Downloaded 12 times







![More “free” boosts
Automatic vectorization
• Always on in VS2012 SCALAR VECTOR
(1 operation) (N operations)
• Uses “vector” instructions
where possible in loops r1 r2 v1 v2
+ +
for (i = 0; i < 1000; i++) {
r3 v3
A[i] = B[i] + C[i]; vector
length
} add r3, r1, r2 vadd v3, v1, v2
• Can run this loop in only 250
iterations down from 1,000!](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-9-2048.jpg)
![More “free” boosts
Automatic parallelization
• Uses multiple CPU cores
• /Qpar compiler switch
#pragma loop (hint_parallel(4))
for (i = 0; i < 1000; i++) {
A[i] = B[i] + C[i];
}
• Can run this loop “vectorized”
and on 4 CPU cores in parallel](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-10-2048.jpg)


![parallel_for
parallel_for iterates over a range in parallel
#include <ppl.h>
using namespace concurrency;
parallel_for( 0, 1000,
[] (int i) {
work(i);
}
);](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-13-2048.jpg)
![parallel_for
parallel_for(0, 1000, [] (int i) {
work(i);
});
Core 1 Core 2
• Order of iteration is indeterminate.
work(0…249) work(250…499)
• Cores may come and go.
• Ranges may be stolen by newly idle
cores.
Core 3 Core 4
work(500…749) work(750…999)](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-14-2048.jpg)

![parallel_for_each
parallel_for_each iterates over an STL container in parallel
#include <ppl.h>
using namespace concurrency;
vector<int> v = …;
parallel_for_each(v.begin(), v.end(),
[] (int i) {
work(i);
}
);](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-16-2048.jpg)

![parallel_invoke
• Executes function objects in parallel and waits for them to finish
#include <ppl.h>
#include <string>
#include <iostream>
using namespace concurrency; using namespace std;
template <typename T>
T twice(const T& t) {
return t + t;
}
int main() {
int n = 54; double d = 5.6; string s = "Hello";
parallel_invoke(
[&n] { n = twice(n); },
[&d] { d = twice(d); },
[&s] { s = twice(s); }
);
cout << n << ' ' << d << ' ' << s << endl;
return 0;
}](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-18-2048.jpg)
![task<>
• Used to write asynchronous code
• Task::then lets you create continuations that get executed when the task finishes
• You need to manage the lifetime of the variables going into a task
#include <ppltasks.h>
#include <iostream>
using namespace concurrency; using namespace std;
int main()
{
auto t = create_task([]() -> int
{
return 42;
});
t.then([](int result)
{
cout << result << endl;
}).wait();
}](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-19-2048.jpg)

 {
if (is_carmichael(i))
carmVec.push_back(i);
});](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-21-2048.jpg)



![1. #include <iostream>
2.
3.
4. int main()
5. {
6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'};
7.
8. for (int idx = 0; idx < 11; idx++)
9. {
10. v[idx] += 1;
11. }
12. for(unsigned int i = 0; i < 11; i++)
13. std::cout << static_cast<char>( v[i]);
14. }](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-26-2048.jpg)
![1. #include <iostream>
2. #include <amp.h>
amp.h: header for C++ AMP library
3. using namespace concurrency;
concurrency: namespace for library
4. int main()
5. {
6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'};
7.
8. for (int idx = 0; idx < 11; idx++)
9. {
10. v[idx] += 1;
11. }
12. for(unsigned int i = 0; i < 11; i++)
13. std::cout << static_cast<char>( v[i]);
14. }](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-27-2048.jpg)
![1. #include <iostream>
2. #include <amp.h>
3. using namespace concurrency;
4. int main()
5. {
6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'};
7. array_view<int> av(11, v); array_view: wraps the data to operate on the
accelerator. array_view variables captured and
8. for (int idx = 0; idx < 11; idx++)
associated data copied to accelerator (on demand)
9. {
10. v[idx] += 1;
11. }
12. for(unsigned int i = 0; i < 11; i++)
13. std::cout << static_cast<char>( v[i]);
14. }](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-28-2048.jpg)
![1. #include <iostream>
2. #include <amp.h>
3. using namespace concurrency;
4. int main()
5. {
6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'};
7. array_view<int> av(11, v); array_view: wraps the data to operate on the
accelerator. array_view variables captured and
8. for (int idx = 0; idx < 11; idx++)
associated data copied to accelerator (on demand)
9. {
10. av[idx] += 1;
11. }
12. for(unsigned int i = 0; i < 11; i++)
13. std::cout << static_cast<char>( av[i]);
14. }](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-29-2048.jpg)
![1. #include <iostream>
2. #include <amp.h>
3. using namespace concurrency;
4. int main() parallel_for_each: execute the lambda
5. { on the accelerator once per thread
6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'};
extent: the parallel loop bounds
or computation “shape”
7. array_view<int> av(11, v);
8. parallel_for_each(av.extent, [=](index<1> idx) restrict(amp)
9. {
10. av[idx] += 1; index: the thread ID that is running
11. }); the lambda, used to index into data
12. for(unsigned int i = 0; i < 11; i++)
13. std::cout << static_cast<char>(av[i]);
14. }](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-30-2048.jpg)
![1. #include <iostream>
2. #include <amp.h>
3. using namespace concurrency;
4. int main()
5. {
6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'};
7. array_view<int> av(11, v);
8. parallel_for_each(av.extent, [=](index<1> idx) restrict(amp)
9. {
10. av[idx] += 1; restrict(amp): tells the compiler to
11. }); check that code conforms to C++
subset, and tells compiler to target GPU
12. for(unsigned int i = 0; i < 11; i++)
13. std::cout << static_cast<char>(av[i]);
14. }](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-31-2048.jpg)
![1. #include <iostream>
2. #include <amp.h>
3. using namespace concurrency;
4. int main()
5. {
6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'};
7. array_view<int> av(11, v);
8. parallel_for_each(av.extent, [=](index<1> idx) restrict(amp)
9. {
10. av[idx] += 1; array_view: automatically copied
11. }); to accelerator if required
12. for(unsigned int i = 0; i < 11; i++)
13. std::cout << static_cast<char>(av[i]); array_view: automatically copied
14. } back to host when and if required](https://image.slidesharecdn.com/03devroom2blazingfastwindows8appstarekmadkour83-130320082258-phpapp01/75/Blazing-Fast-Windows-8-Apps-using-Visual-C-32-2048.jpg)

