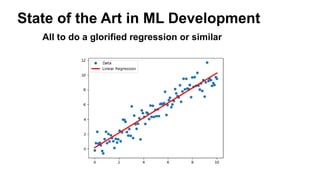
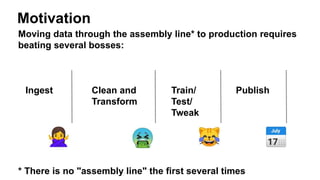
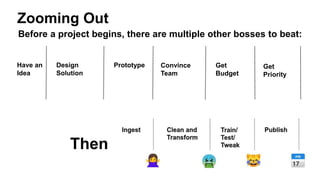
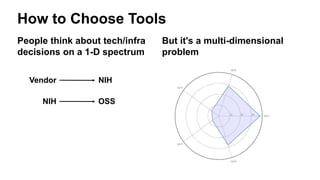
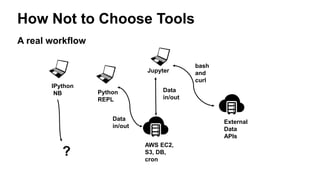
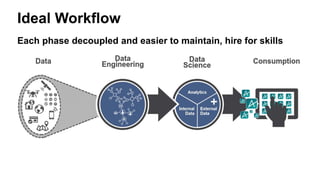
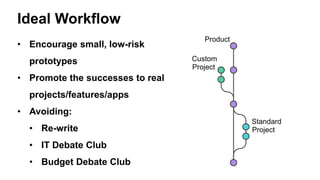
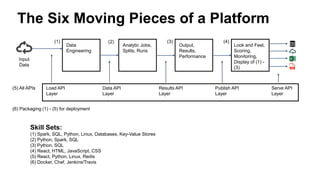
The document presents insights from Andrew Musselman's talk on maintaining machine learning (ML) products, emphasizing the challenges and failures organizations face in ML development and deployment. Key issues include the lack of established workflows, escalating project scopes, and difficulties integrating results into existing infrastructures. It advocates for a structured approach to selecting tools, encouraging small prototypes, and maintaining good practices to enhance productivity in ML projects.







![ML/AI Has a Lot of Attention
In the face of these troubles, ML/AI is a stated priority of many,
many, many, orgs
• Leadership team: "we need an ML/AI story immediately; everyone is
doing it and we are behind the competition" 🤔
• Countless teams: "we need sentiment analysis of [our medical
records | social media about us | the stock market]" 😬
• "Can't machine learning fix this problem?" 🤔
• "Machine learning is a commodity now" 😂](https://image.slidesharecdn.com/maintainablemachinelearningproducts-190513213102/85/Maintainable-Machine-Learning-Products-11-320.jpg)











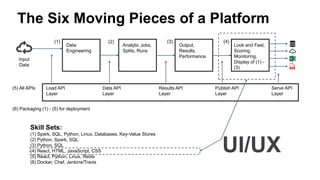
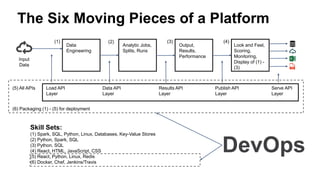
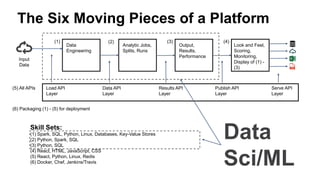


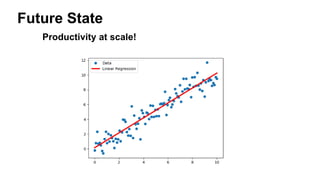

































































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)



