Download to read offline


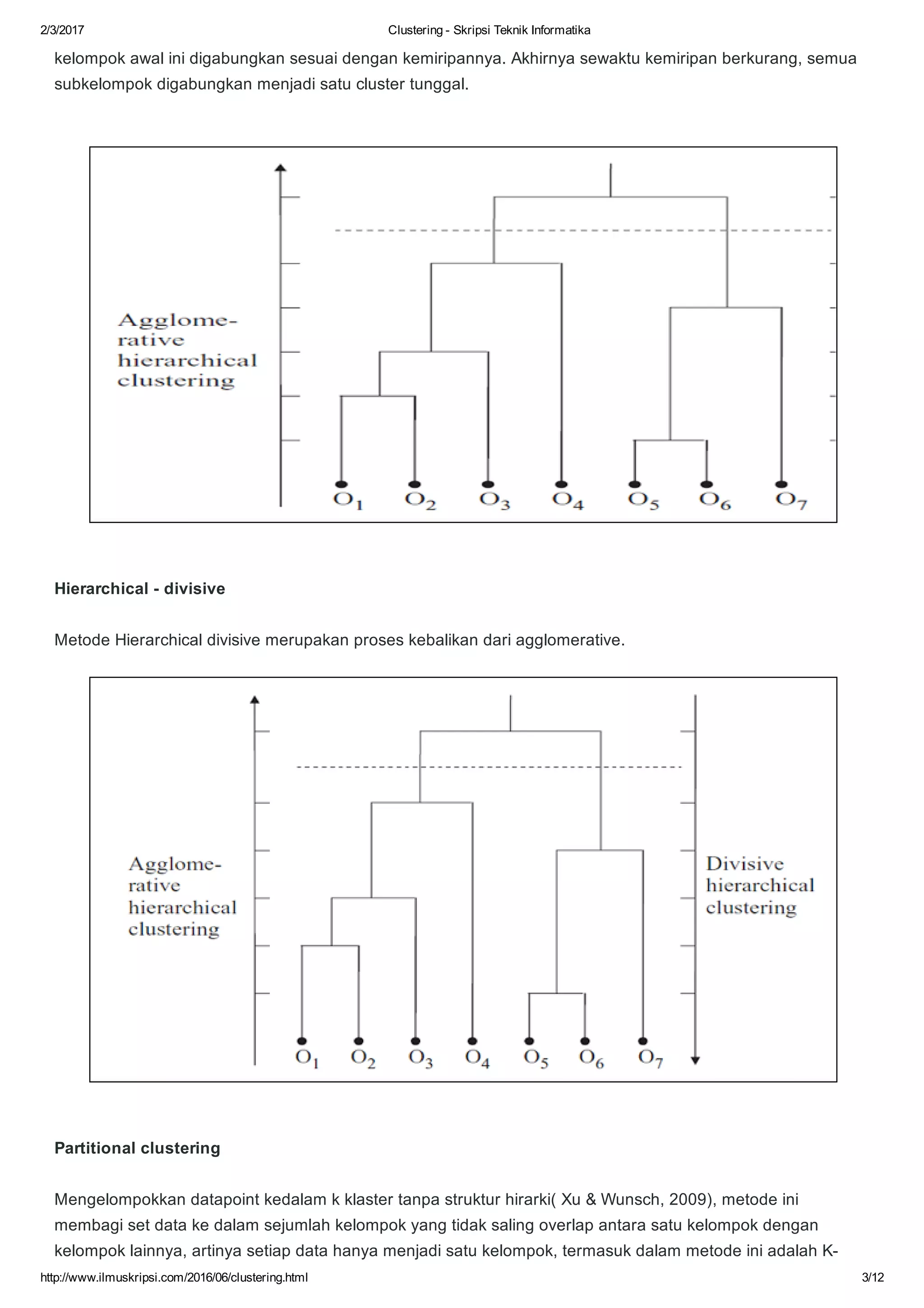



