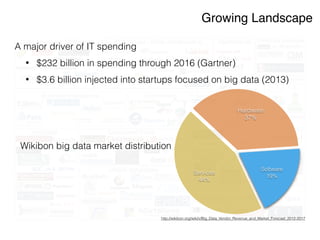



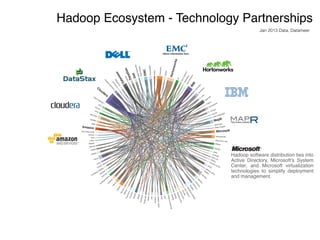

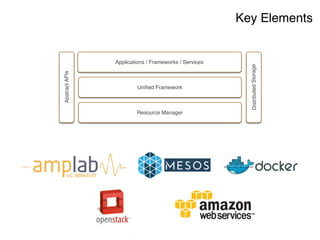
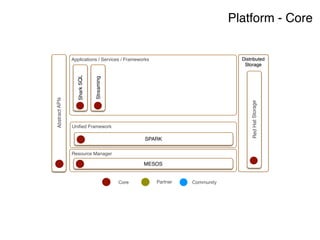
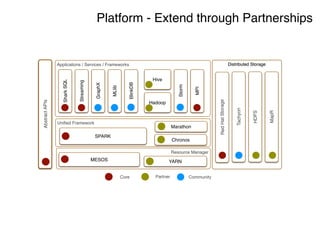


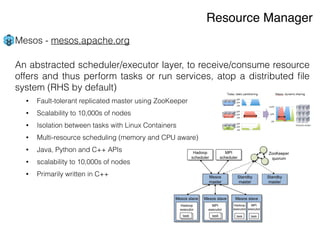
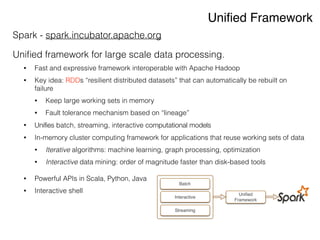
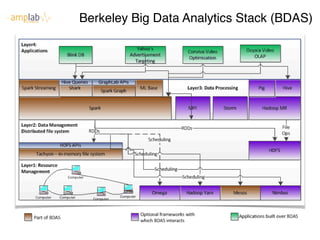

The document discusses the rapidly evolving big data ecosystem, highlighting the challenges of data processing and the architectural transition from scaling up to scaling out. It emphasizes the significant IT spending on big data technologies and the complexities involved in extracting business value from diverse data sources. Key technologies and frameworks, including Hadoop and Spark, are mentioned as vital to managing and processing vast datasets efficiently.



















































![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)




