Download to read offline


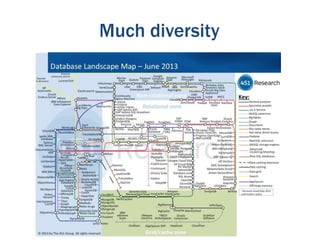





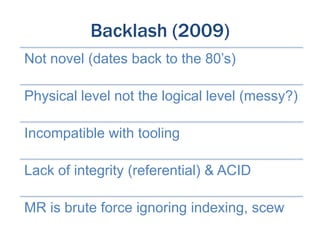

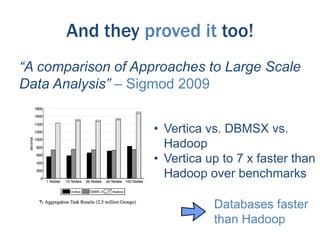























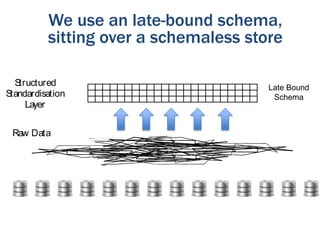


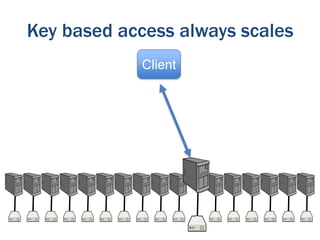
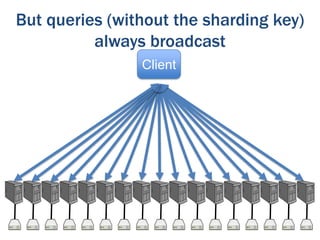
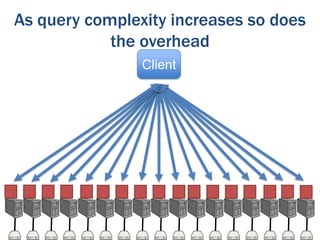
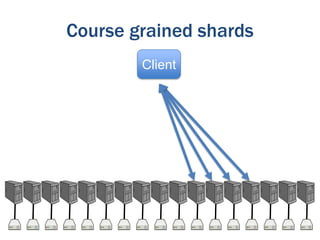
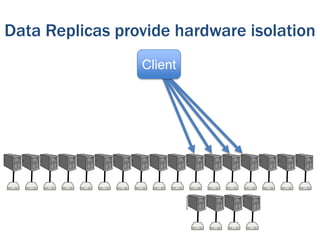












The document discusses the evolution of database technologies from relational databases to NoSQL databases. It argues that NoSQL databases better fit the needs of modern software development by supporting iterative development, fast feedback, and frequent releases. While early NoSQL technologies faced criticisms regarding lack of features like transactions and integrity checks, they proved useful for scaling applications to large data volumes. The document also advocates for an approach that balances flexibility with complexity by using schemaless stores at the front-end and more rigid structures at the back-end.




























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)












