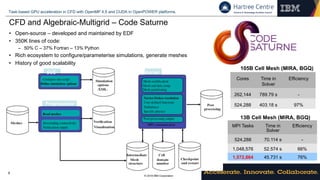
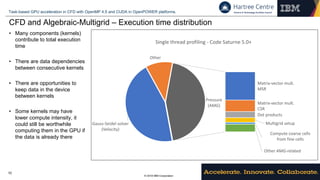
This document discusses using OpenMP 4.5 directives and CUDA to accelerate computational fluid dynamics (CFD) simulations on GPUs using OpenPOWER platforms. It describes porting an open-source CFD code called Code Saturne to leverage GPUs for tasks like linear algebra kernels and algebraic multigrid. It shows how OpenMP 4.5 data environments can be used to manage data movement between the host and device without modifying the code. Profiling results indicate that directive-based programming models can achieve speedups and improve programmer productivity when porting existing CPU codes to accelerate tasks on GPUs.








![© 2018 IBM Corporation
Task-based GPU acceleration in CFD with OpenMP 4.5 and CUDA in OpenPOWER platforms.
12
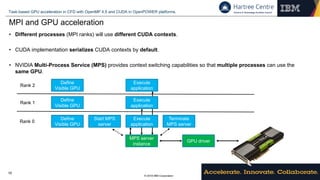
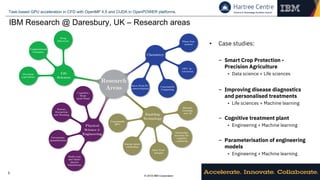
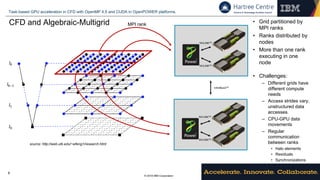
Directive-based programming models
• OpenMP 4.5 data environments – Code Saturne 5.0+ snippet – Conjugate Gradient
IBM Confidential GPU acceleration in Code Saturne
1 static cs_sles_convergence_state_t _conjugate_gradient (/* ... */)
2 {
3 # pragma omp target data if (n_rows > GPU_THRESHOLD )
4 /* Move result vector to device and copied it back at the ned of the scope */
5 map(tofrom:vx[: vx_size ])
6 /* Move right -hand side vector to the device */
7 map(to:rhs [: n_rows ])
8 /* Allocate all auxiliary vectors in the device */
9 map(alloc: _aux_vectors [: tmp_size ])
10 {
11
12 /* Solver code */
13
14 }
15 }
Listing 2: OpenMP 4.5 data environment for a level of the AMG solver.
during the computation of a level so it can be copied to the device at the beginning of the level. The result
vector can also be kept in the device for a significant part of the execution, and only has to be copied to
the host during halo exchange. OpenMP 4.5 makes managing the data according to the aforementioned
observations almost trivial: a single directive su ces to set the scope - see Listing 2. Each time halos
All arrays reside in the device in this scope!
The programming model manages host/device pointers mapping for you!](https://image.slidesharecdn.com/openpowerworkshop-180620084324/85/CFD-on-Power-12-320.jpg)
![© 2018 IBM Corporation
Task-based GPU acceleration in CFD with OpenMP 4.5 and CUDA in OpenPOWER platforms.
