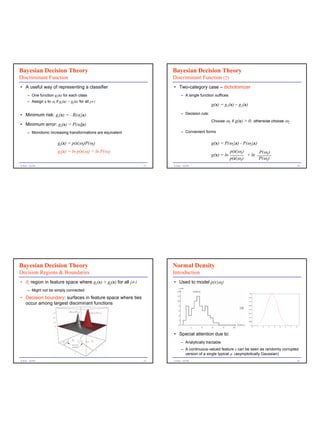
1) The document introduces Bayesian decision theory and its use for statistical pattern classification.
2) It discusses key concepts such as prior and conditional probabilities, loss functions, and deriving the minimum-risk classifier that minimizes expected loss.
3) The minimum-risk classifier chooses the decision or action that minimizes the total risk, calculated from the loss incurred for each state of nature weighted by its posterior probability.
![Overview
• Basic statistical concepts
Introduction to Pattern Recognition and Data Mining
– Apriori probability, class-conditional density
– Bayes formula & decision rule
Lecture 2: Bayesian Decision Theory – Loss function & minimum-risk classifier
Instructor: Dr. Giovanni Seni • Discriminant functions
• Decision regions/boundaries
Department of Computer Engineering
• The Normal density
Santa Clara University – Discriminant functions (LDA)
G.Seni – Q1/04 2
Introduction Introduction
Statistical Approach Statistical Approach (2)
• A formalization of common-sense procedures… • Best decision rule about next fish type before it actually
appears?
• Quantify tradeoffs between various classification decisions
using probability – Decide ω1 if P(ω1) > P(ω2); otherwise decide ω2
– How well it works?
• Initially assume all relevant probability values are known
• P(error) = min [P(ω1), P(ω2)]
• State of nature
– What fish type (ω) will come out next? • Incorporating lightness/length info
• ω1 = salmon, ω2 = sea bass
– Class-conditional probability density
– ω is unpredictable – i.e., a random variable
p(x|ω1) and p(x|ω2) describe the difference
• A priori probability -- prior knowledge of how likely each in lightness between populations of sea bass
and salmon
fish type is -- P(ω1) + P( ω2) = 1
G.Seni – Q1/04 3 G.Seni – Q1/04 4](https://image.slidesharecdn.com/pr-2-bayesiandecision-120104071409-phpapp02/85/Pr-2-bayesian-decision-1-320.jpg)
![Overview
• Basic statistical concepts
Introduction to Pattern Recognition and Data Mining
– Apriori probability, class-conditional density
– Bayes formula & decision rule
Lecture 2: Bayesian Decision Theory – Loss function & minimum-risk classifier
Instructor: Dr. Giovanni Seni • Discriminant functions
• Decision regions/boundaries
Department of Computer Engineering
• The Normal density
Santa Clara University – Discriminant functions (LDA)
G.Seni – Q1/04 2
Introduction Introduction
Statistical Approach Statistical Approach (2)
• A formalization of common-sense procedures… • Best decision rule about next fish type before it actually
appears?
• Quantify tradeoffs between various classification decisions
using probability – Decide ω1 if P(ω1) > P(ω2); otherwise decide ω2
– How well it works?
