Downloaded 12 times




![Big Data in Context
• What is “big data”?
– Unhelpfully, both “big data” and “NoSQL,” generally
considered a key part of the big data wave, are defined
more in terms of what they aren’t than what they are
– A typical big data definition (Wikipedia):
• “[…] data sets that grow so large that they become awkward to
work with using on-hand database management tools”
– Often associated with Gartner’s volume, variety (and
complexity), and velocity model
• Also value and veracity considerations
4](https://image.slidesharecdn.com/gilbaneboston2012t3bigdata101-121130074513-phpapp02/85/Gilbane-Boston-2012-Big-Data-101-4-320.jpg)



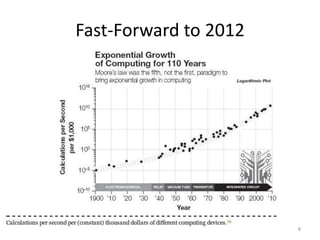
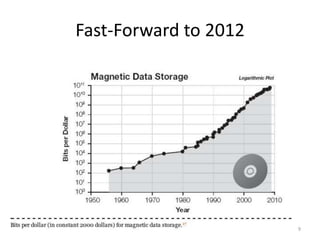
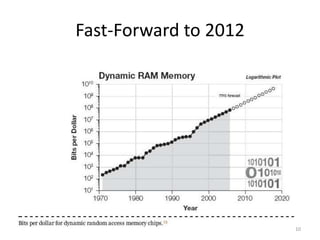
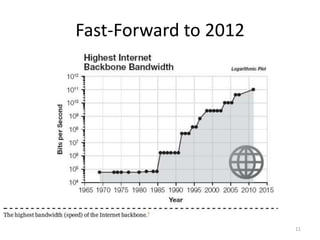















This document discusses big data and applying semantics to unstructured data. It provides an overview of big data, including what big data is, why it is important now due to cheaper hardware and software, and examples like Hadoop. It also discusses NoSQL databases and semantic tools to help analyze and understand large, unstructured data sets. Key recommendations are to aim high and leverage the big data opportunities, build consensus on opportunities and risks, and focus on developing important human skills like critical thinking to help analyze large data sets.








































































