Downloaded 15 times




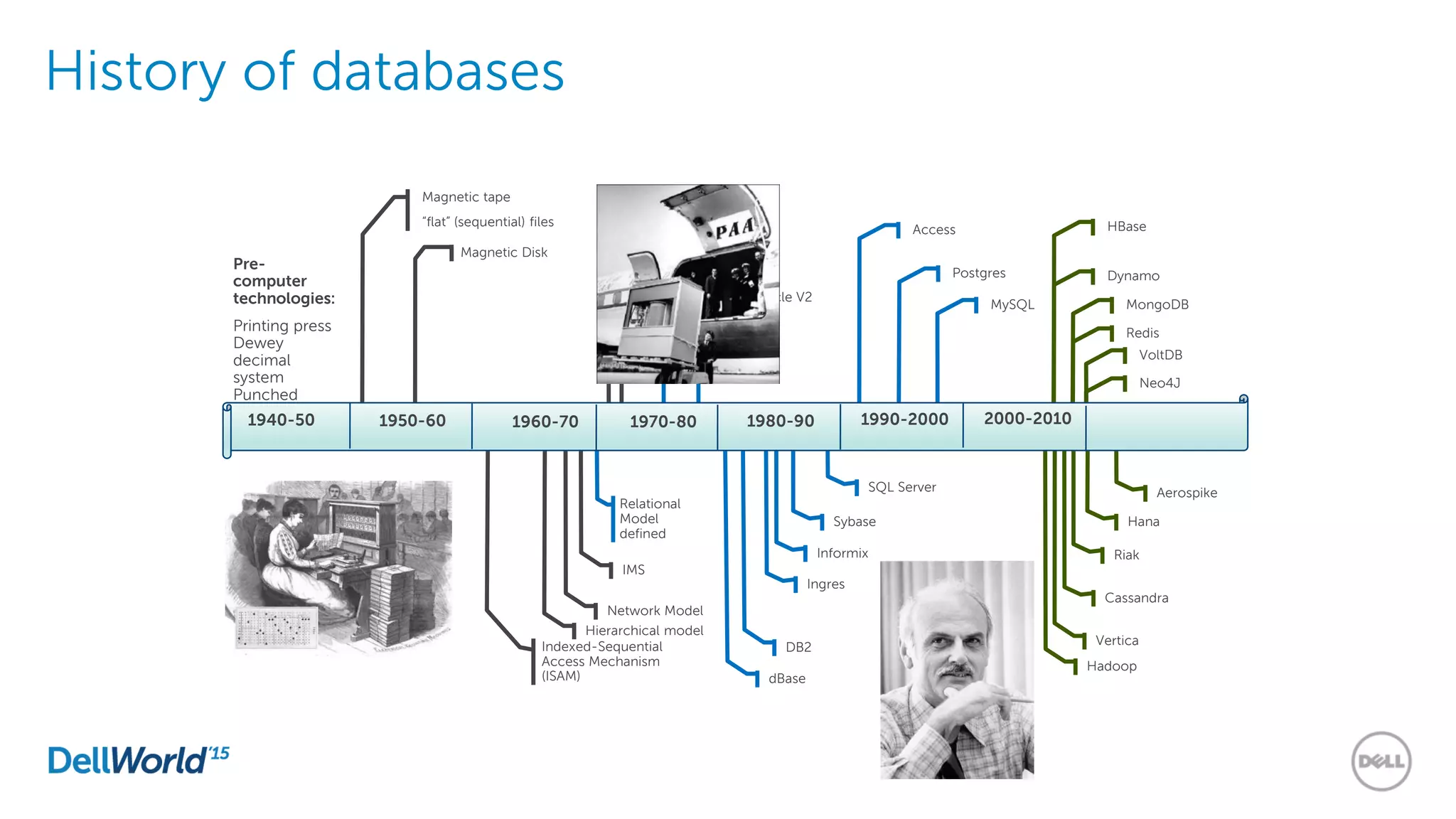

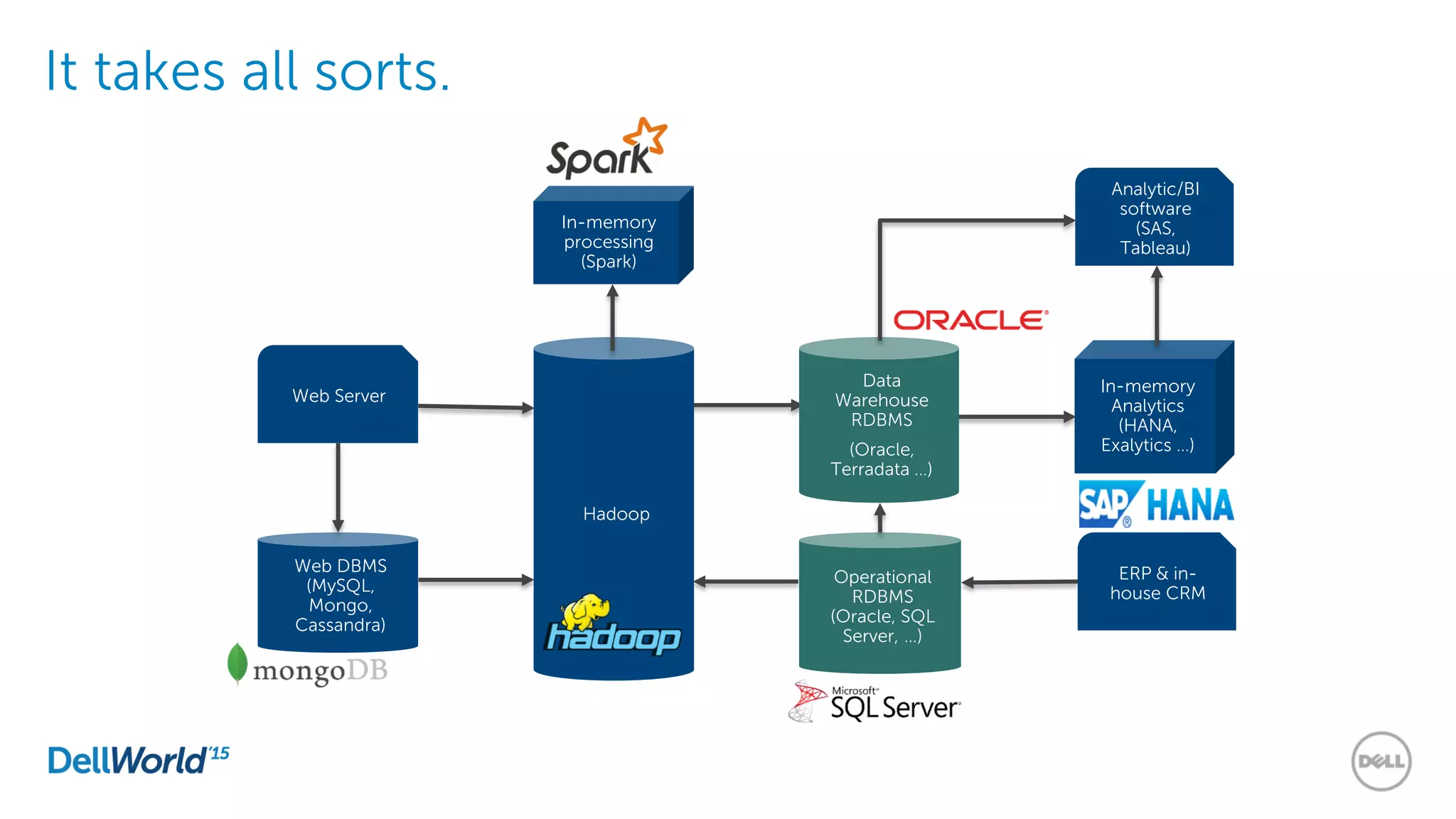

















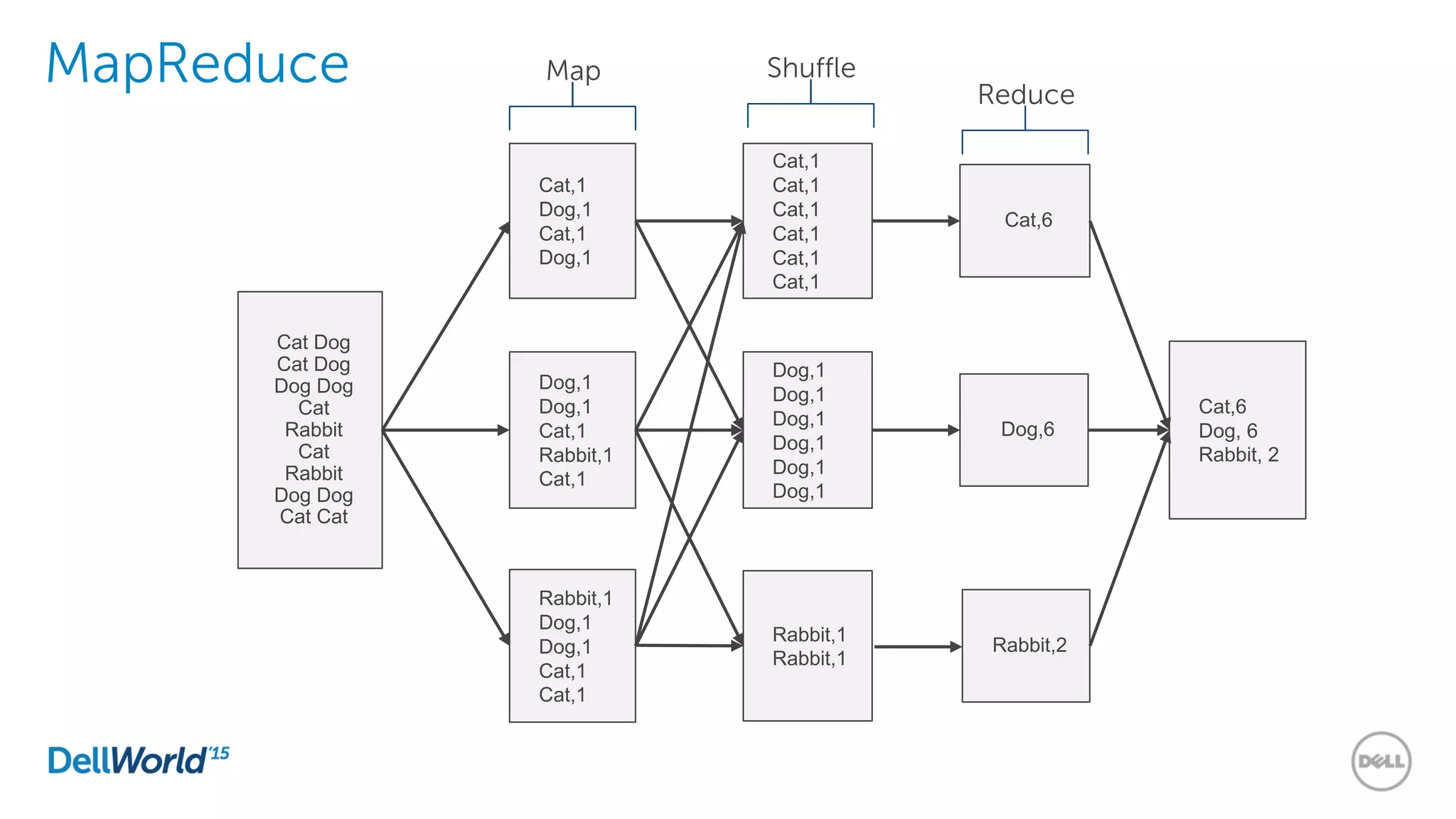