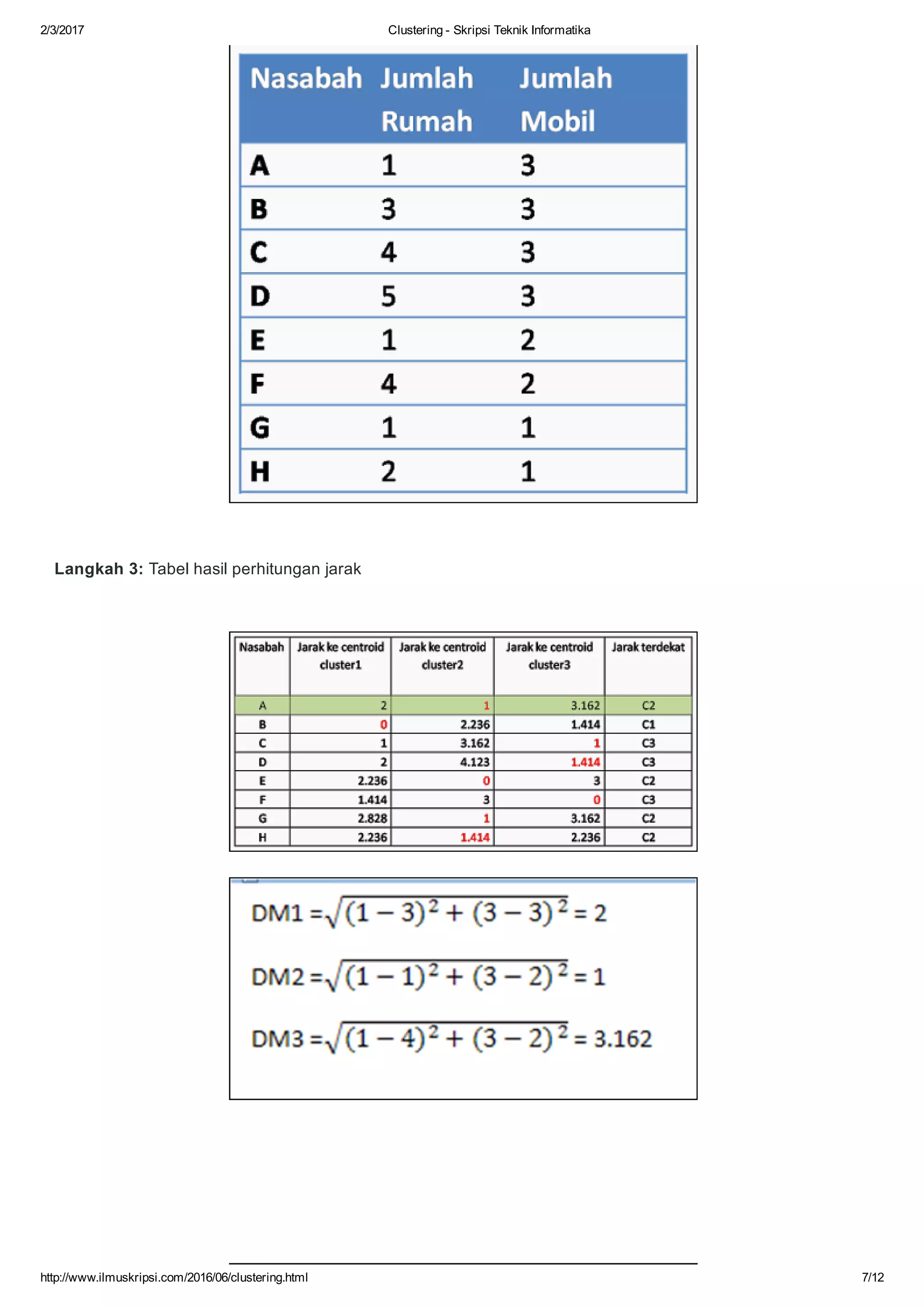
