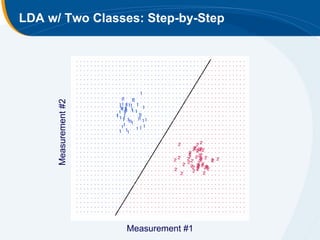
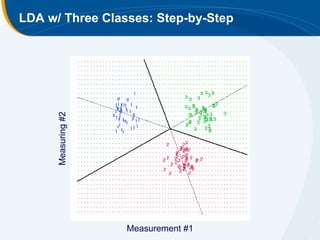
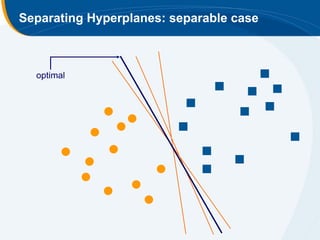
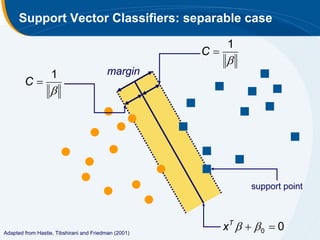
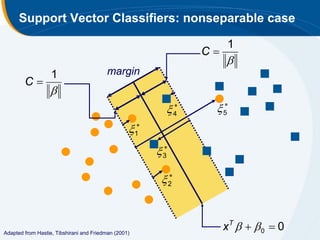
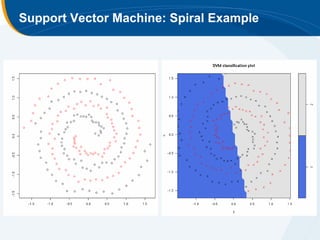
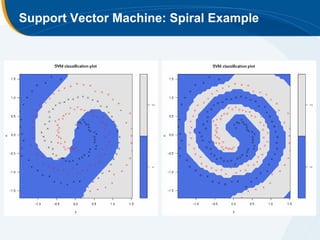
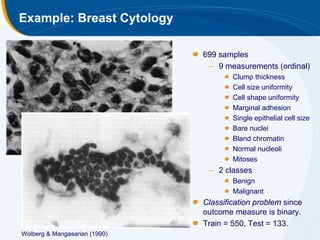
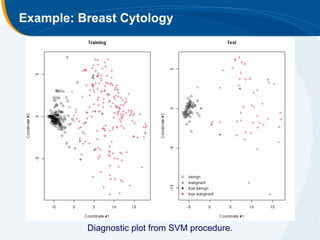
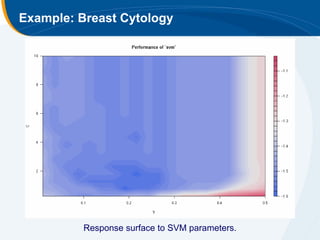
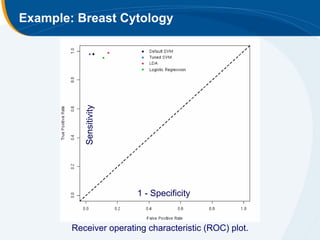
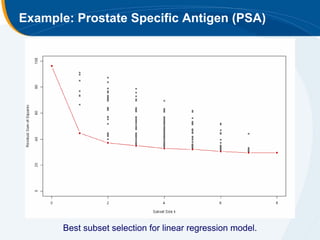
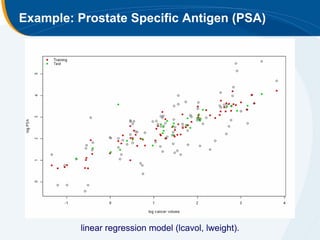
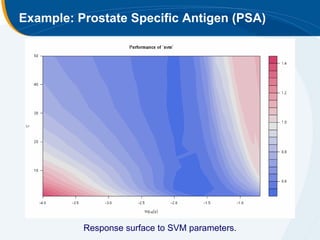
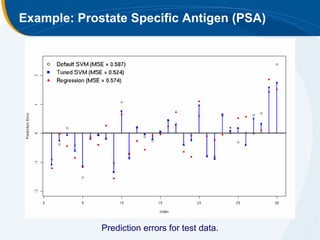
The document discusses the application of statistical techniques in multi-functional imaging trials, emphasizing the importance of multivariate data analysis over univariate methods. It covers various supervised learning methods, particularly focusing on support vector machines (SVM) for classification of imaging data, and includes examples from breast and prostate cancer studies. Conclusions highlight the need for appropriate statistical methods and collaboration with quantitative scientists to harness the full potential of imaging data.






















![Ch2 rev[1]](https://cdn.slidesharecdn.com/ss_thumbnails/ch2rev1-111122190305-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








