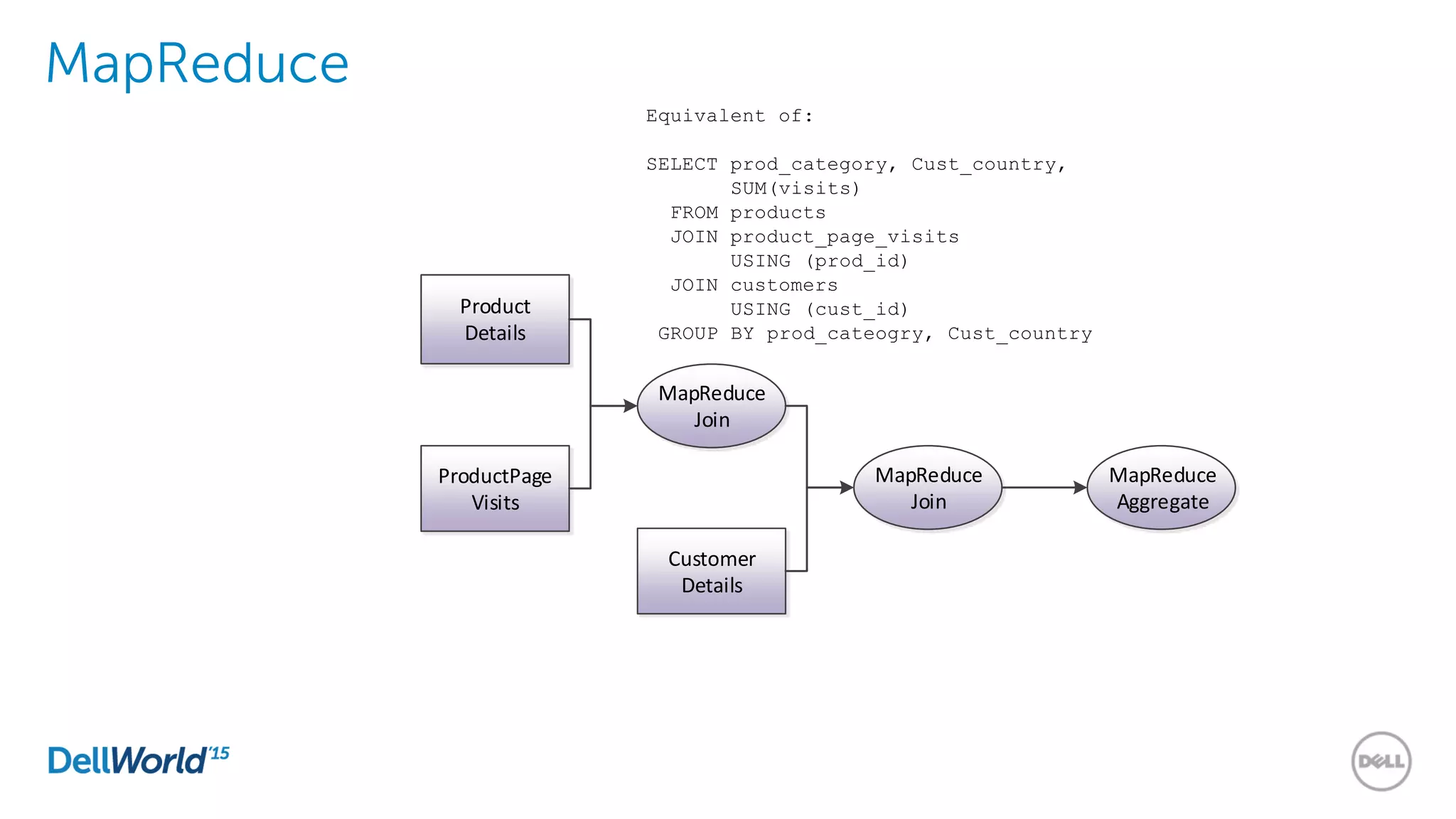



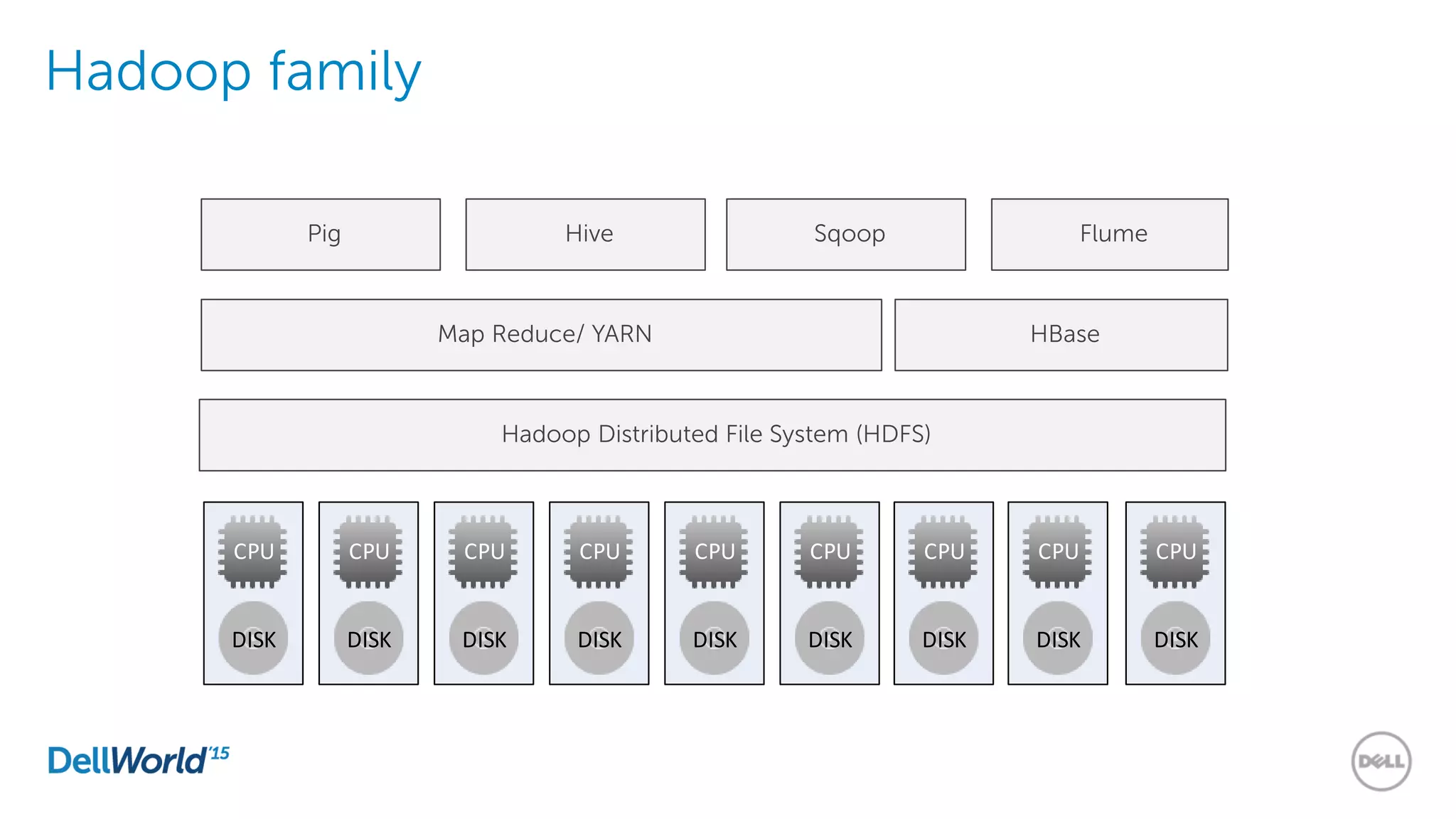
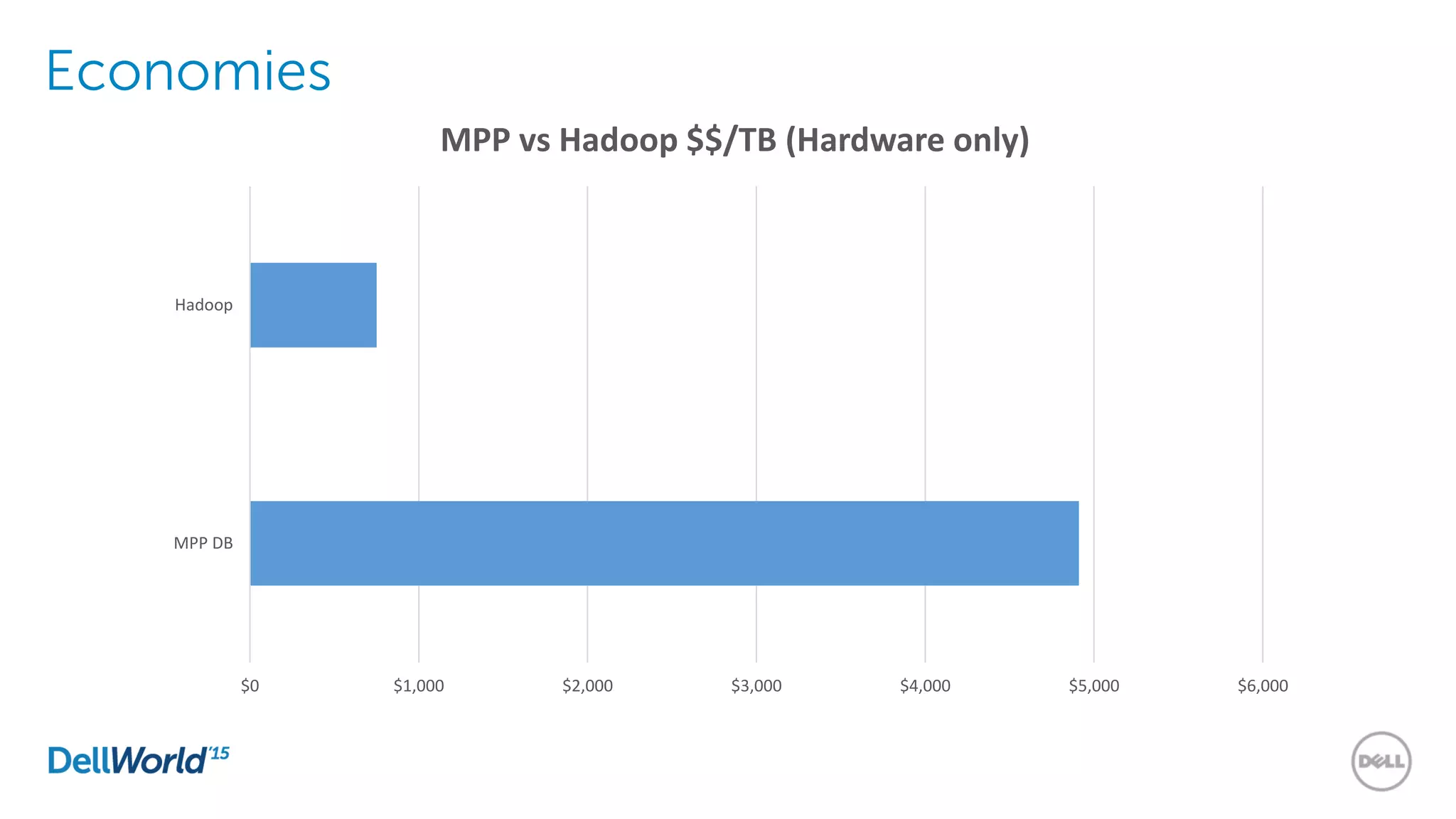

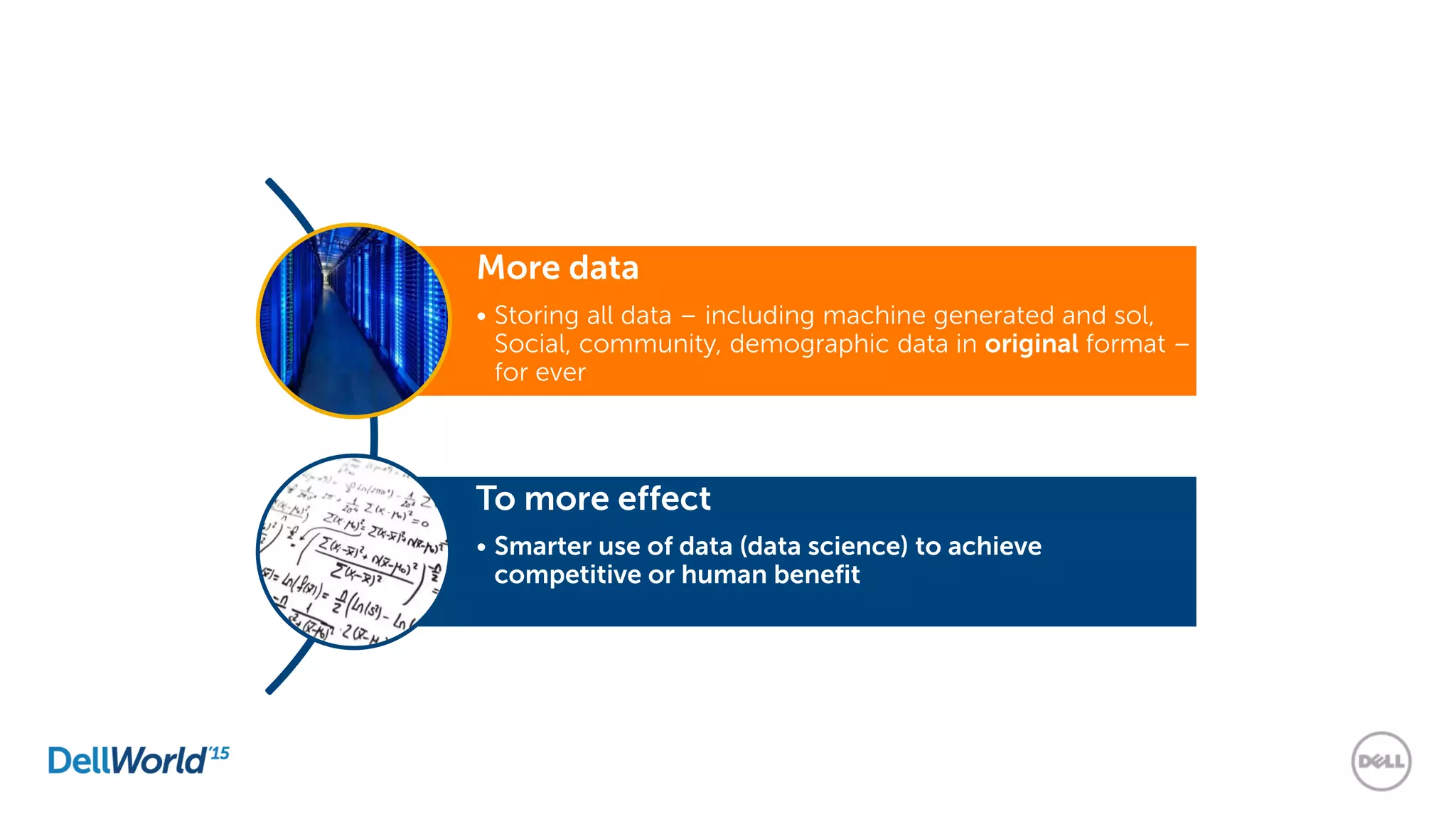
