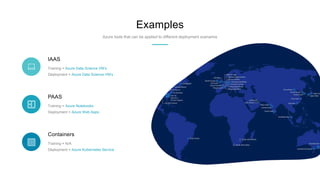
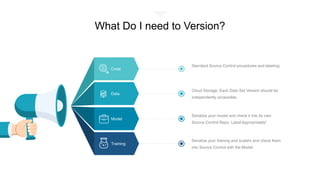
Cameron Vetter, a principal cloud consultant with 20 years of experience in Microsoft technologies, discusses the integration of machine learning into teams and the tools available for developers. He emphasizes the importance of effective versioning, bias management, and leveraging cloud-based solutions for machine learning projects. Vetter recommends starting with prebuilt machine learning services and gradually building in-house capabilities while maintaining a flexible, loosely coupled architecture.