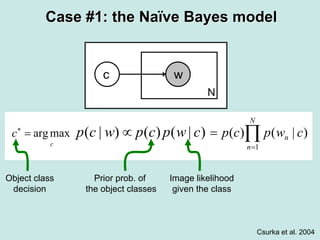
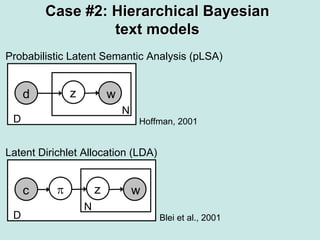
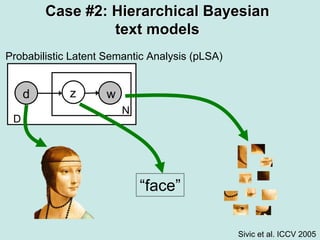
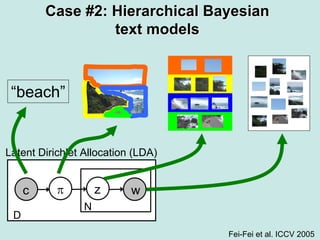
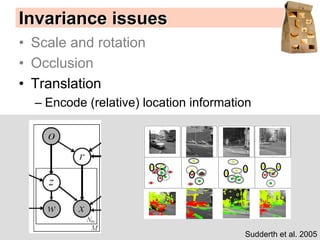
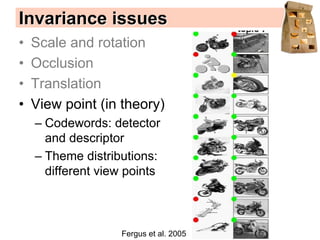
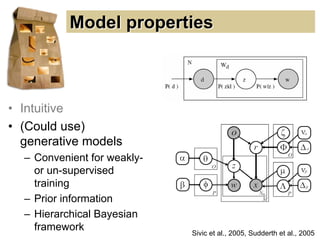
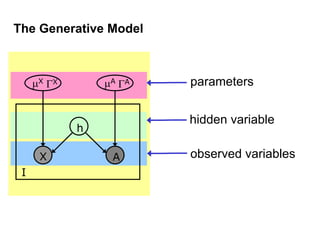
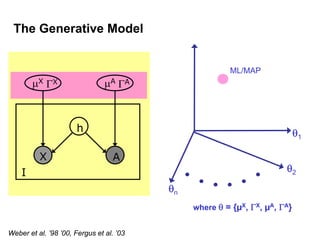
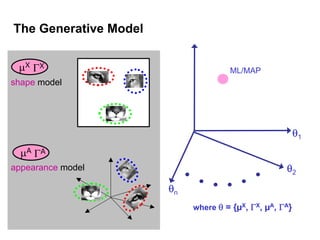
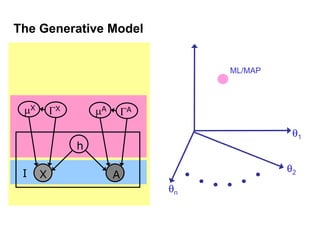
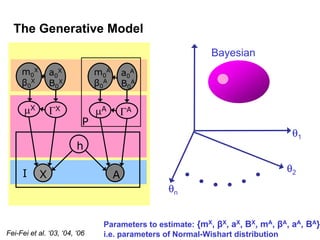
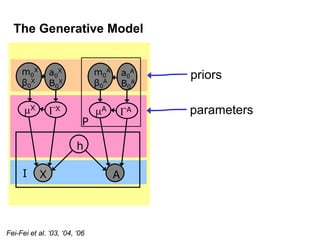
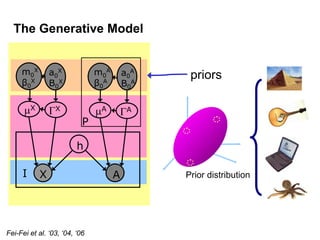
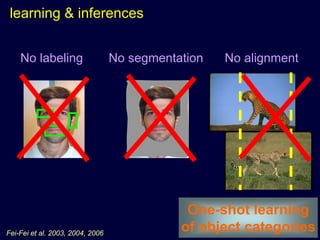
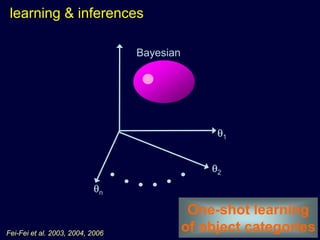
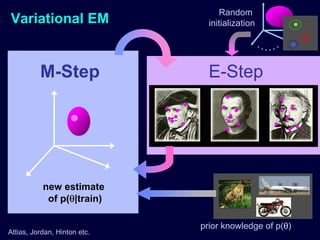
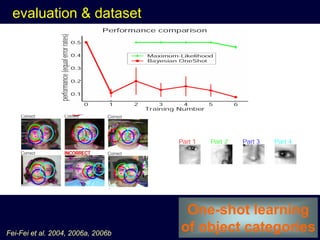
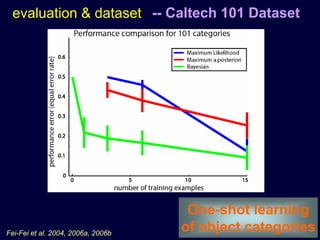
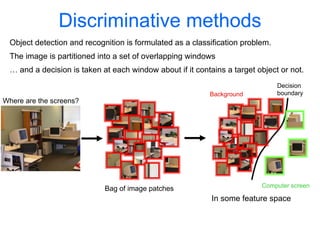
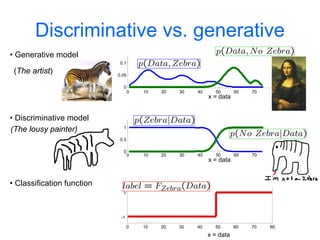
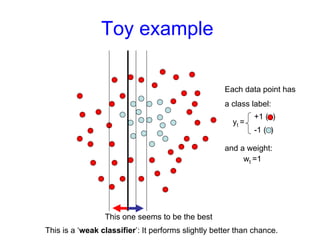
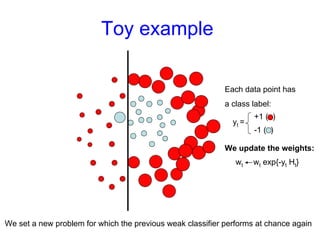
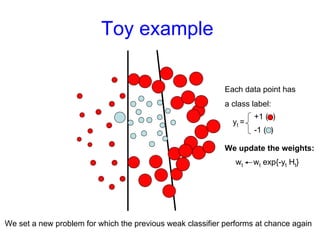
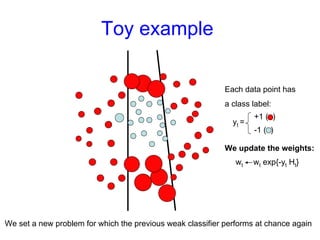
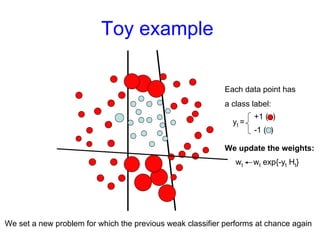
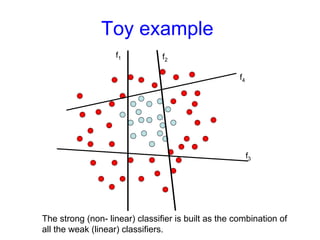
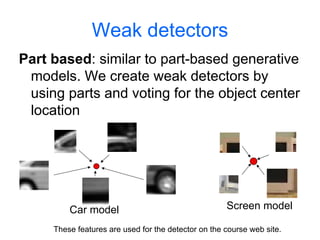
