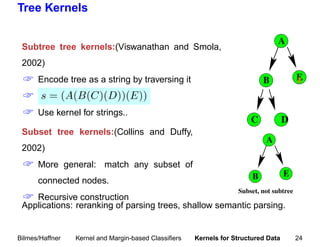
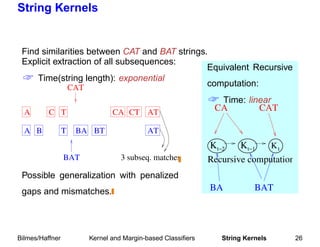
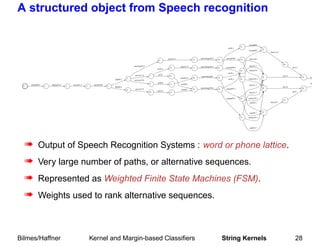
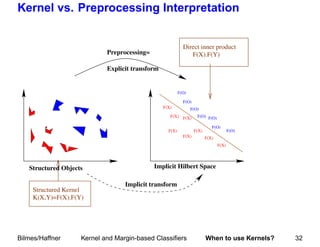
This document summarizes a tutorial on machine learning in speech and language processing presented on March 19, 2005 at ICASSP'05 in Philadelphia. The second half of the tutorial focused on kernel and margin-based classifiers, including an overview of statistical learning theory, kernel classifiers such as support vector machines (SVMs), and margin-based classifiers. Examples of applications to speech and natural language processing were provided.




![Binary Classifiers
Using training data (x1 , y1 ), . . . , (xm , ym ).
« Associate output y to input x ∈ X
« Most of our presentation assume binary classification:
y ∈ {−1, 1} or {0, 1}.
The following generalizations are usually possible:
« Probability estimator y ∈ [0, 1].
« Regression y ∈ R.
« Multi-category classification y ∈ {1, . . . , l}.
« Output codes y ∈ {−1, 1}l .
« Graphical Models x is the set of variables y depends upon.
Bilmes/Haffner Kernel and Margin-based Classifiers Statistical learning theory 4](https://image.slidesharecdn.com/machine-learning-in-speech-and-language-processing2871/85/Machine-Learning-in-Speech-and-Language-Processing-4-320.jpg)

![Empirical risk minimization
Training examples (x1 , y1 ), . . . , (xm , ym ) drawn from P (x, y).
« Learn f : X → {−1, +1}.
« Minimize the expected risk on a test set drawn from the same
P (x, y).
Rexp [f ] = L(f (x), y)dP (x, y) where L(f (x), y) = 2|f (x)−y|
Problem:
P is unknown
Need an induction principle
Find f ∈ F minimizing the Empirical Risk:
1
Rm [f ] = L(f (xi ), yi )
m m
Bilmes/Haffner Kernel and Margin-based Classifiers Statistical learning theory 6](https://image.slidesharecdn.com/machine-learning-in-speech-and-language-processing2871/85/Machine-Learning-in-Speech-and-Language-Processing-6-320.jpg)
![Uniform convergence bounds
Law of large numbers:Rm [f ] → Rexp [f ] when m → ∞.
But convergence must be Uniform over all functions f ∈ F .
lim P sup (Rexp [f ] − Rm [f ]) = 0 for all 0
m→∞ f ∈F
Bounds to guarantee this convergence established by
Vapnik (Vapnik, 1998) and others.
They typically establish that with probability 1 − δ
˜
O(h)
Rexp [f ] ≤ Rm [f ] +
mα
h is a measure of representation power of the function class F
Example: VC dimension.
Bilmes/Haffner Kernel and Margin-based Classifiers Statistical learning theory 7](https://image.slidesharecdn.com/machine-learning-in-speech-and-language-processing2871/85/Machine-Learning-in-Speech-and-Language-Processing-7-320.jpg)


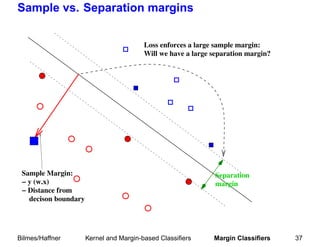
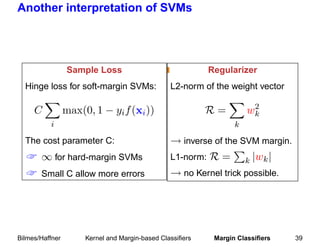
![Large-Margin Classifiers, Support Vector Machines
= sign(w · x + b).
Classifiers of type f (x)
1 ˜ D2
« Bound Rexp [f ] ≤ Rm [f ] + m O( M 2 )
Separate classes with the maximum margin M :
Support Vectors
Diameter D of smallest sphere cont. data.
Margin M
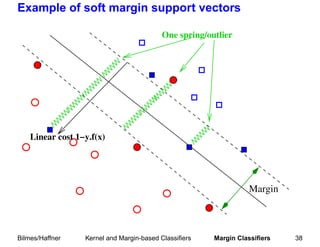
Soft margin to allow training errors: described later.
Bilmes/Haffner Kernel and Margin-based Classifiers Maximize the margin 10](https://image.slidesharecdn.com/machine-learning-in-speech-and-language-processing2871/85/Machine-Learning-in-Speech-and-Language-Processing-10-320.jpg)























![The boosting family of algorithms
« Training examples (x1 , y1 ), . . . , (xm , ym ) ∈ X × {−1, 1}.
« for t = 1, . . . , T :
update distribution Dt on examples {1, . . . , m}
find weak hypotheses ht : X → {−1, 1}
with small error t = PrDt [ht (xi ) = yi ]
« Output final hypotheses Hf inal .
Most famous member of the family: Adaboost (Freund and Schapire,
1996)
1 1−
« Using weight-update factor α = 2 log t
t
Dt (i)
« Dt+1 (i) = Zt exp(−αt yi ht (xi ))
« Hf inal (x) = sign( t αt ht (x))
Bilmes/Haffner Kernel and Margin-based Classifiers Margin Classifiers 42](https://image.slidesharecdn.com/machine-learning-in-speech-and-language-processing2871/85/Machine-Learning-in-Speech-and-Language-Processing-42-320.jpg)