13
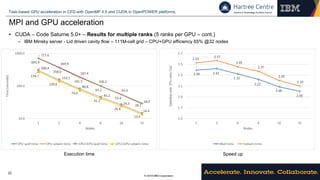
Directive-based programming models
• OpenMP 4.5 target regions – Code Saturne 5.0+ snippet – Dot products
6 vx[ii] += (alpha * dk[ii]);
7 rk[ii] += (alpha * zk[ii]);
8 }
9
10 /* ... */
11 }
12
13 /* ... */
14
15 static void _cs_dot_xx_xy_superblock (cs_lnum_t n,
16 const cs_real_t *restrict x,
17 const cs_real_t *restrict y,
18 double *xx ,
19 double *xy)
20 {
21 double dot_xx = 0.0, dot_xy = 0.0;
22
23 # pragma omp target teams distribute parallel for reduction (+: dot_xx , dot_xy)
24 if ( n > GPU_THRESHOLD )
25 map(to:x[:n],y[:n])
26 map(tofrom:dot_xx , dot_xy)
27 for (cs_lnum_t i = 0; i < n; ++i) {
28 const double tx = x[i];
29 const double ty = y[i];
30 dot_xx += tx*tx;
31 dot_xy += tx*ty;
32 }
33
34 /* ... */
35
36 *xx = dot_xx;
37 *xy = dot_xy;
38 }
Listing 3: Example of GPU port for two stream kernels: vector multiply-and-add and dot product .
…
Host
… … CUDA blocks
OpenMP team
Allocate data
in the the
device.
Host
Release data
in the the
device.
OpenMP
runtime library
OpenMP
runtime library](https://image.slidesharecdn.com/openpowerworkshop-180620084324/85/CFD-on-Power-13-320.jpg)

![© 2018 IBM Corporation
Task-based GPU acceleration in CFD with OpenMP 4.5 and CUDA in OpenPOWER platforms.
15
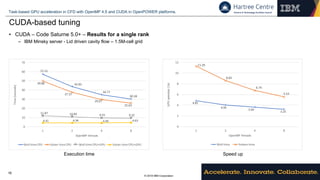
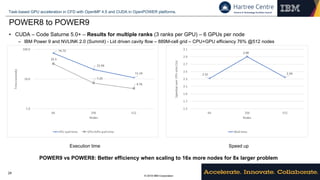
CUDA-based tuning
• Avoid expensive GPU memory allocation/deallocation:
– Allocate a memory chunk once and reuse it
• Use pinned memory for data copied frequently to the
GPU
– Avoid pageable-pinned memory copies by the CUDA
implementation
• Explore asynchronous execution of CUDA API calls
– Start copying data to/from the device while the host is preparing
the next set of data or the next kernel
• Use CUDA constant memory to copy arguments for
multiple kernels at once.
– The latency of copying tens of KB to the GPU is similar to
copy 1B
– Dual-buffering enable copies to happen asynchronously
• Produce specialized kernels instead of relying on runtime
checks.
– CUDA is a C++ extension and therefore kernels and device
functions can be templated.
– Leverage compile-time optimizations for the relevant
sequences of kernels.
– NVCC toolchain does very aggressive inlining.
– Lower register pressure = more occupancy.
IBM Confidential GPU acceleration in Cod
1 template < KernelKinds Kind >
2 __device__ int any_kernel ( KernelArgsBase &Arg , unsigned n_rows_per_block ) {
3 switch(Kind) {
4 /* ... */
5 // Dot product:
6 //
7 case DP_xx:
8 dot_product <Kind >(
9 /* version */ Arg.getArg <cs_lnum_t >(0),
10 /* n_rows */ Arg.getArg <cs_lnum_t >(1),
11 /* x */ Arg.getArg <cs_real_t * >(2),
12 /* y */ nullptr ,
13 /* z */ nullptr ,
14 /* res */ Arg.getArg <cs_real_t * >(3),
15 /* n_rows_per_block */ n_rows_per_block );
16 break;
17 /* ... */
18 }
19 __syncthreads ();
20 return 0;
21 }
22
23 template < KernelKinds ... Kinds >
24 __global__ void any_kernels (void) {
25
26 auto *KA = reinterpret_cast < KernelArgsSeries *>(& KernelArgsSeriesGPU [0]);
27 const unsigned n_rows_per_block = KA -> RowsPerBlock ;
28 unsigned idx = 0;
29
30 int dummy [] = { any_kernel <Kinds >(KA ->Args[idx ++], n_rows_per_block )... };
31 (void) dummy;
32 }
Listing 10: Device entry-point function for kernel execution.](https://image.slidesharecdn.com/openpowerworkshop-180620084324/85/CFD-on-Power-15-320.jpg)