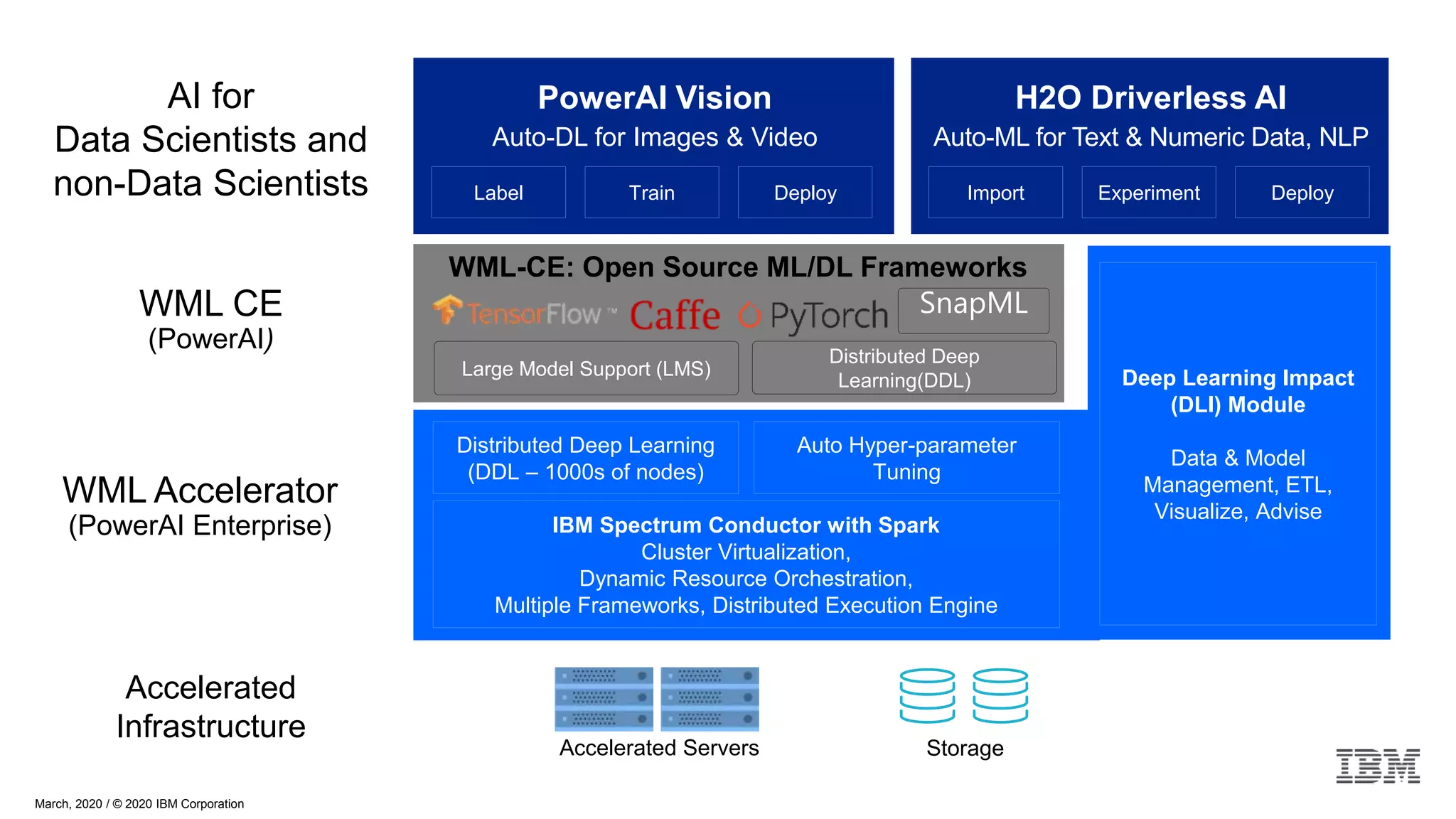
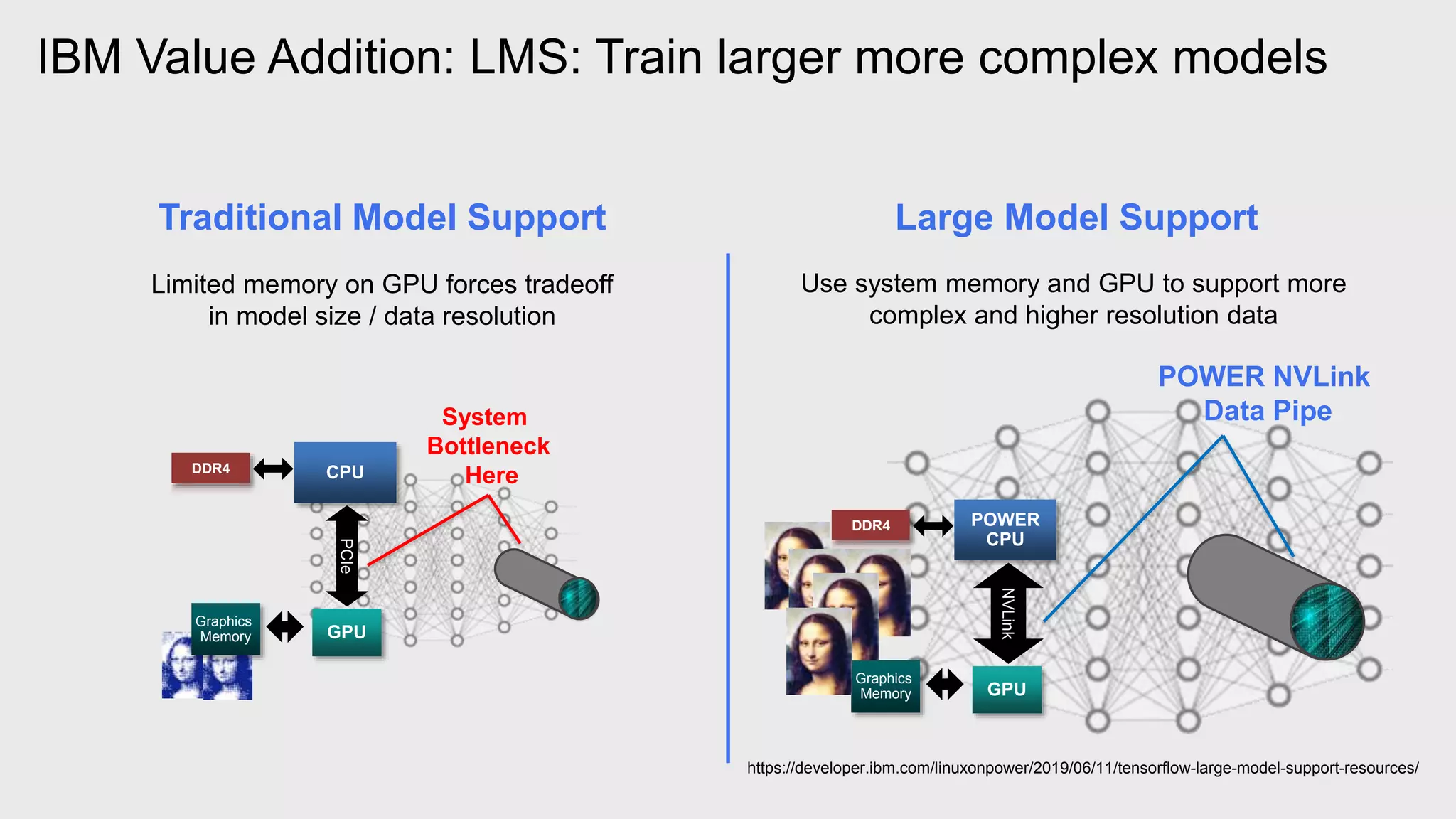
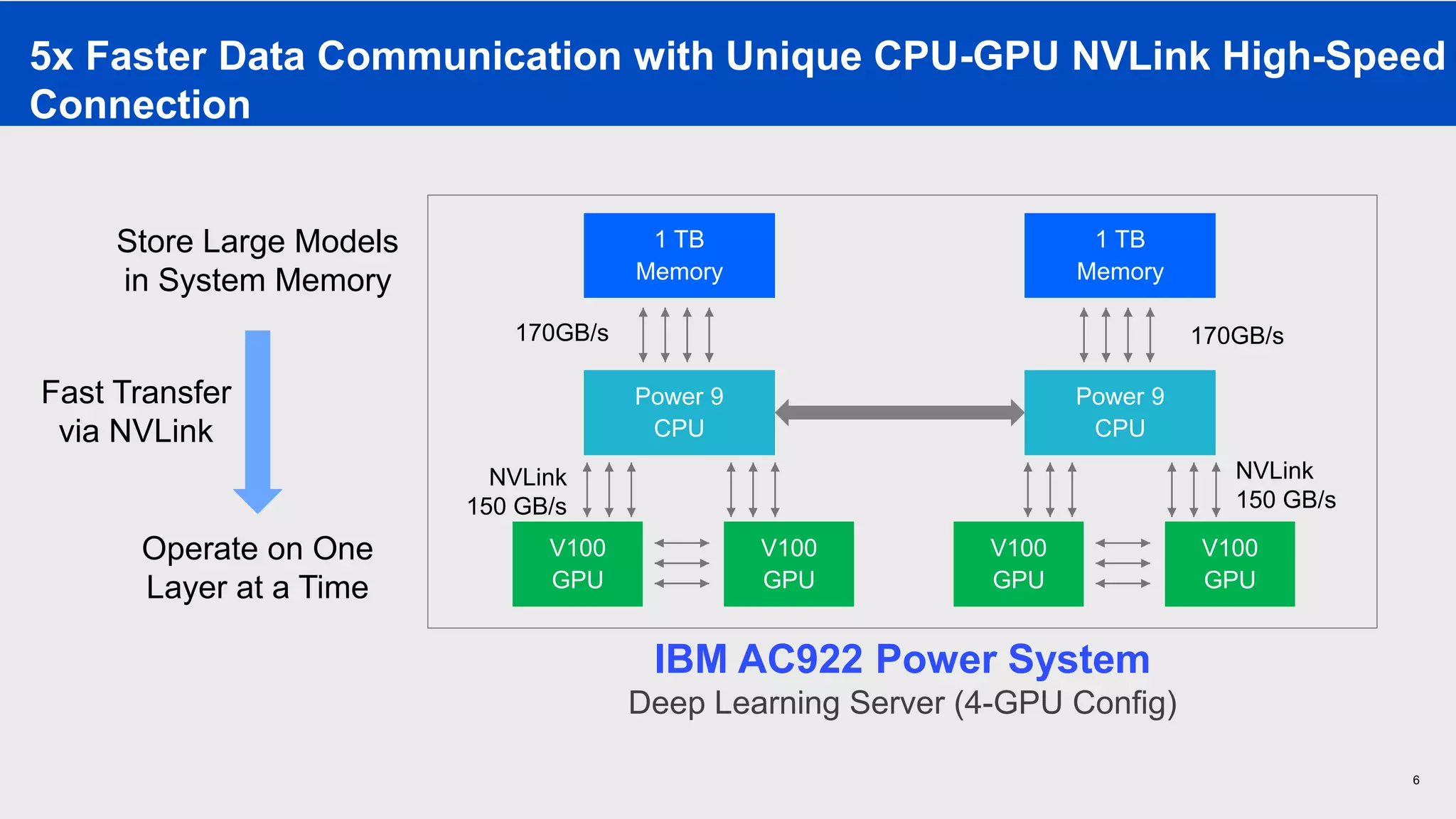
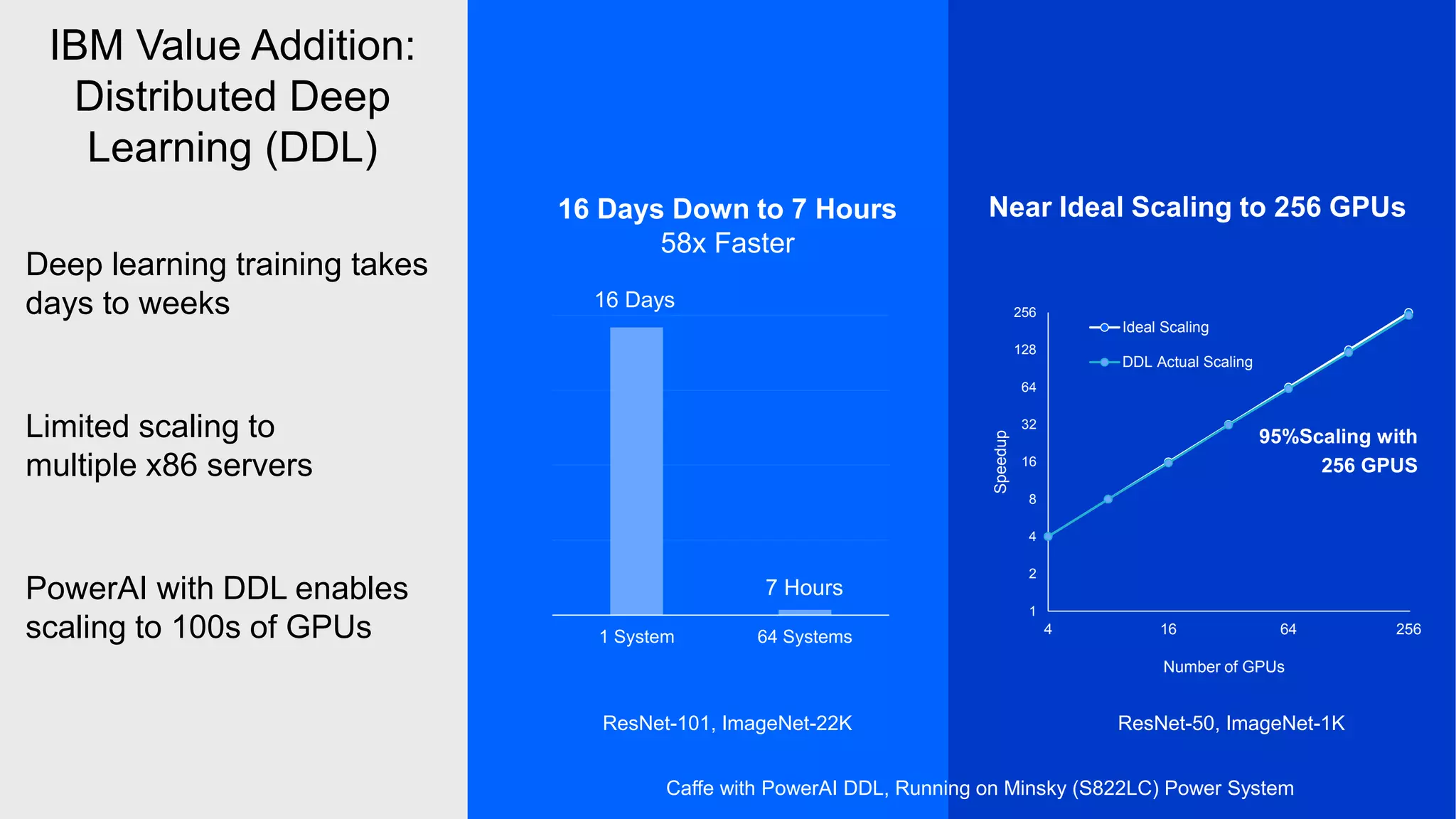