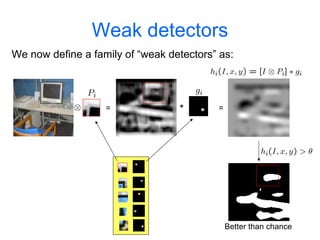
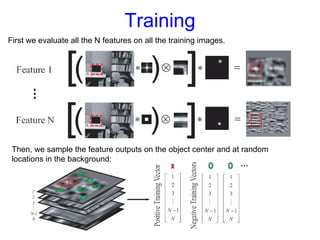
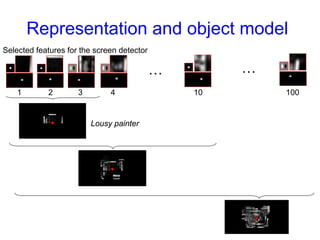
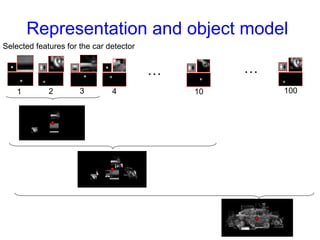
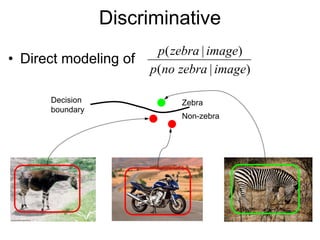
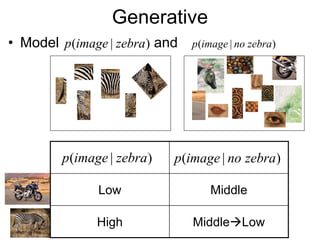
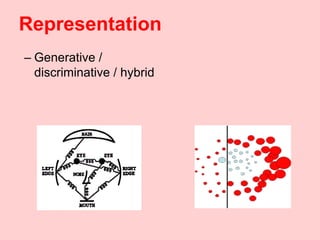
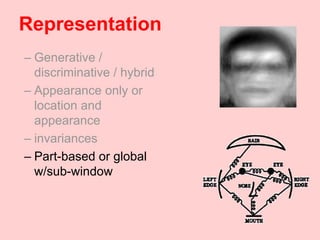
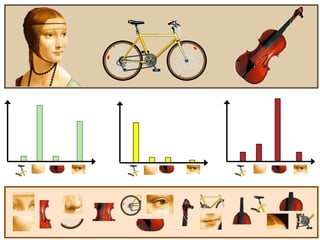
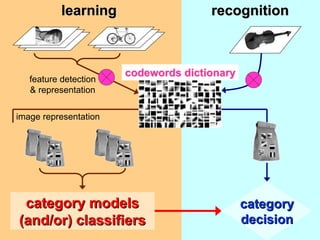
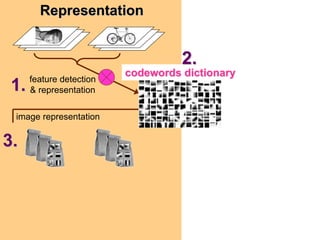
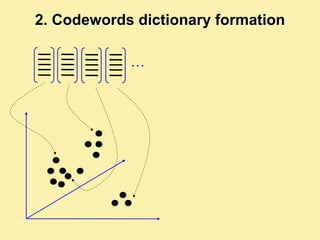
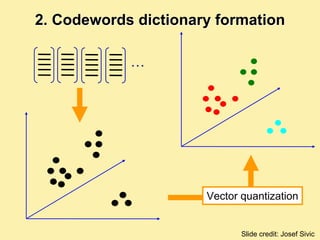
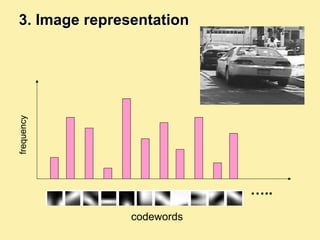
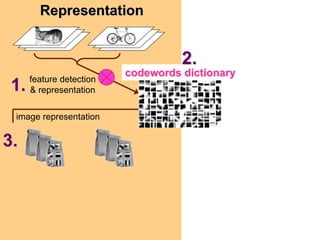
Machine learning methods are increasingly being used for computer vision tasks like object recognition. Bag-of-words models represent images as collections of local features or "visual words" to classify images based on their visual content. These models first detect local features, then cluster them into visual word codebooks. Images are then represented as histograms of visual word frequencies. Naive Bayes and hierarchical Bayesian models like pLSA and LDA can then be used for classification or