Download to read offline


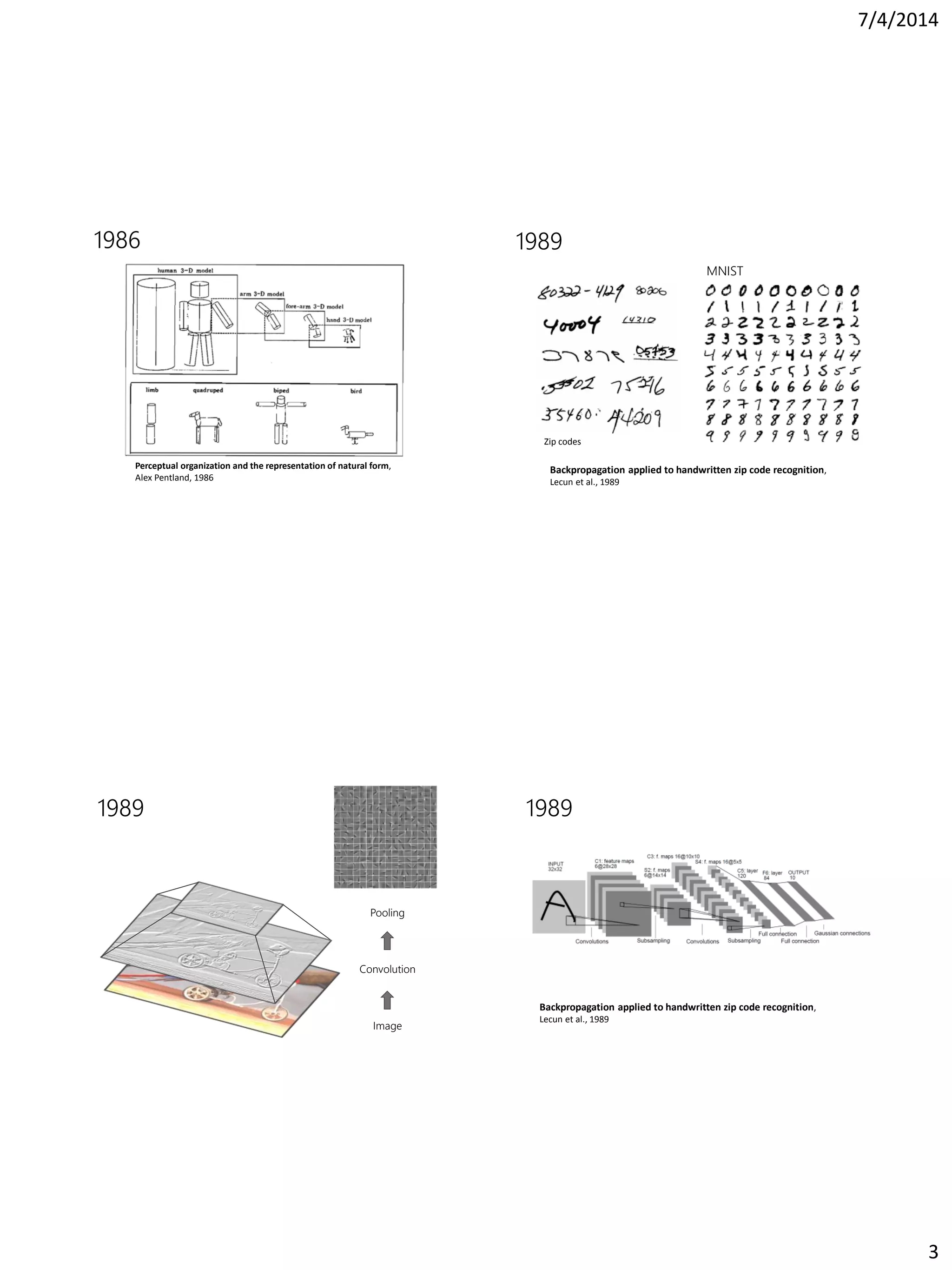














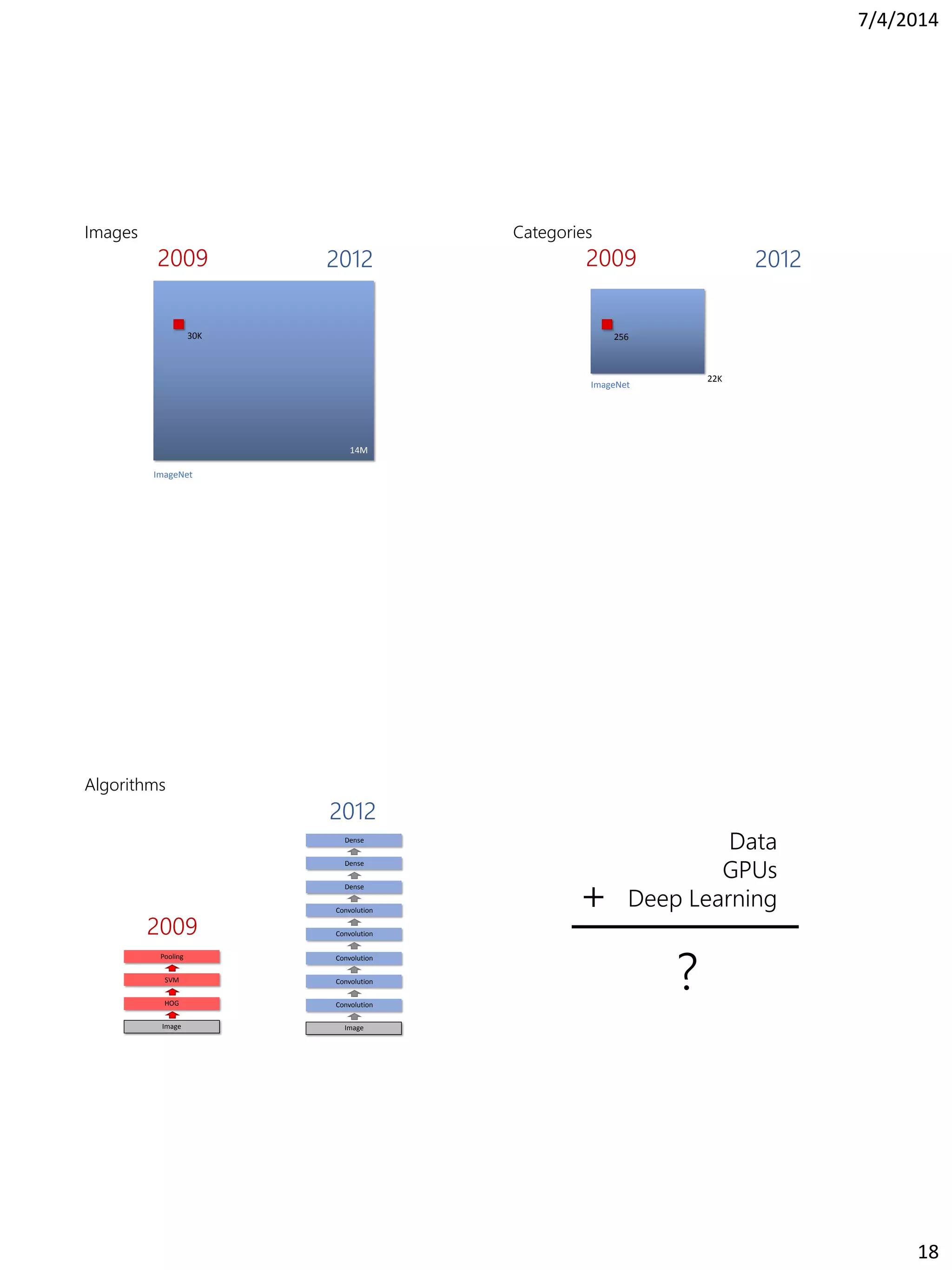
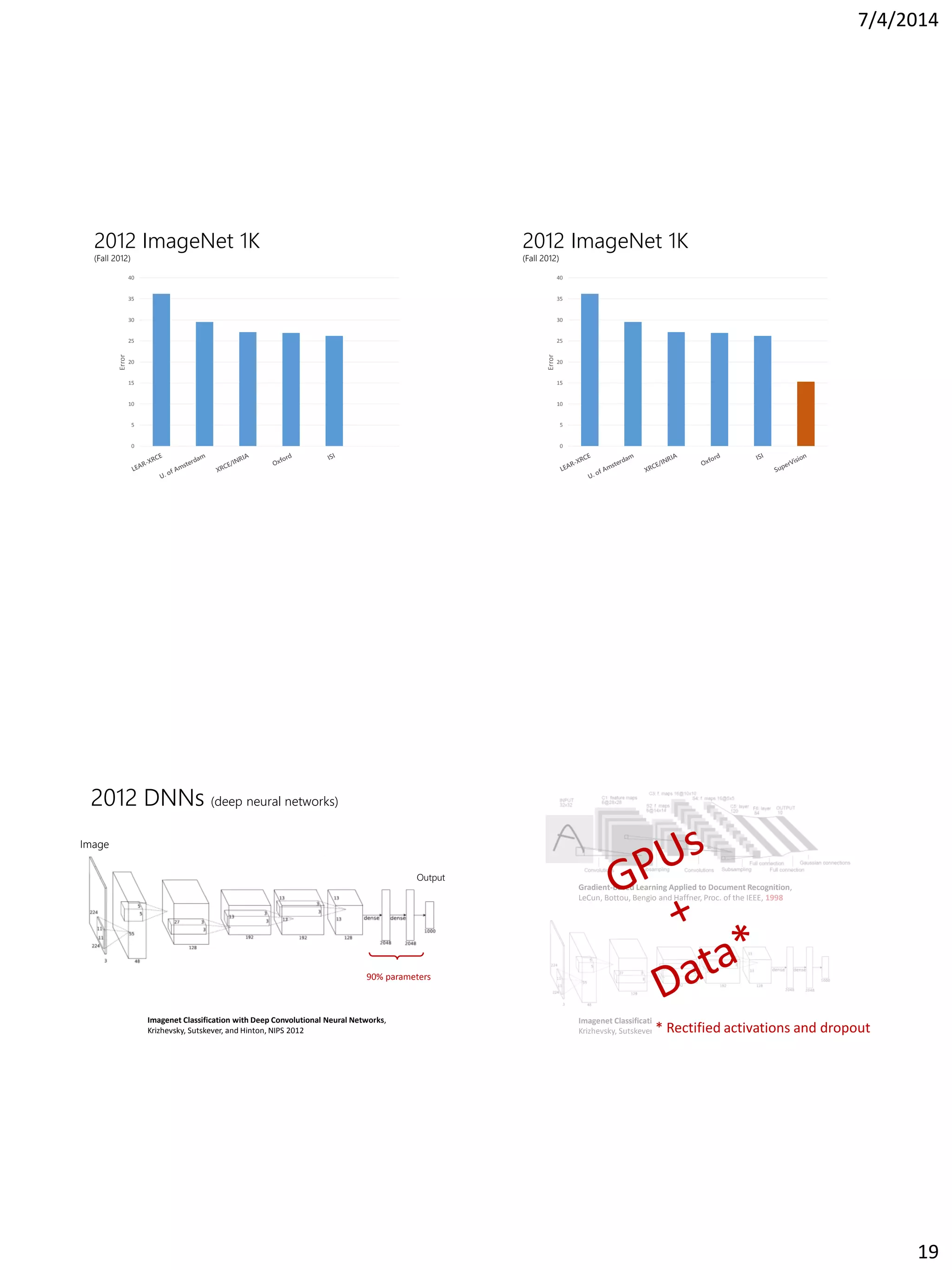








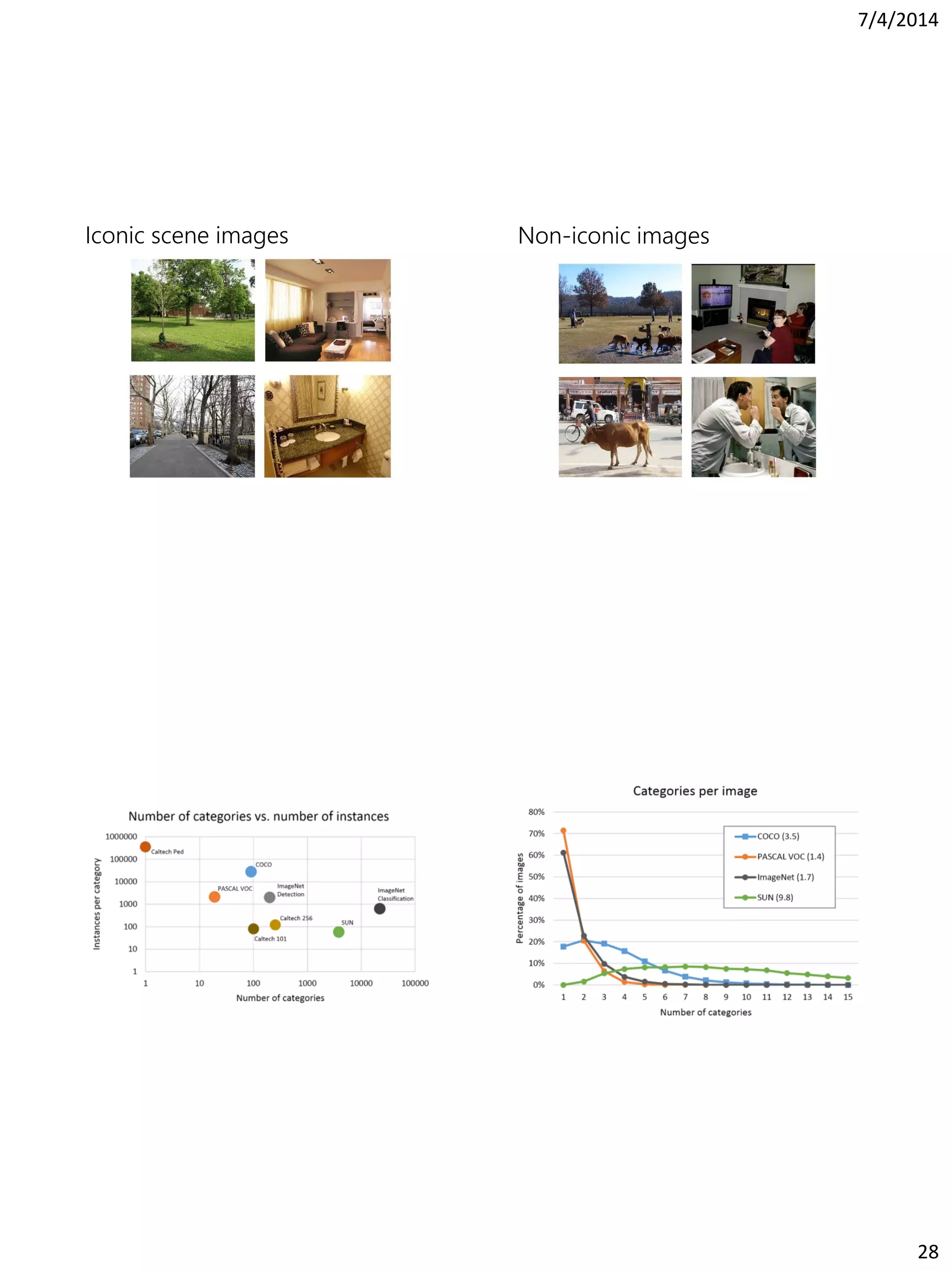














This document summarizes the history of computer vision and object recognition from the 1970s to the present. It discusses early works on edge detection and perceptual organization. It then covers major milestones like handwritten digit recognition using backpropagation, face detection, the SIFT feature descriptor, and object detection using HOG features and deformable part models. It notes the improvements brought by large datasets like ImageNet and algorithms like deep convolutional neural networks, which achieved breakthrough performance on ImageNet classification in 2012. It concludes by discussing challenges going forward like detection in context and generating rich image descriptions.



































