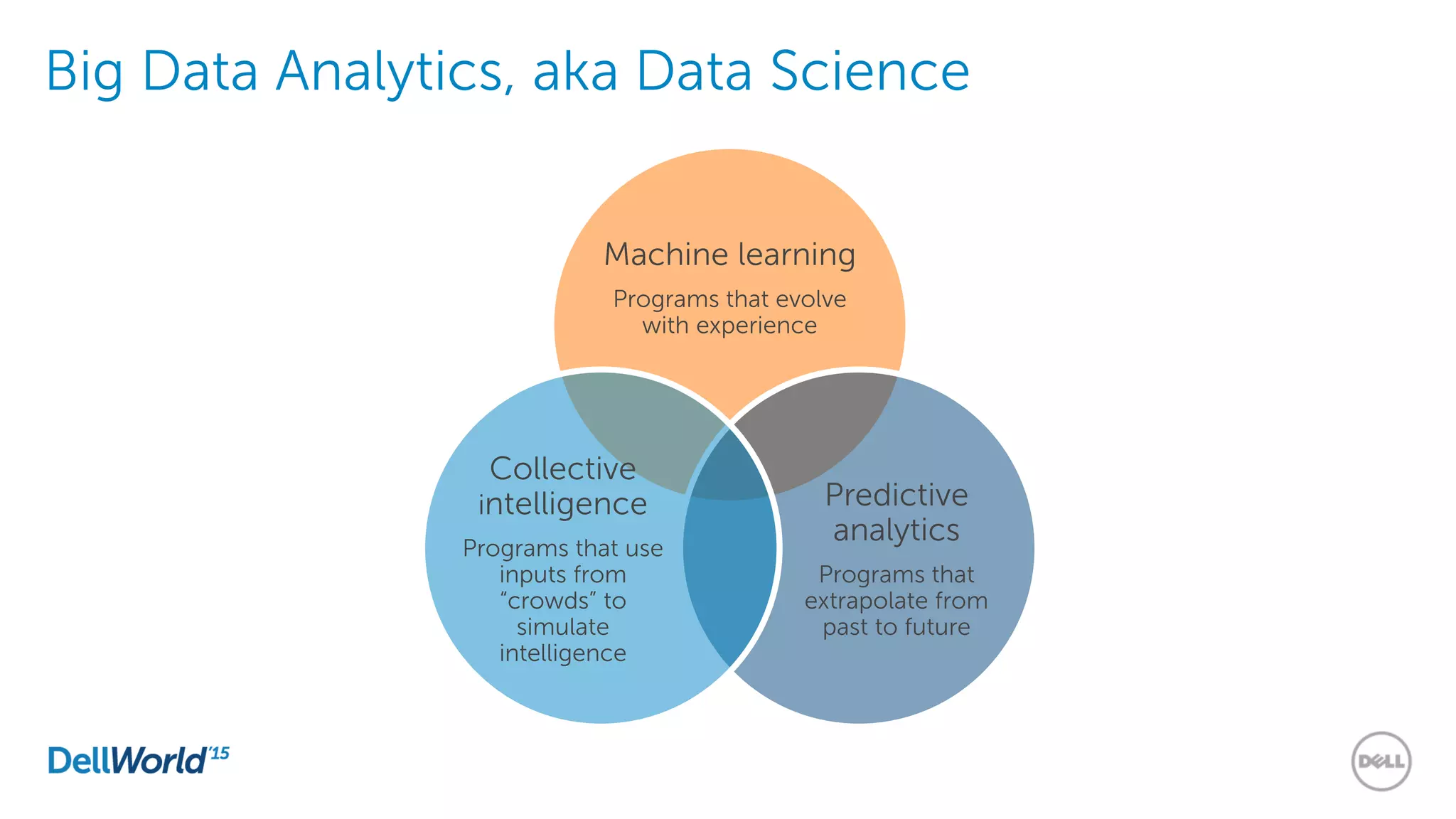
















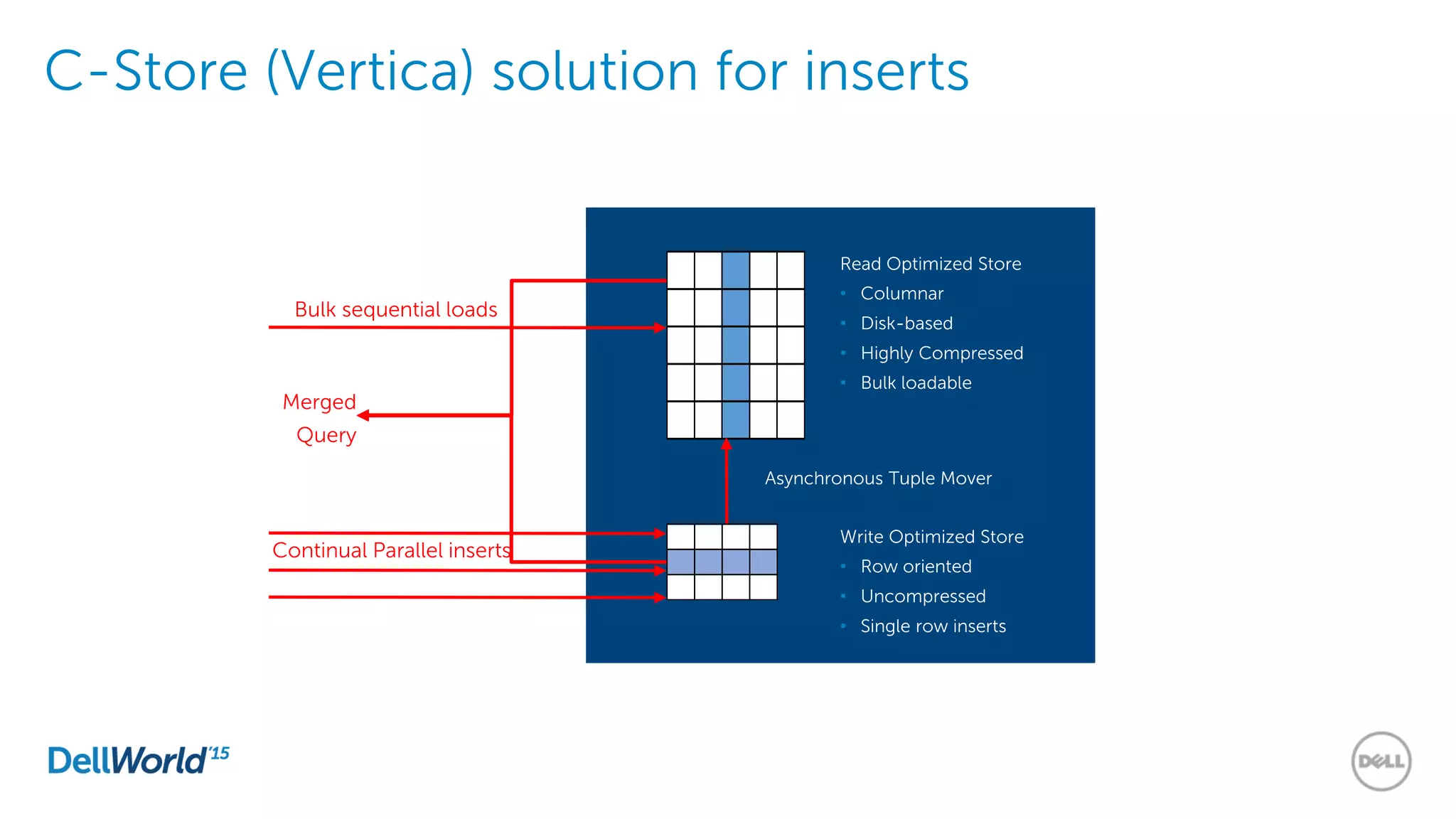



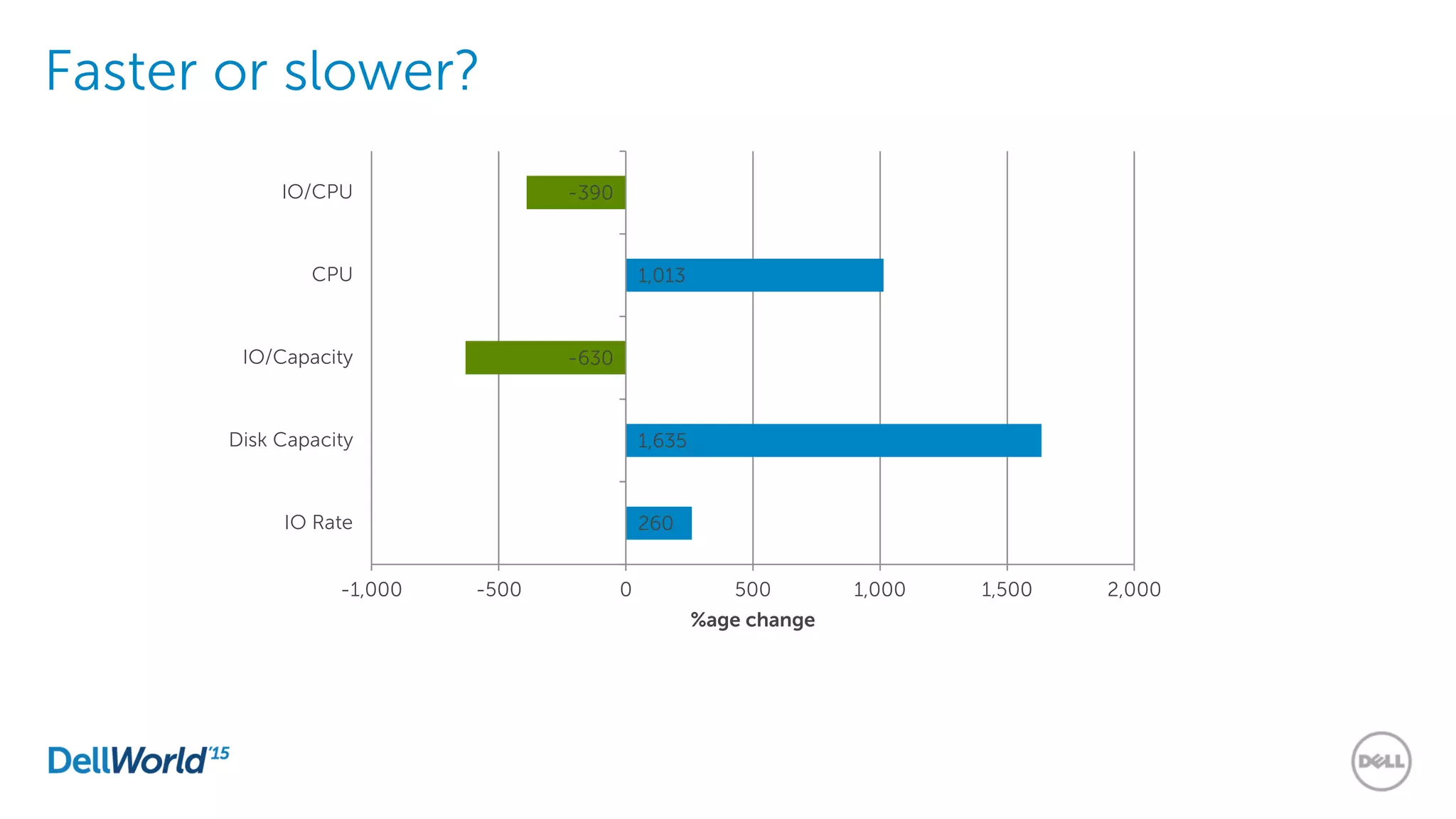