topic modeling based on these image representations. While intuitive and computationally efficient, bag-of-words models lack explicit geometric information about object parts and have not been extensively tested for viewpoint and scale invariance.
































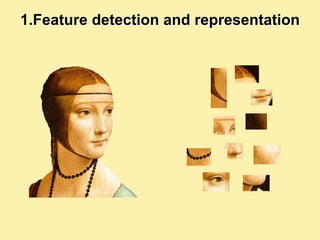
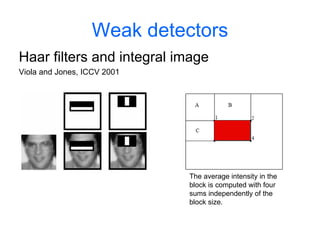
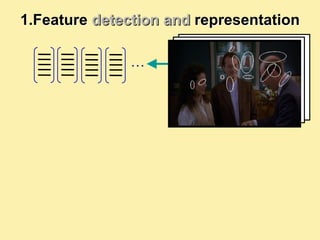
![1.Feature detection and representation
Compute
SIFT Normalize
descriptor patch
[Lowe’99]
Detect patches
[Mikojaczyk and Schmid ’02]
[Matas et al. ’02]
[Sivic et al. ’03]
Slide credit: Josef Sivic](https://image.slidesharecdn.com/machine-learning-in-computer-vision3786/85/Machine-Learning-in-Computer-Vision-45-320.jpg)


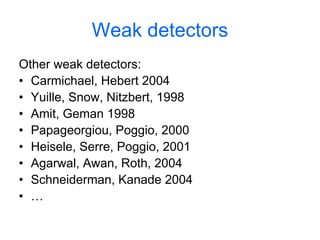
![First, some notations
• wn: each patch in an image
– wn = [0,0,…1,…,0,0]T
• w: a collection of all N patches in an image
– w = [w1,w2,…,wN]
• dj: the jth image in an image collection
• c: category of the image
• z: theme or topic of the patch](https://image.slidesharecdn.com/machine-learning-in-computer-vision3786/85/Machine-Learning-in-Computer-Vision-54-320.jpg)