Florin Manaila
HPC/Deep LearningArchitect and Inventor
IBM Cognitive Systems Europe
florin.manaila@de.ibm.com
August 31, 2018
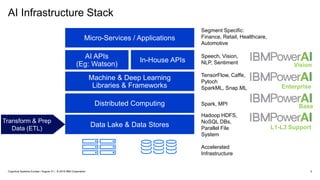
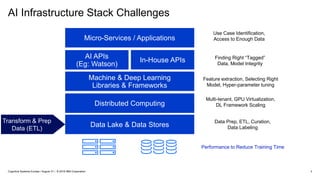
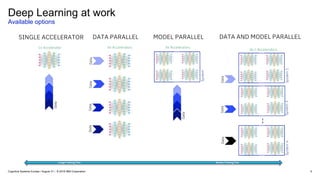
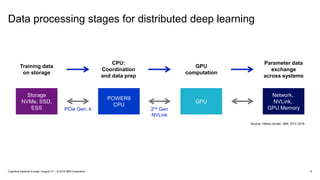
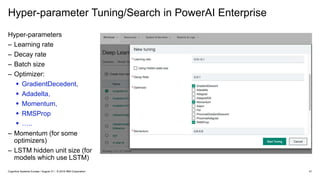
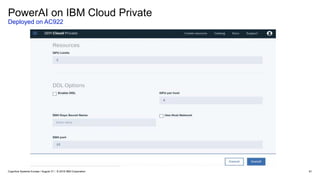
IBM PowerAI Deep Learning Platform
(architecture, hardware roadmap, future innovation)
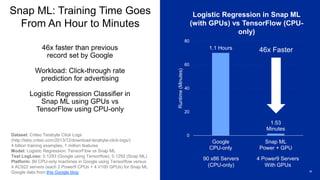
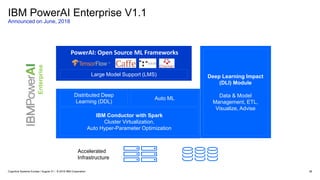
46x faster thanprevious
record set by Google
Workload: Click-through rate
prediction for advertising
Logistic Regression Classifier in
Snap ML using GPUs vs
TensorFlow using CPU-only
35
Snap ML: Training Time Goes
From An Hour to Minutes
Logistic Regression in Snap ML
(with GPUs) vs TensorFlow (CPU-
only)
1.1 Hours
1.53
Minutes
0
20
40
60
80
Google
CPU-only
Snap ML
Power + GPU
Runtime(Minutes)
46x Faster
Dataset: Criteo Terabyte Click Logs
(http://labs.criteo.com/2013/12/download-terabyte-click-logs/)
4 billion training examples, 1 million features
Model: Logistic Regression: TensorFlow vs Snap ML
Test LogLoss: 0.1293 (Google using Tensorflow), 0.1292 (Snap ML)
Platform: 89 CPU-only machines in Google using Tensorflow versus
4 AC922 servers (each 2 Power9 CPUs + 4 V100 GPUs) for Snap ML
Google data from this Google blog
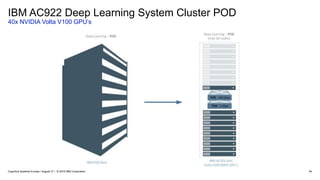
90 x86 Servers
(CPU-only)
4 Power9 Servers
With GPUs
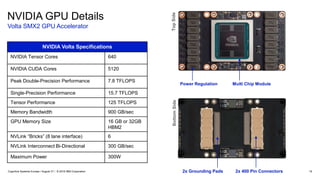
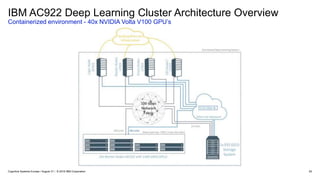
#20 This slide provides a physical view of the GPU.
The top view showing the chip and regulators, and the bottom view showing the 800 pins of interconnect to the backplane.
The upper right picture is a completed assembly with the heat sink assembly added. The heat is sink is required to cool the 300 Watts of power in an air cooled machine.