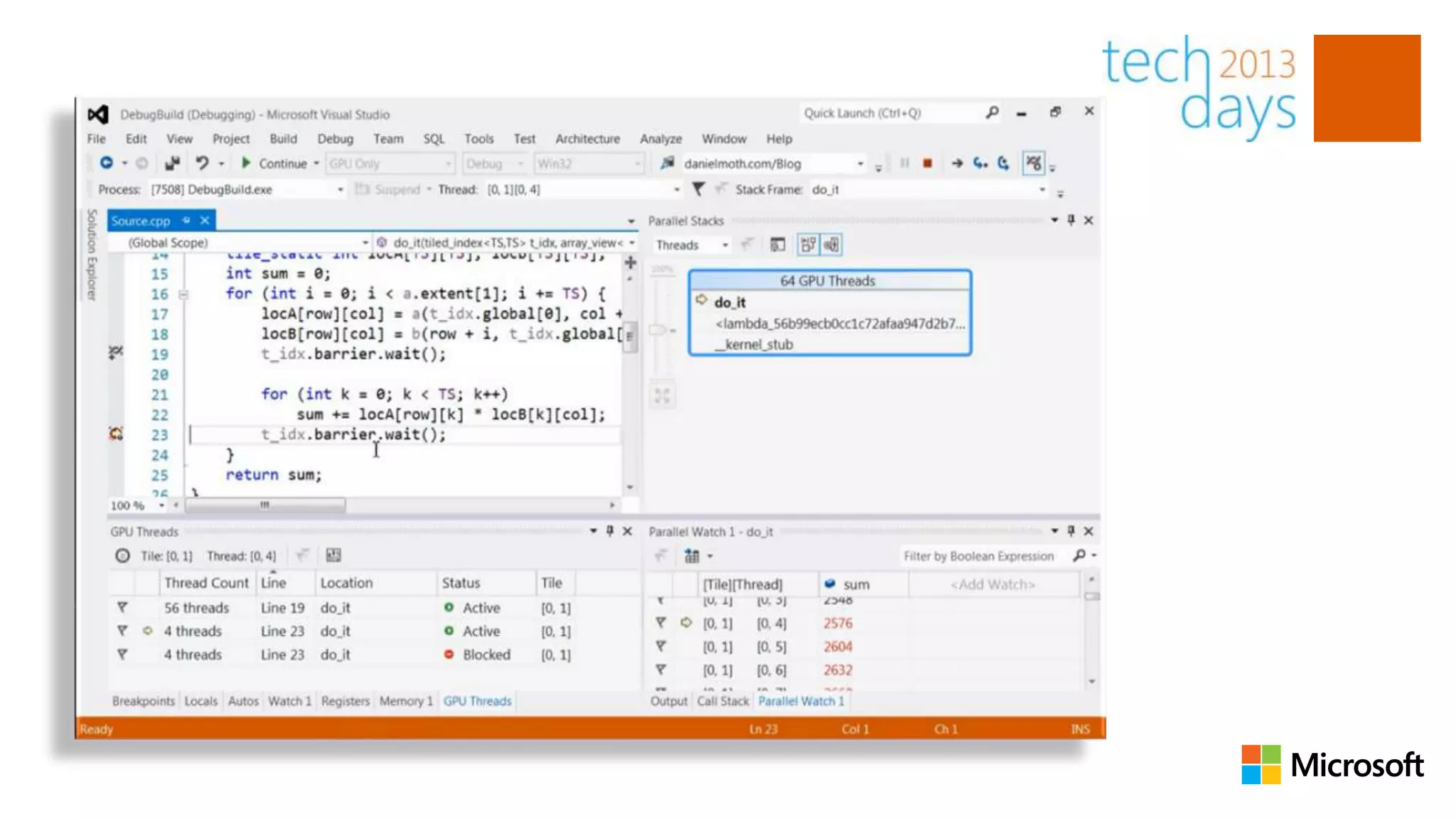



The document discusses using C++ Accelerated Massive Parallelism (AMP) to improve performance by offloading work to the GPU. It shows how to wrap array data in an array_view to make it accessible to the GPU, then use parallel_for_each to execute a lambda function that increments each element in parallel on the GPU. By leveraging the massive parallelism of the GPU, this operation can see significant performance gains over executing it solely on the CPU.