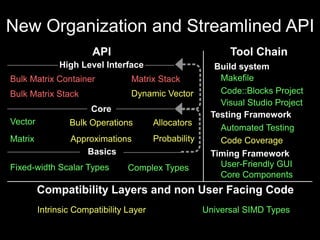
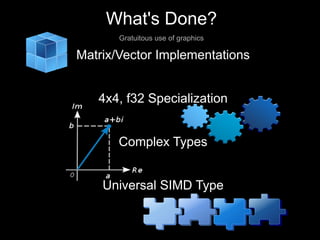
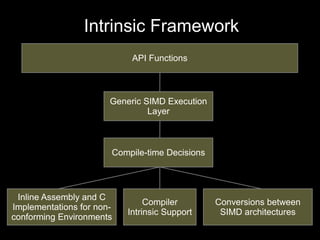
This document discusses the Adaptive Game Math Library. It provides an overview of the library's new organization and streamlined API, including high-level interfaces, core components, and tooling. The document also outlines current and upcoming functionality such as matrix/vector implementations, bulk operations, allocators, and a timing framework. Performance is optimized using SIMD intrinsics and support for multiple architectures. Future plans include porting to ARM and adding bulk matrix containers, stacks, and tutorials.








![void Rotate(GLfloat angle, GLfloat x, GLfloat y, GLfloat z) {
M3DMatrix44f mTemp, mRotate;
m3dRotationMatrix44(mRotate, float(m3dDegToRad(angle)), x, y, z);
m3dCopyMatrix44(mTemp, pStack[stackPointer]);
m3dMatrixMultiply44(pStack[stackPointer], mTemp, mRotate);
}
void rot(f32 x, f32 y, f32 z) { t1 = _mm_mul_ps(simd[0],t);
f32 b = cos(x), a = sin(x), d = cos(y), c = sin(y), H = -a*d;
f = cos(z), e = sin(z); t = _mm_set1_ps(E);
f32 cf = c*f, ae = a*e, be = b*e; t1 = _mm_add_ps(_mm_mul_ps(simd[1],t),t1
f32 A,B,C,D,E,F,H,I; C = ae-b*cf;
_v128 t0, t1, t2; t = _mm_set1_ps(H);
_v128 t; t1 = _mm_add_ps(_mm_mul_ps(simd[2],t),t1
A = d*f; F = be*c;
t = _mm_set1_ps(A); t = _mm_set1_ps(C);
D = -d*e; t2 = _mm_mul_ps(simd[0],t);
t0 = _mm_mul_ps(simd[0],t); F+= a*f;
t = _mm_set1_ps(D); t = _mm_set1_ps(F);
B = a*cf; t2 = _mm_add_ps(_mm_mul_ps(simd[1],t),t2
t0 = _mm_add_ps(_mm_mul_ps(simd[1],t),t0); I = b*d;
t = _mm_set1_ps(c); t = _mm_set1_ps(I);
E = b*f; t2 = _mm_add_ps(_mm_mul_ps(simd[2],t),t2
t0 = _mm_add_ps(_mm_mul_ps(simd[2],t),t0); simd[0] = t0;
E -= ae*c; simd[1] = t1;
t = _mm_set1_ps(B); simd[2] = t2;
B += be; }](https://image.slidesharecdn.com/8-7-2011agml-110709114628-phpapp01/85/8-7-2011-agml-10-320.jpg)














































![[Harvard CS264] 13 - The R-Stream High-Level Program Transformation Tool / Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/reservoirlabsharvard-presentation-110412184012-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















