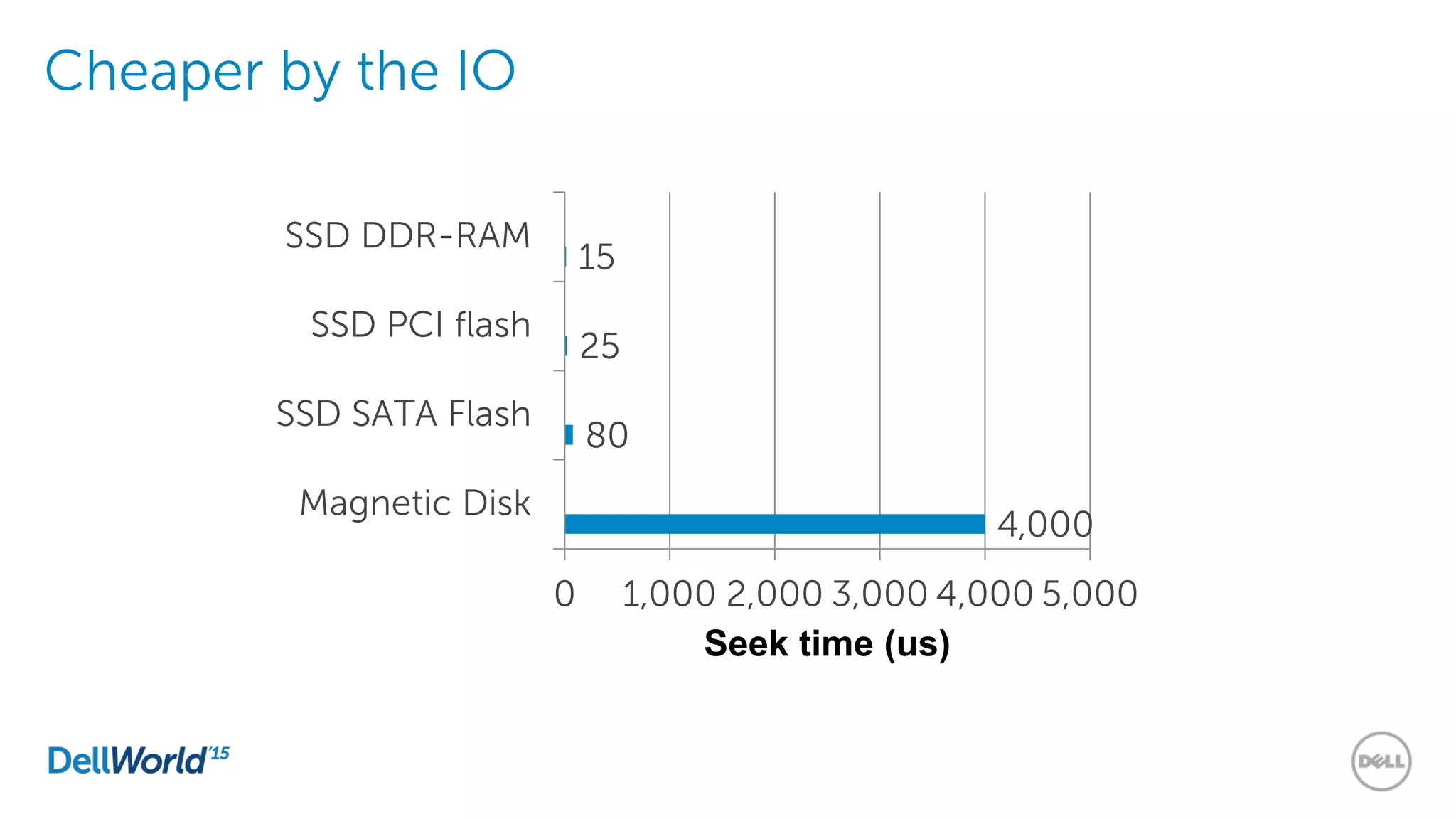

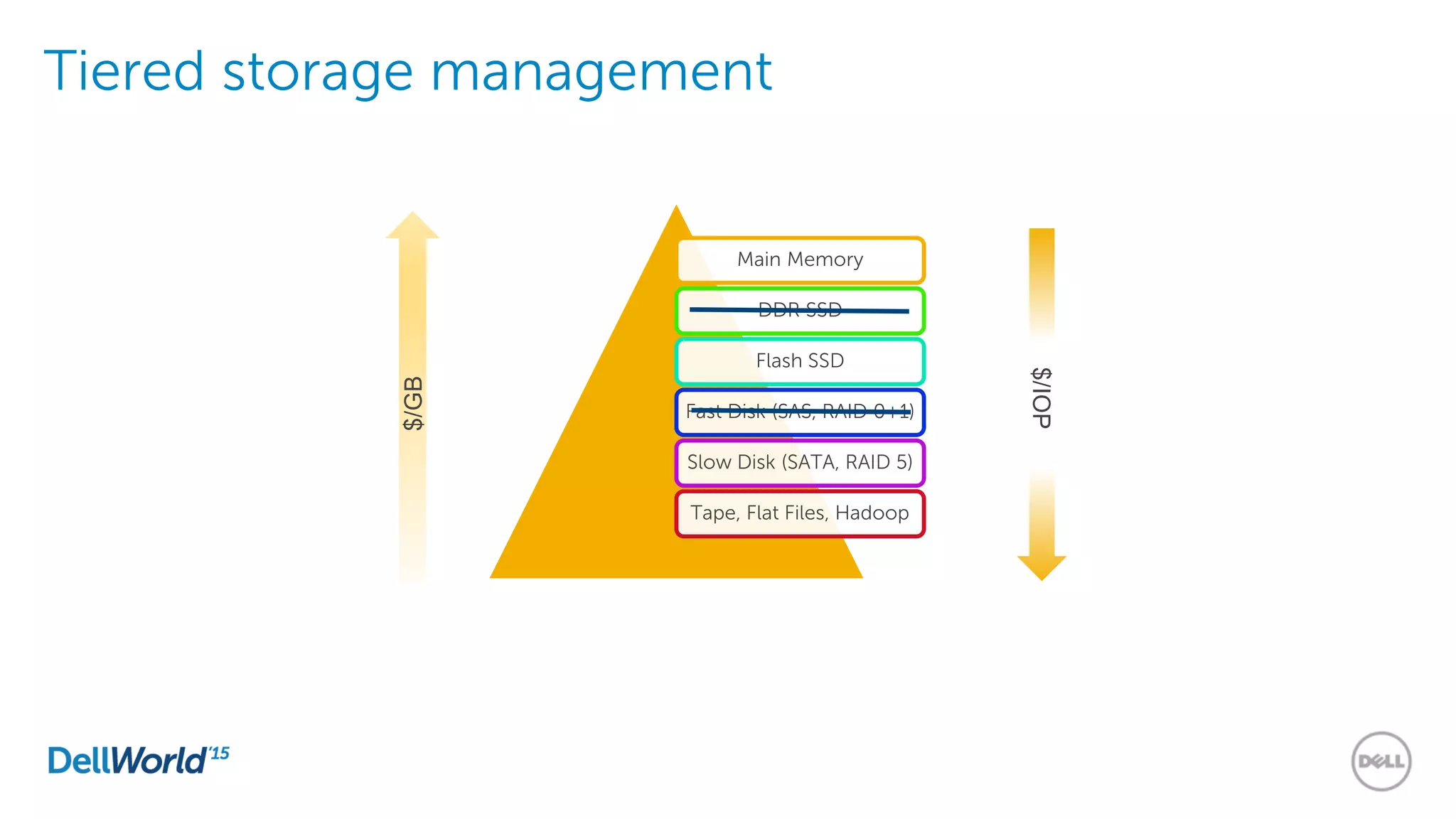
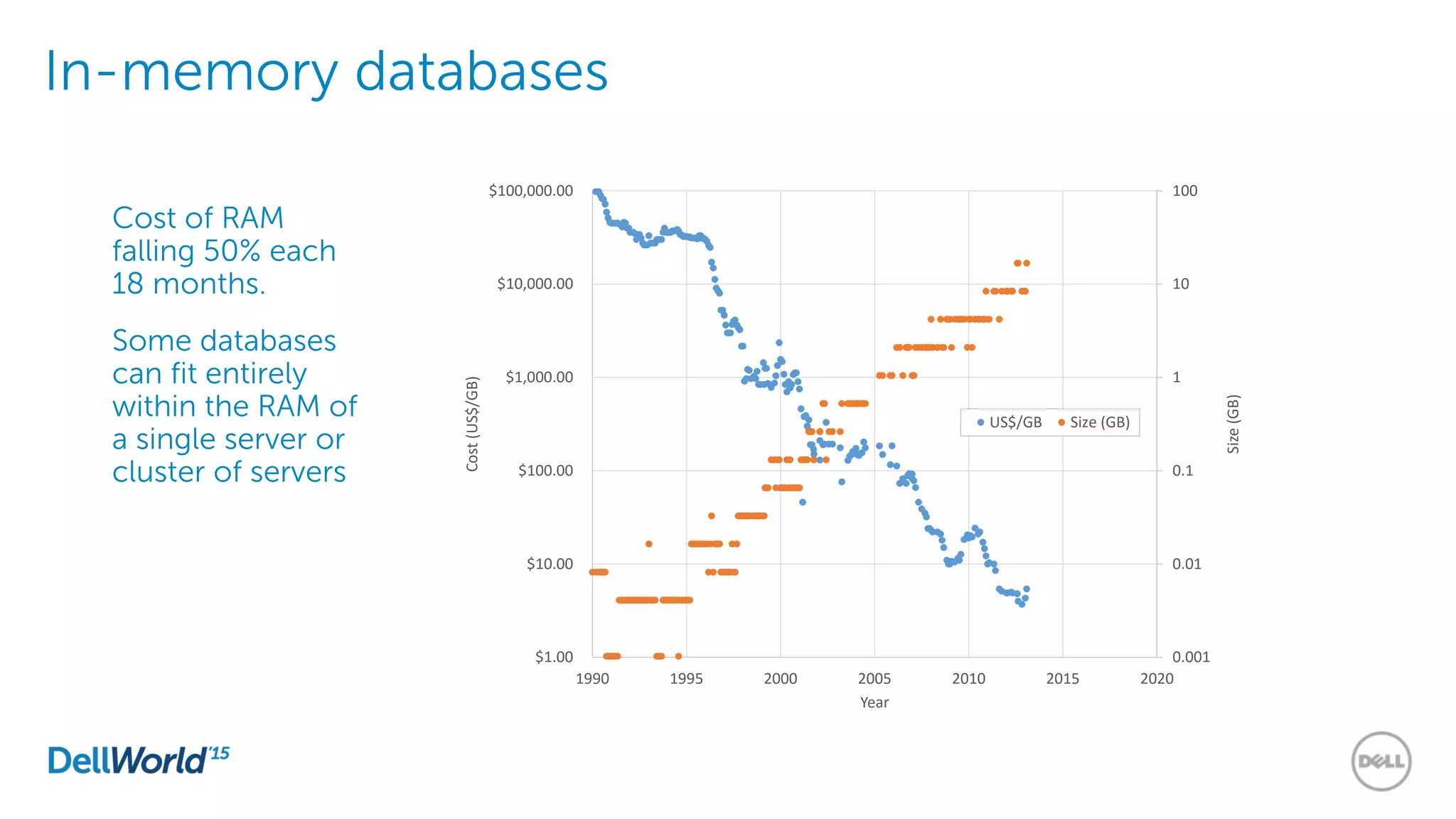
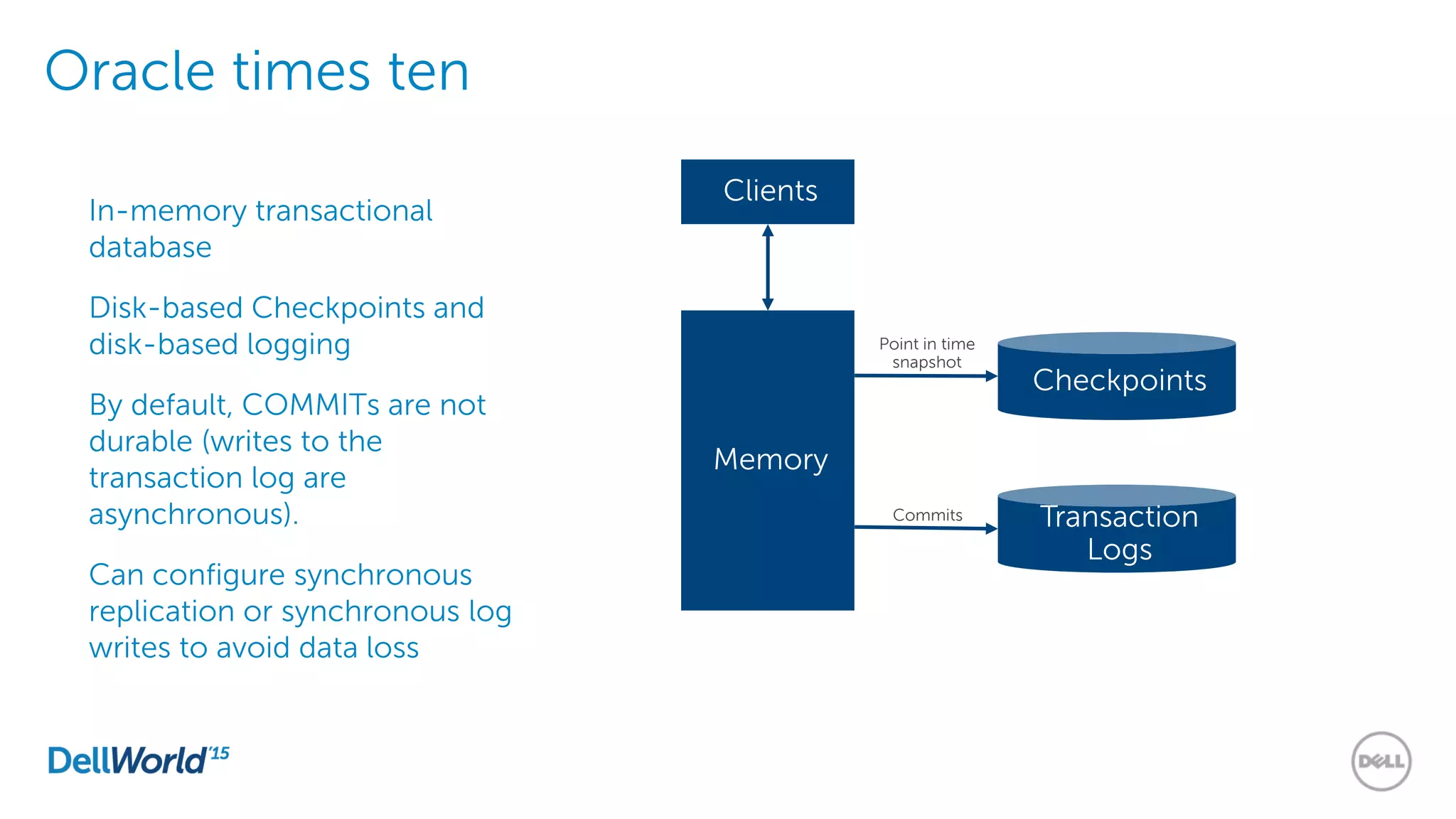