#23 The IBM AC922 has a new Board Management Controller (BMC) interface called OpenBMC. Open BMC is a free open source management software Linux distribution of which IBM is a community leader … and gaining attention from users all over the marketplace. Quite simply, OpenBMC is the code stack used with the AC922 industry standard BMC service processor controller. Think of OpenBMC analogous to the way your car is likely inspected in the shop. It used to be the case where you would bring your car into the shop when you heard a sound, or on some maintenance window. Perhaps a mechanic would shine a light, diagnose, and investigate what was wrong with the car. Today, they simply plug a computer into the car’s port and it tells the mechanic what’s wrong (which begs the question why are they paid so much, but that’s a different conversation).
IPMI SoCs are known as baseboard management controllers (BMCs). The BMC is connected to most of the standard buses on the motherboard, so it can monitor temperature and fan sensors, storage devices and expansion cards, and even access the network (through its own virtual network interface that includes a separate MAC address). But BMCs almost invariably ship with a proprietary IPMI implementation which is limited in functionality to what the vendor chooses. Furthermore, IPMI is riddled with poor security and, thus, leaves servers vulnerable to all sorts of attacks. Once the BMC has been compromised, the attacker has direct access to essentially every part of the server.
One of the major reasons why the marketplace is enthused about OpenBMC is because of issues associated with the Intelligent Platform Management Interface (IPMI) – a set of system-management-and-monitoring APIs typically implemented on server motherboards via an embedded system-on-chip (SoC) that functions completely outside of the host system's BIOS and operating system. While IPMI is intended as a convenience for those who must manage dozens or hundreds of servers in a remote facility, IPMI has been called out for its potential as a serious hole in server security.
IBM pulled the OpenBMC project into a Design Thinking workshop and facilitated a group of external clients and contributors who helped enable the interface’s look and feel. When this was sent out for a broader set of reviews and followed up with the Net Promoter Score (NPS) questionnaire, it received a preliminary score of 100!
Learn more about OpenBMC at: https://lwn.net/Articles/683320/.
#25 Roadmap to Containers: NVIDIA frameworks are being delivered via container strategy.
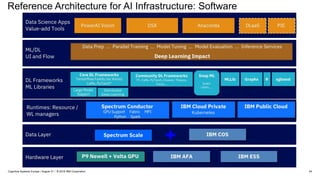
Data Science Apps and Value add tools = AI Vision, PIE, DSX, Anaconda = 28HC
ML/DL UI and Flow.... this row seems to be a double count. Parallel training is DDL. DLI is part of Spectrum CwS integration
DL Frameworks: 30HC
DDL: 11HC
Runtime Resources/WL = ~ Spark, CwC.Cfc = 6HC
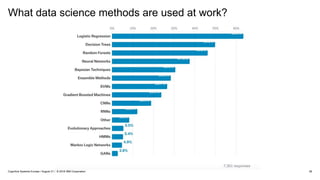
#29 Source: https://www.kaggle.com/surveys/2017
What data science methods are used at work?
Deep Learning is Growing Exponentially, but Machine Learning still has a strong foothold
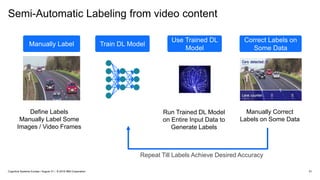
#52 You can use PowerAI Vision for semi-automatic labeling
#53 You can use PowerAI Vision for semi-automatic labeling
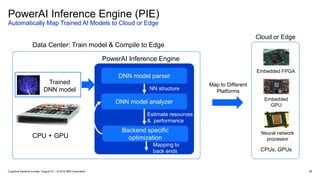
#57 The PowerAI Inference Engine can map trained AI models to all kinds of embedded devices & accelerators
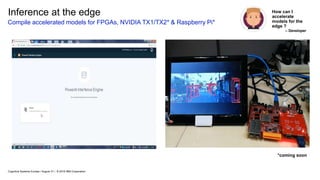
#58 In this demo, the UI on the left is called PowerAI Inference Engine (PIE). It’s a user interface designed for developers to compile compressed versions of trained neural networks. A large neural network needs to be compressed so that it can run with the same accuracy on a less compute intense hardware called FPGA. PIE is available as a prototype for our customers to use.
The video on the right side shows inference of the model once the compressed model is imported. The card in red uses a Xilink ZYNQ series chip which is an FPGA.