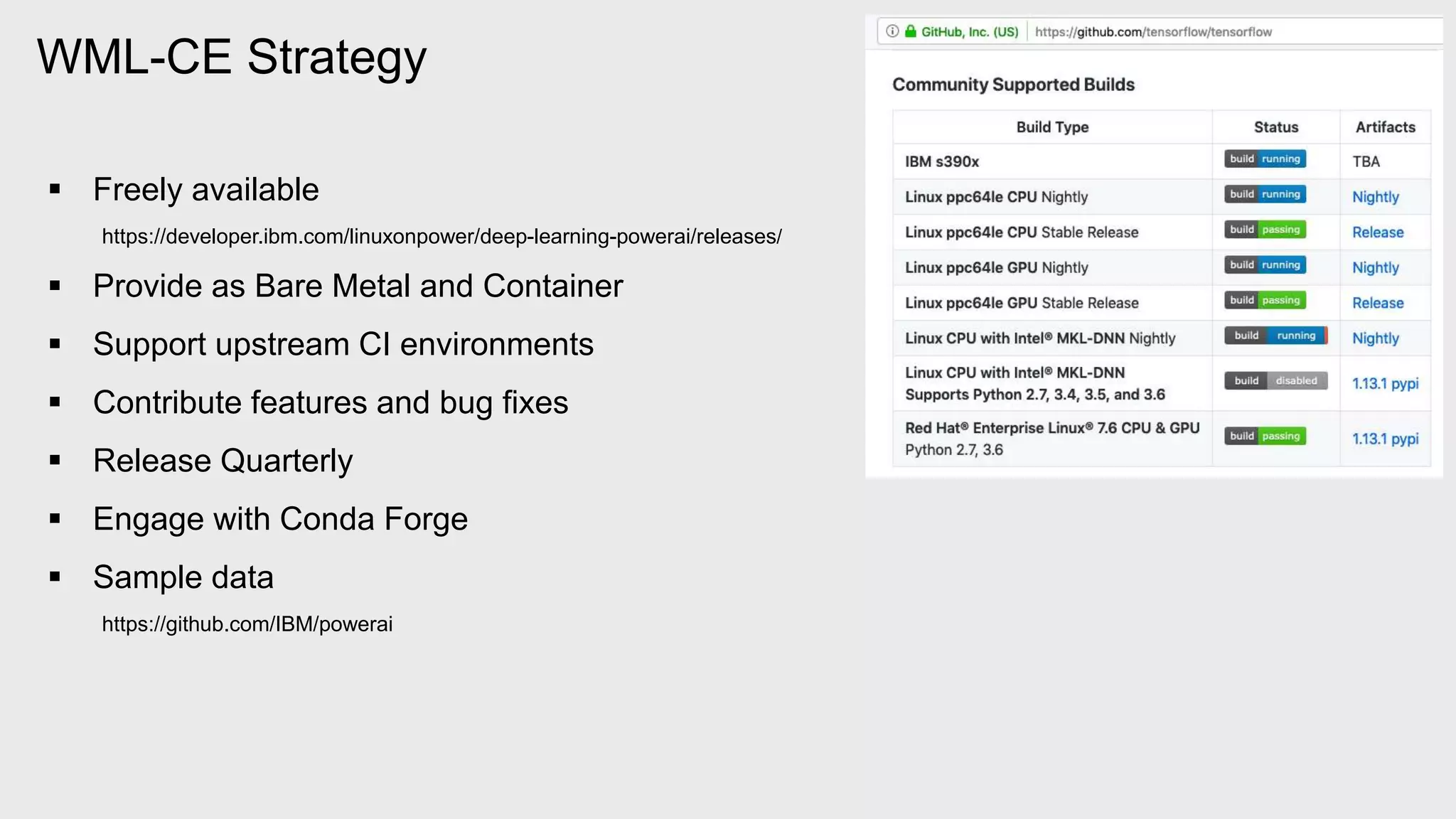
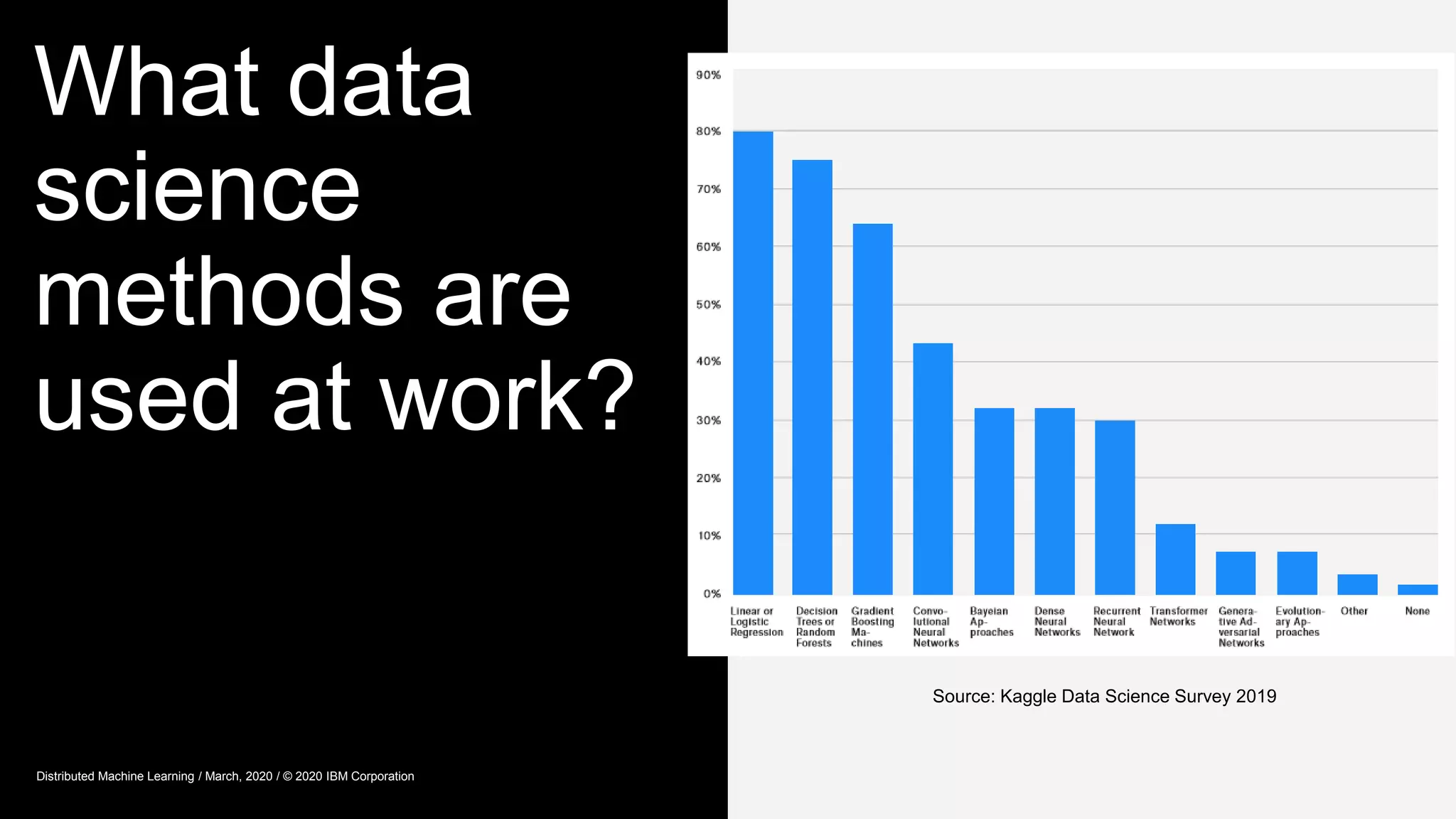
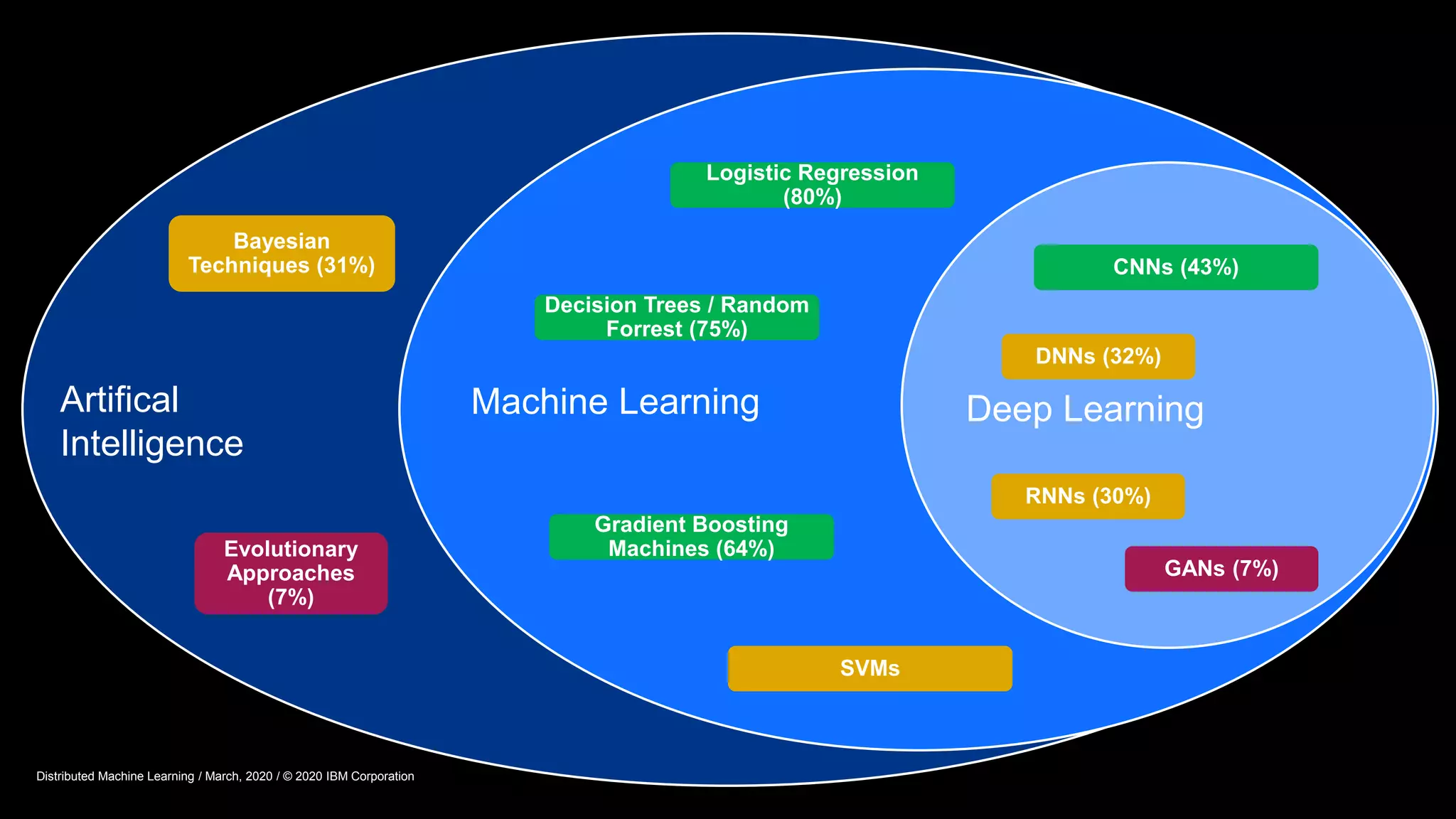
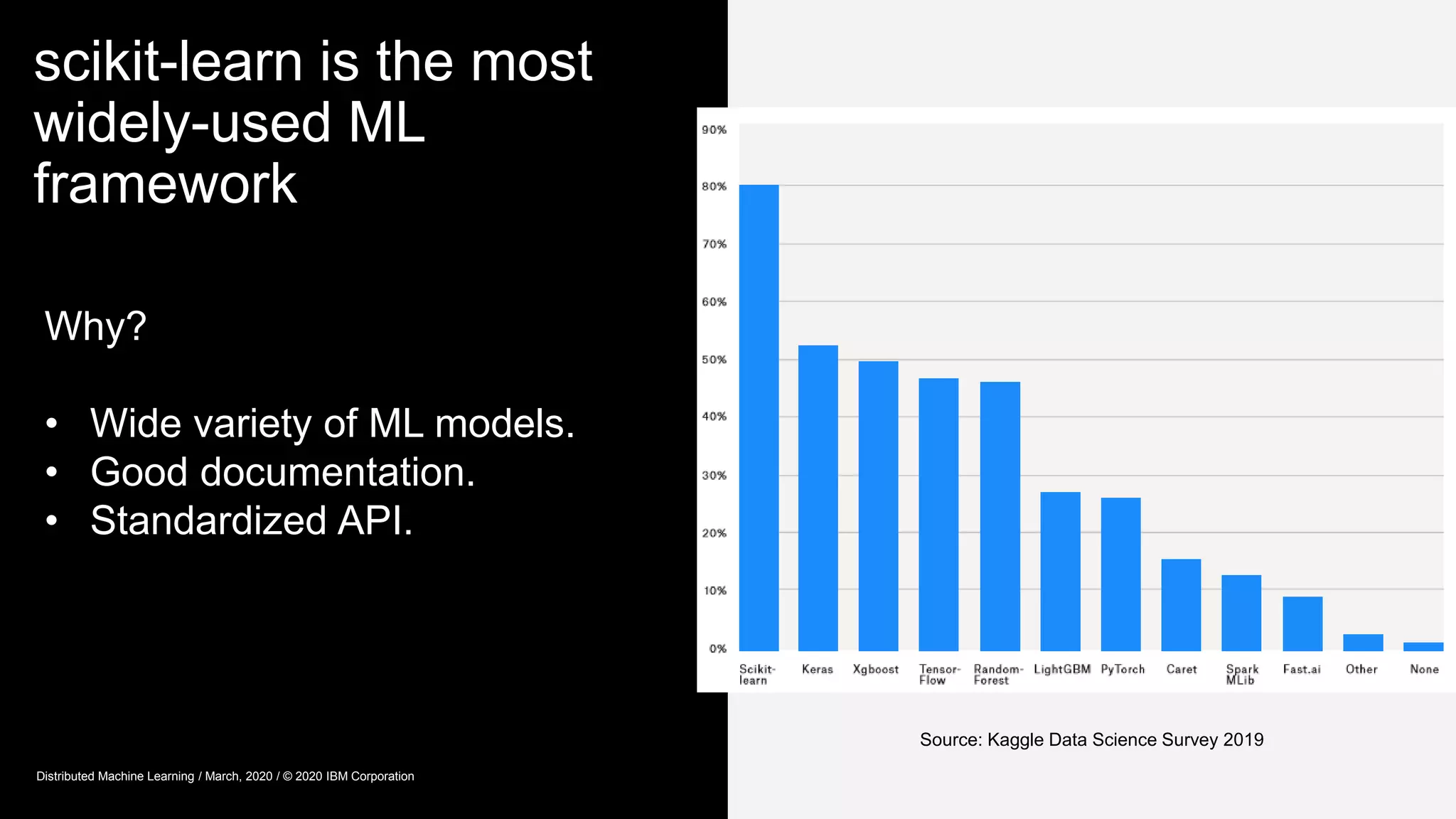