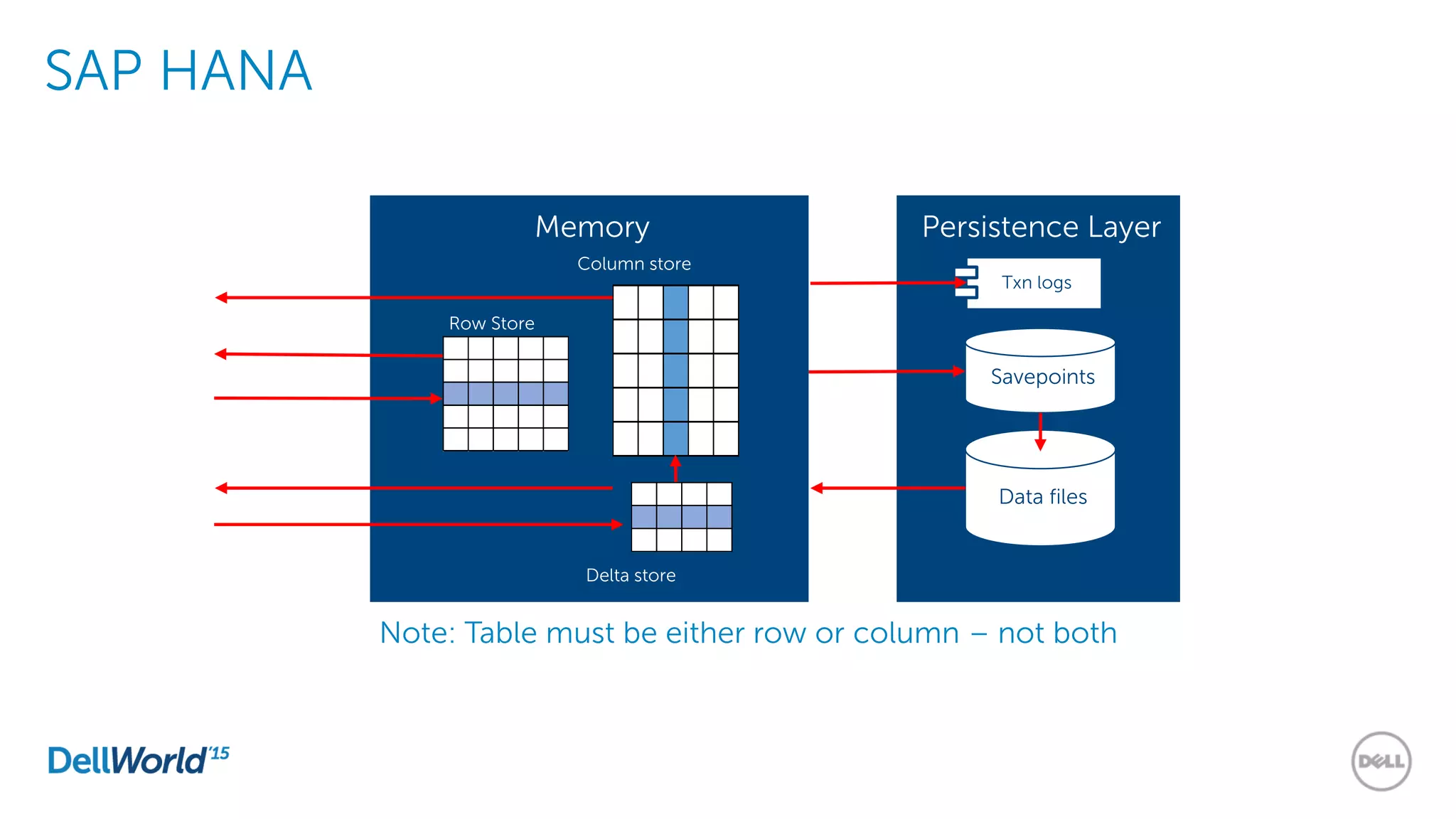

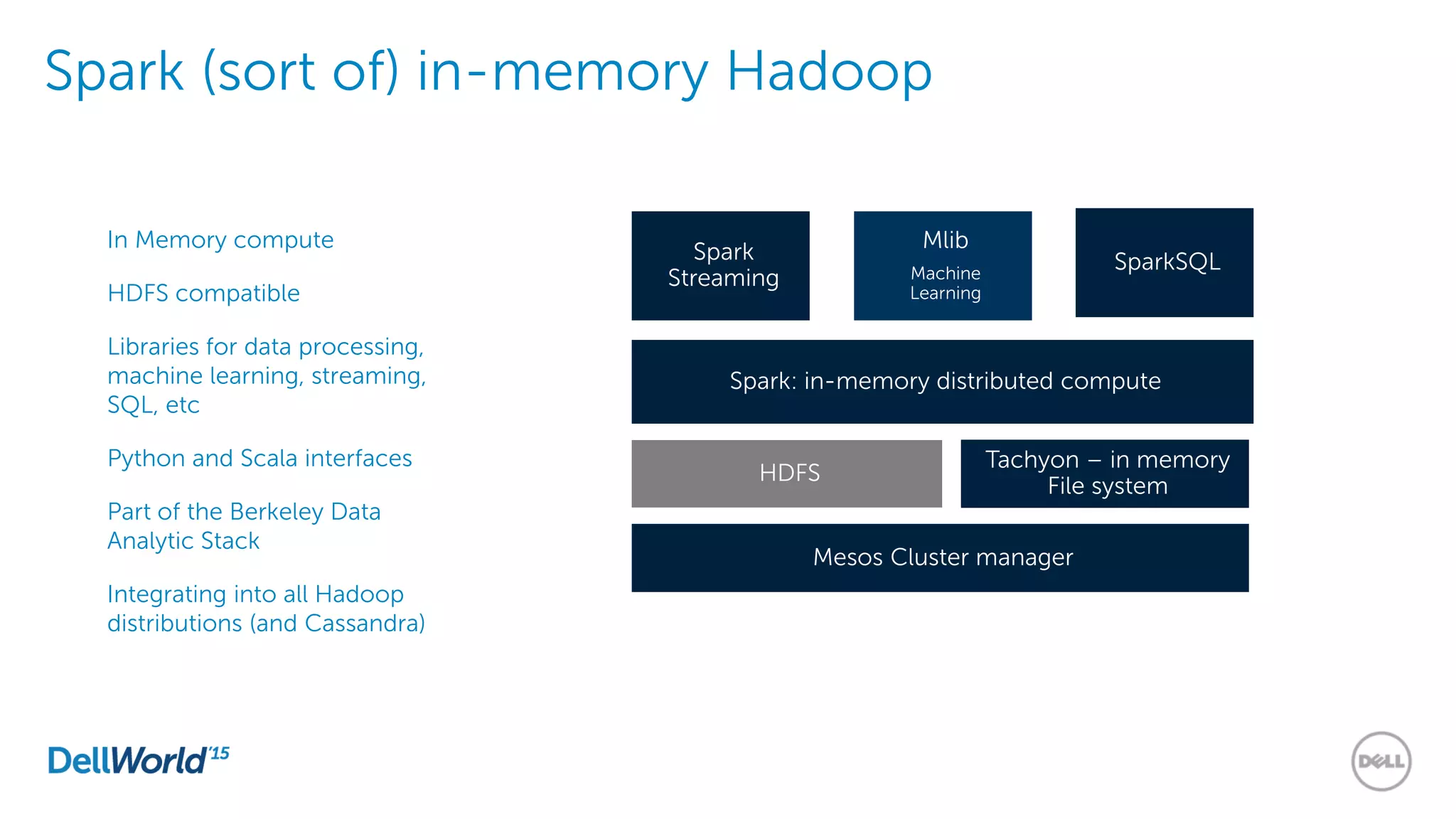




The document outlines the evolution of database technologies from traditional systems to contemporary big data solutions. It highlights the challenges posed by increasing data volume, transaction rates, and the necessity for high availability, emphasizing the role of NoSQL databases and frameworks like Hadoop in addressing these demands. Additionally, it discusses key models and concepts such as CAP theorem, data science, and the significance of in-memory databases in modern data architecture.























































