• Initially assume all relevant probability values are known
• P(error) = min [P(ω1), P(ω2)]
• State of nature
– What fish type (ω) will come out next? • Incorporating lightness/length info
• ω1 = salmon, ω2 = sea bass
– Class-conditional probability density
– ω is unpredictable – i.e., a random variable
p(x|ω1) and p(x|ω2) describe the difference
• A priori probability -- prior knowledge of how likely each in lightness between populations of sea bass
and salmon
fish type is -- P(ω1) + P( ω2) = 1
G.Seni – Q1/04 3 G.Seni – Q1/04 4](https://image.slidesharecdn.com/pr-2-bayesiandecision-120104071409-phpapp02/75/Pr-2-bayesian-decision-1-2048.jpg)


![Normal Density Normal Density
Univariate Case Bivariate Case
• x ∼ N(0, 1) -- x is normally distributed with zero mean and • If x ∼ N(0, 1) and y ∼ N(0, 1) are independent
unit variance 0.4
1 2 2
1 2 p(x, y) = p(x) â p(y) = 2ùe à2(x +y )
1
px(x) = √1 eà2x
2ù
0.3
0.2
0 = ö = ε[x] • Contours: p(x, y) = c1 ⇒ x2 + y 2 = c2
0.1
2 2
1 = û = ε[(x à ö) ] 0 0.14
-4 -3 -2 -1 0 1 2 3 4 0.12
68% 0.1
95% 0.08
0.06
• Location-scale shift 99.7%
0.04
0.02
z=σx+µ 0
1 zàö 2 4
∼ N(µ, σ) pz(z) = √2ùûe à2(
1 û
)
= û px(zàö)
1
û -4 0
1
2
3
-3 -2 -1
-1 0 -2
1 -3
2 3 -4
4
G.Seni – Q1/04 17 G.Seni – Q1/04 18
Normal Density Normal Density
Bivariate Case (2) Multivariate Case
• If x ∼ N(µx, σx) and y ∼ N(µy, σy) are independent • We say x ∼ N(µ, Σ)
2 2
1 x−µ x 1 x−µ y
− − 1
1 (xàö) tΣà1(xàö)
2 σ x 2 σ y
p(x) = (2ù)d/2|Σ| 1/2 e à2
1
p ( x, y ) = e
2πσ xσ y
• Contours: 1
û x2
(x à öx)2 + û12(y à öy)2 = c where,
y
ô õ ô 2 õ x = (x1, x2, …, xd)t (t stands for the transpose vector form)
0.16
ö û 0
p(x, y) = N( x , x
0.14
0.12 2 )
0.1
0.08
öy 0 ûy µ = (µ1, µ2, …, µd mean vector
)t
0.06
0.04 ô õô 2 õ
0.02
1 , 2 0 ) Σ = d× d covariance matrix
0
= N( 2
5 3 0 1 -1
3
4 2
|Σ| and Σ are determinant and inverse respectively
-4 -3 -2 -1 2
(x - µ)tΣ (x - µ) is (square) Mahalanobis distance
0 1
1 2 3 variance-covariance matrix -1
4 5 0
G.Seni – Q1/04 19 G.Seni – Q1/04 20](https://image.slidesharecdn.com/pr-2-bayesiandecision-120104071409-phpapp02/85/Pr-2-bayesian-decision-5-320.jpg)
![Bayesian Decision Theory Bayesian Decision Theory
Discriminant Function – Normal Density Discriminant Function – Normal Density (2)
• p(x|ωi) ∼ N(µi, Σi) • Case 1: features are statistically independent (σij= 0) and
share same variance σ2
• We had gi(x) = ln p(xω i) + ln P(ω i)
kxàö ik 2
gi(x) = à 2û 2 + ln P(ωi)
⇒ gi(x) = à 1(x à öi)tΣà1(x à öi) à d ln 2ù
2 i 2 1
= à 2û 2[x tx à 2ötx + ötöi] + ln P(ω i)
i i
1
− ln Σ i + ln P (ωi )
2 = w tx + w i0
i
2
• Case 1: Σi = û I
1
linear discriminant function where w i = û2öi
• Case 2: Σi = Σ 1
w i0 = à 2û2[ötöi] + ln P(ωi)
i
• Case 3: Σi = arbitrary
• All priors equal ⇒ Minimum (Euclidean) distance classifier
G.Seni – Q1/04 21 G.Seni – Q1/04 22
Bayesian Decision Theory Bayesian Decision Theory
Discriminant Function – Normal Density (3) Discriminant Function – Normal Density (4)
• Case 1: distributions are “spherical” in d dimensions; • Case 2: samples fall in hyperellipsoidal clusters of equal
boundary is a hyperplane in d-1 dimensions perpendicular size and shape
to line between means
gi(x) = à 1(x à öi)tΣ à1(x à öi) + ln P(ω)
2 i
= w tx + w i0
i as xtΣà1x can be dropped
where w i = Σà1öi
w i0 = à 1ötΣà1öi + ln P(ω i)
2 i
• All priors equal ⇒ Minimum (Mahalanobis) distance
classifier
G.Seni – Q1/04 23 G.Seni – Q1/04 24](https://image.slidesharecdn.com/pr-2-bayesiandecision-120104071409-phpapp02/85/Pr-2-bayesian-decision-6-320.jpg)









































































