Download as PDF, PPTX
















![Approximate Quantile
21
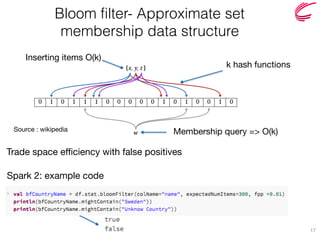
Spark 2: example code
Details are much more complicated than the above two. :)
res8: Array[Double] = Array(167543.0, 1260934.0, 3753121.0, 5643475.0)
Databrick example notebook:
https://docs.cloud.databricks.com/docs/latest/sample_applications/
04%20Apache%20Spark%202.0%20Examples/05%20Approximate%20Quantile.html](https://image.slidesharecdn.com/whatsnewinspark2-161027083444/85/What-s-new-in-spark-2-0-21-320.jpg)
![Structure Streaming [Alpha]
• SQL on streaming data
23
Source : https://databricks.com/blog/2016/07/28/structured-streaming-in-apache-spark.html
Databrick example notebook:
https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/
4012078893478893/295447656425301/5985939988045659/latest.html](https://image.slidesharecdn.com/whatsnewinspark2-161027083444/85/What-s-new-in-spark-2-0-23-320.jpg)
![Structure Streaming [Alpha]
24
Source: https://databricks.com/blog/2016/07/28/continuous-applications-evolving-
streaming-in-apache-spark-2-0.html
Not ready for production](https://image.slidesharecdn.com/whatsnewinspark2-161027083444/85/What-s-new-in-spark-2-0-24-320.jpg)


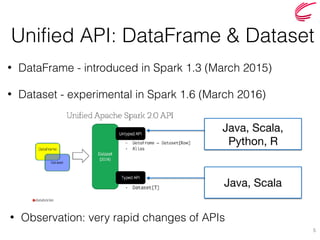
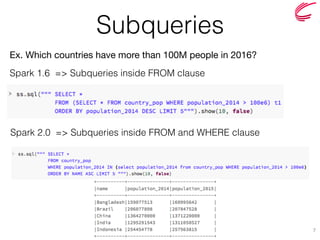
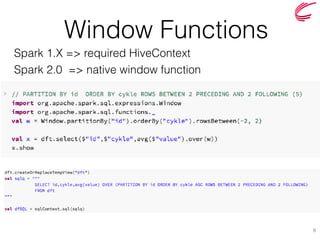
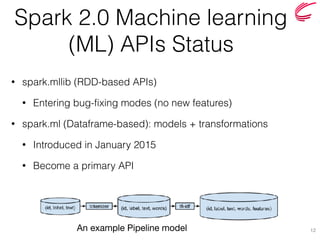
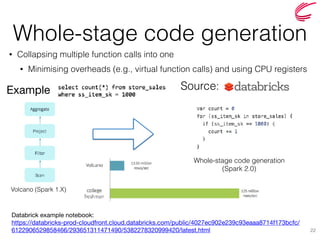
The document discusses the key features and improvements introduced in Apache Spark 2.0, including a unified API for dataset and dataframe, enhanced SQL capabilities, and advancements in machine learning pipelines. Notable additions are built-in CSV support, approximate dataframe statistics functions, and structured streaming. It emphasizes the efficiency and easier operation of Spark 2.0 compared to its previous versions.






































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)




