Downloaded 13 times















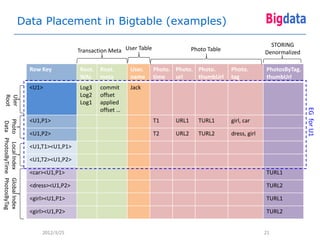
![SQL-Like Schema Language (DDL)
CREATE SCHEMA DemoApp; Additional Qualifiers:
CREATE TABLE User { DESC|ASC|SCATTER
required int64 userId;
required string name; ------------------------------------
} PRIMARY KEY(userId), ENTITY GROUP ROOT; CREATE TABLE Book{
required int64 userId;
CREATE TABLE Photo { required int32 bookId;
required int64 userId;
required int64 time;
required int32 photoId;
required int64 time; required string url;
required string url; repeated string tag;
optional string thumbUrl; } PRIMARY KEY([DESC|ASC|SCATTER] userId,
repeated string tag; [DESC|ASC|SCATTER] bookId),
} PRIMARY KEY(userId, photoId), IN TABLE User,
IN TABLE User, ENTITY GROUP KEY(userId) REFERENCES User;
ENTITY GROUP KEY(userId) REFERENCES User;
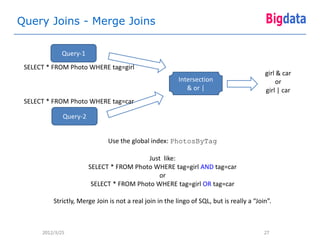
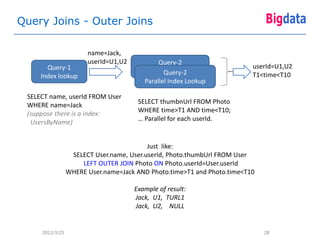
CREATE LOCAL INDEX PhotosByTime CREATE LOCAL INDEX BooksByTime
ON Photo(userId, time); ON Book([DESC|ASC|SCATTER] userId,
[DESC|ASC] time);
CREATE GLOBAL INDEX PhotosByTag
ON Photo(tag) STORING (thumbUrl);
2012/3/25 18](https://image.slidesharecdn.com/learningfromgooglemegastore-20110414c-120325105135-phpapp02/85/Learning-from-google-megastore-Part-1-18-320.jpg)








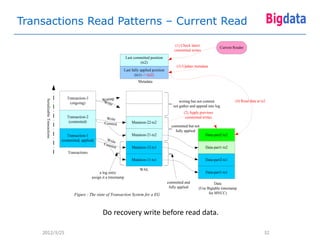
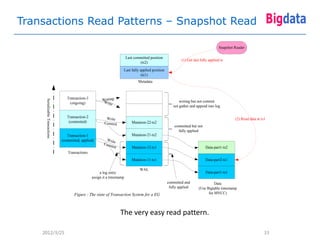
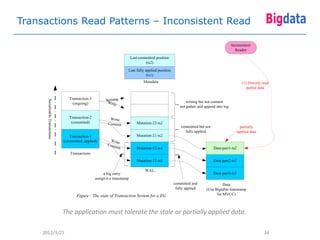
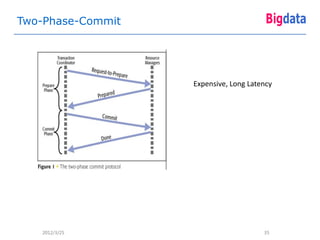







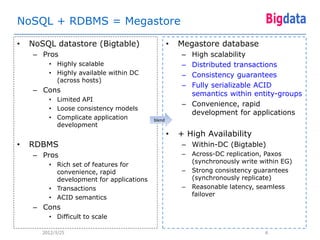
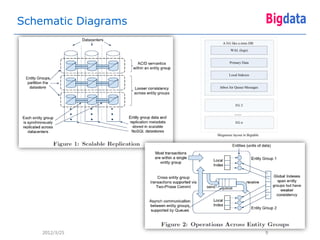
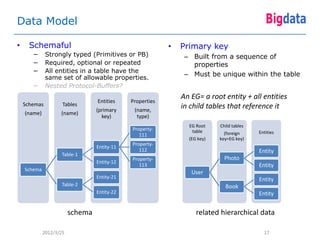
This document provides an overview of Google's Megastore database system. It discusses three key aspects: the data model and schema language for structuring data, transactions for maintaining consistency, and replication across datacenters for high availability. The data model takes a relational approach and uses the concept of entity groups to partition data at a fine-grained level for scalability. Transactions provide ACID semantics within entity groups. Replication uses Paxos consensus for strong consistency across datacenters.




































































