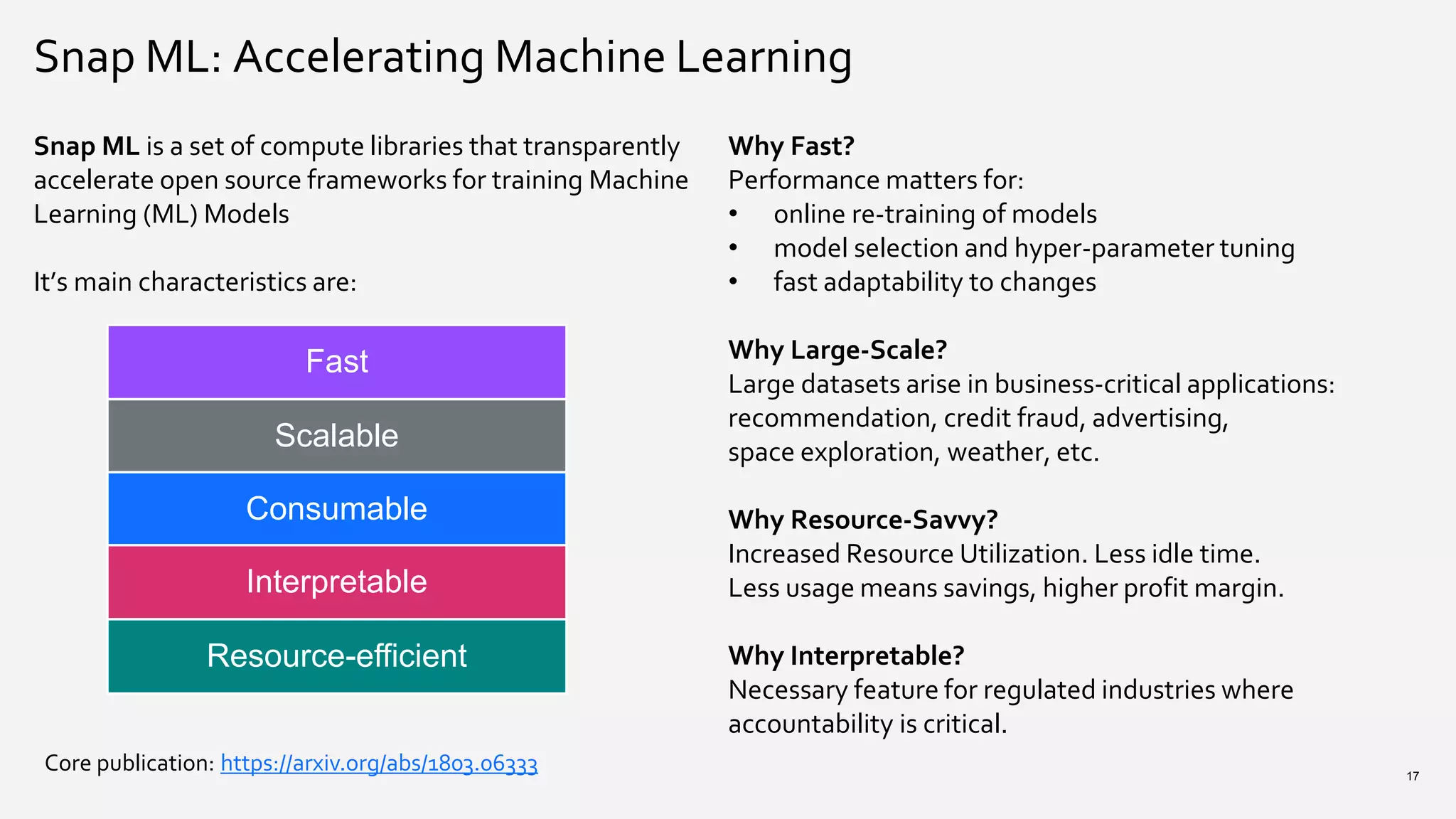
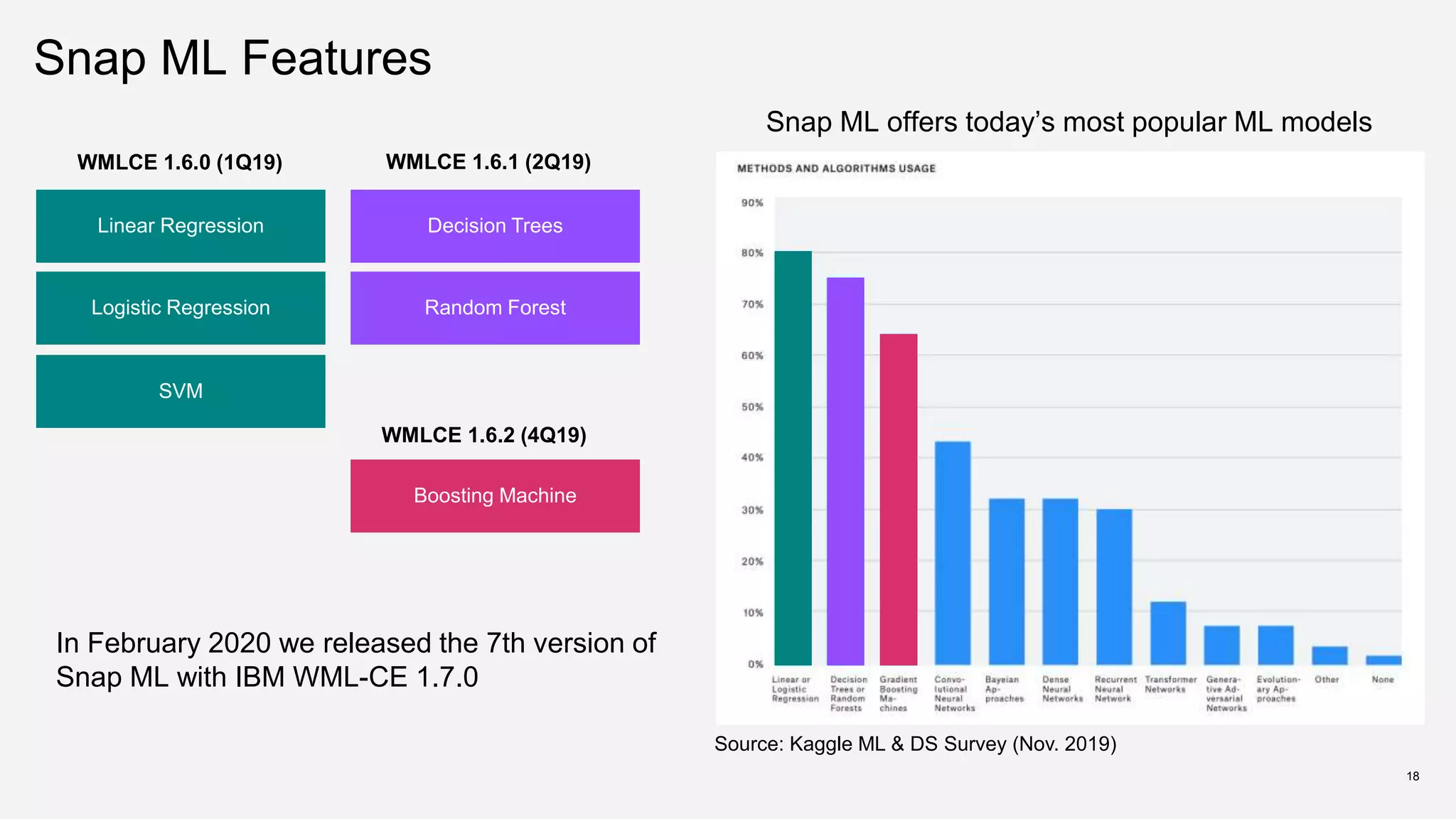
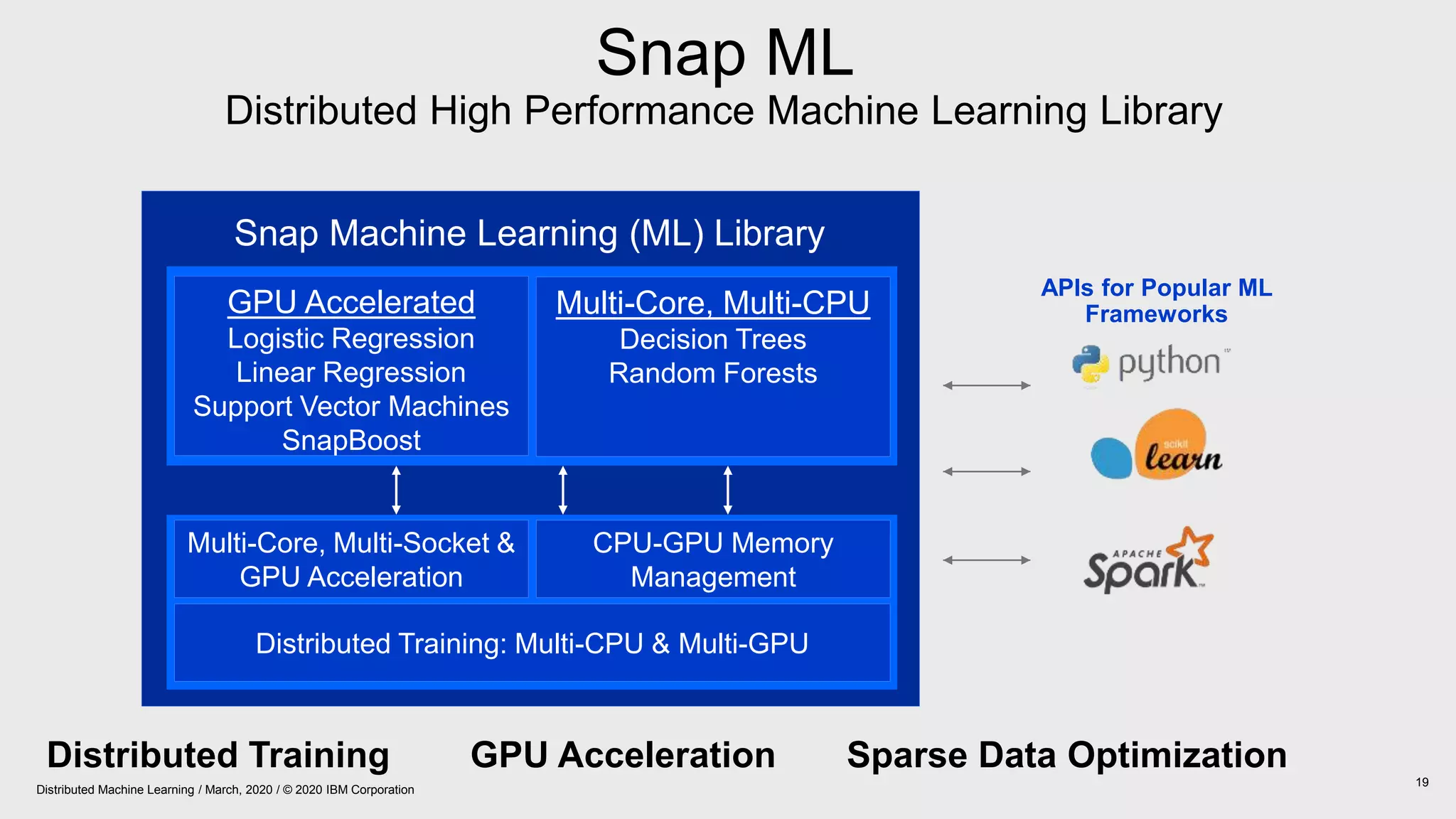
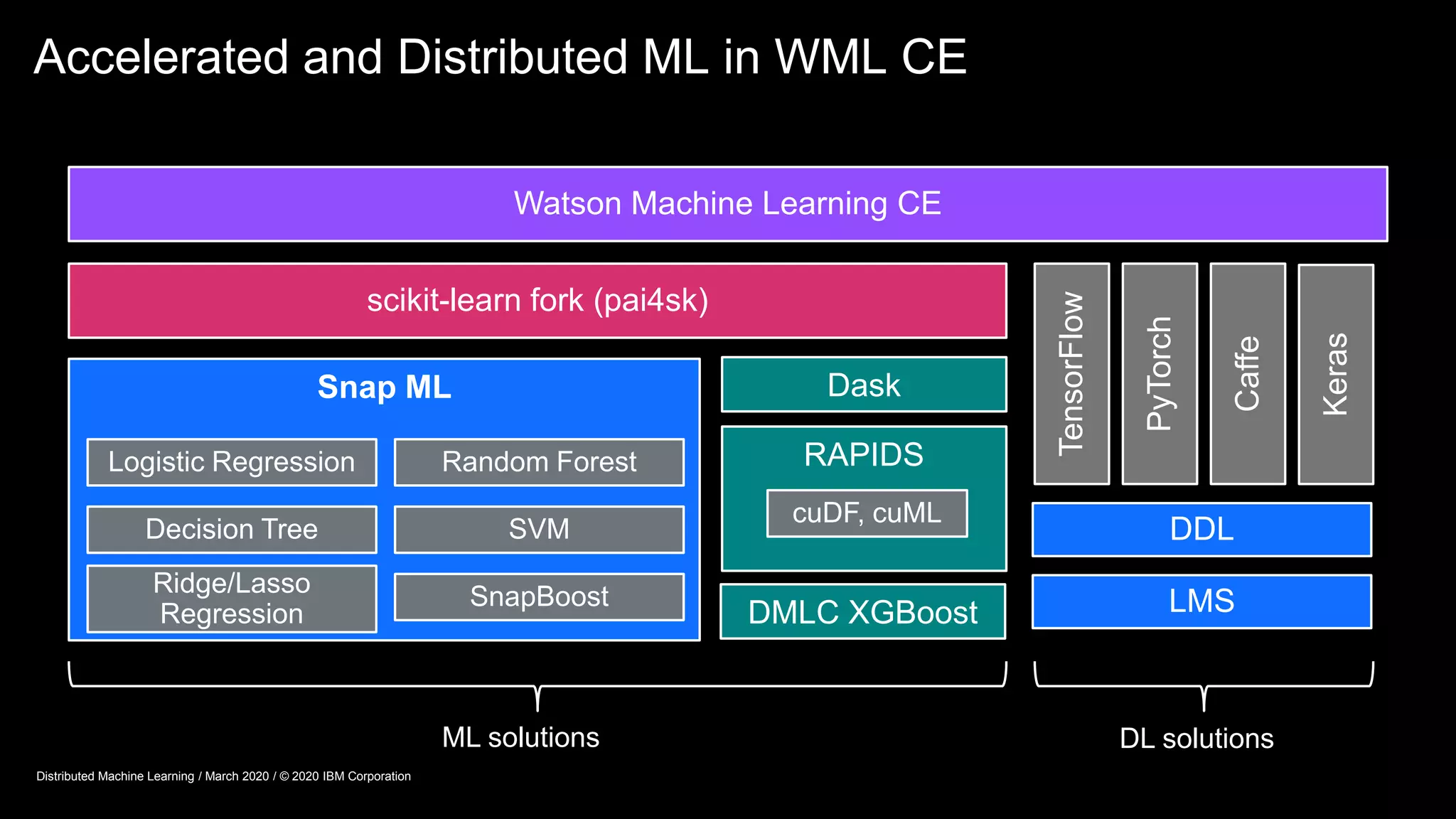
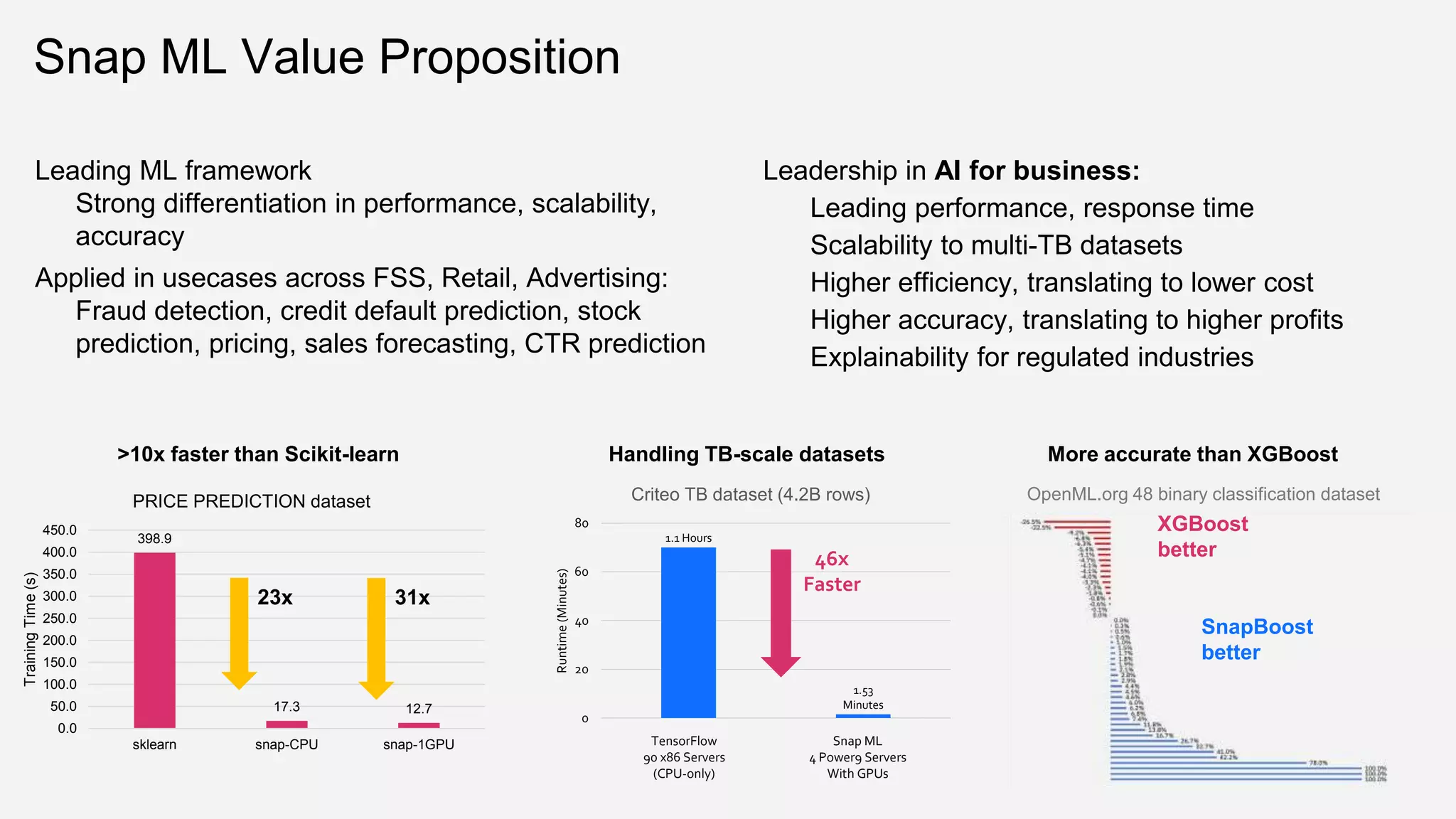
The document provides an overview of Watson Machine Learning Community Edition (WML-CE), an open source machine learning and deep learning platform from IBM. WML-CE includes frameworks like TensorFlow, PyTorch, and Caffe alongside IBM contributions like Large Model Support (LMS), Distributed Deep Learning (DDL), and SnapML. SnapML is a set of libraries that accelerate popular machine learning models across CPU and GPU in a distributed manner. The document highlights key SnapML features and performance advantages over other frameworks.







































![[Giovanni Galloro] How to use machine learning on Google Cloud Platform](https://cdn.slidesharecdn.com/ss_thumbnails/mlcapabilitiesongcp-190115085455-thumbnail.jpg?width=640&height=640&fit=bounds)

























