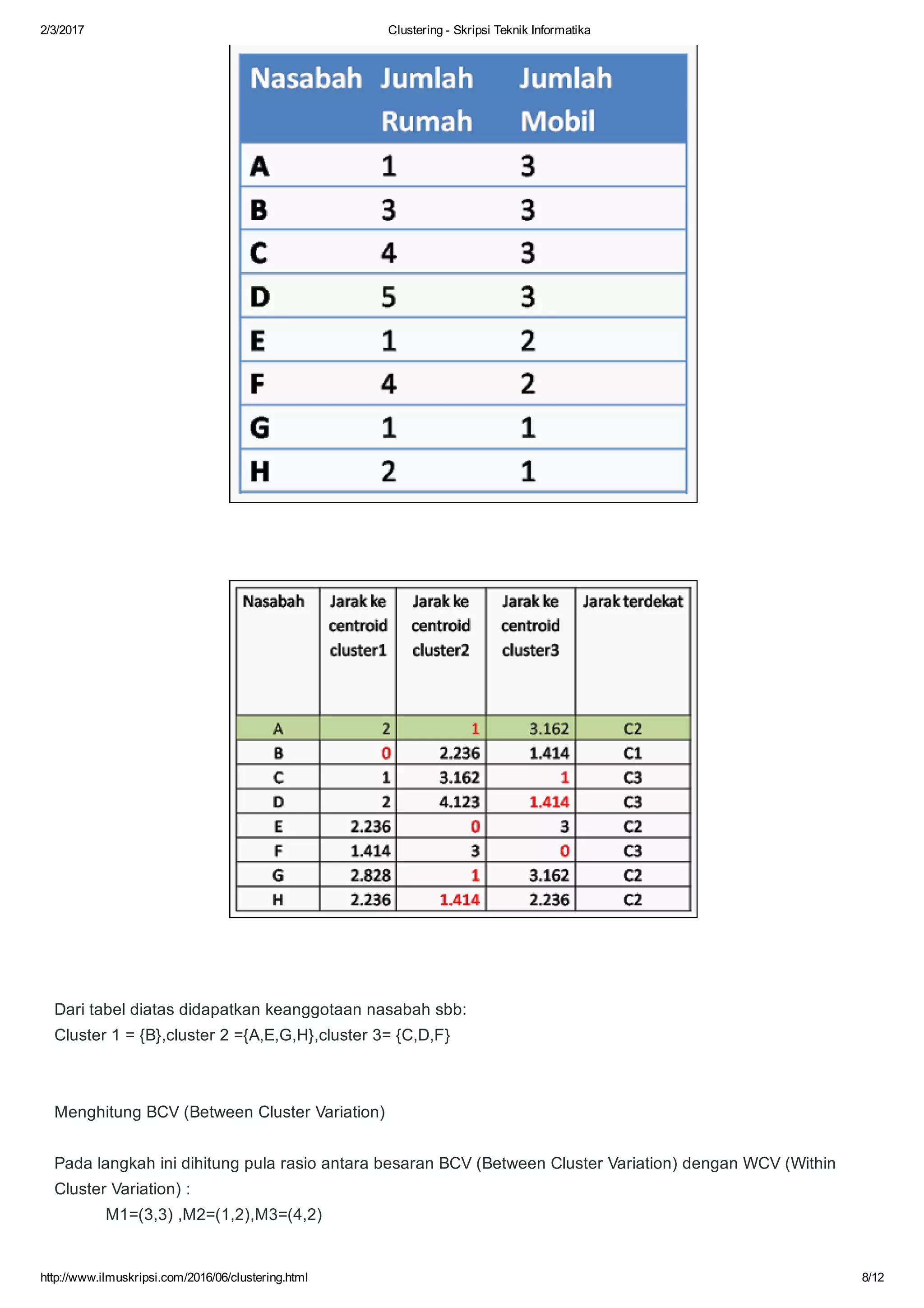
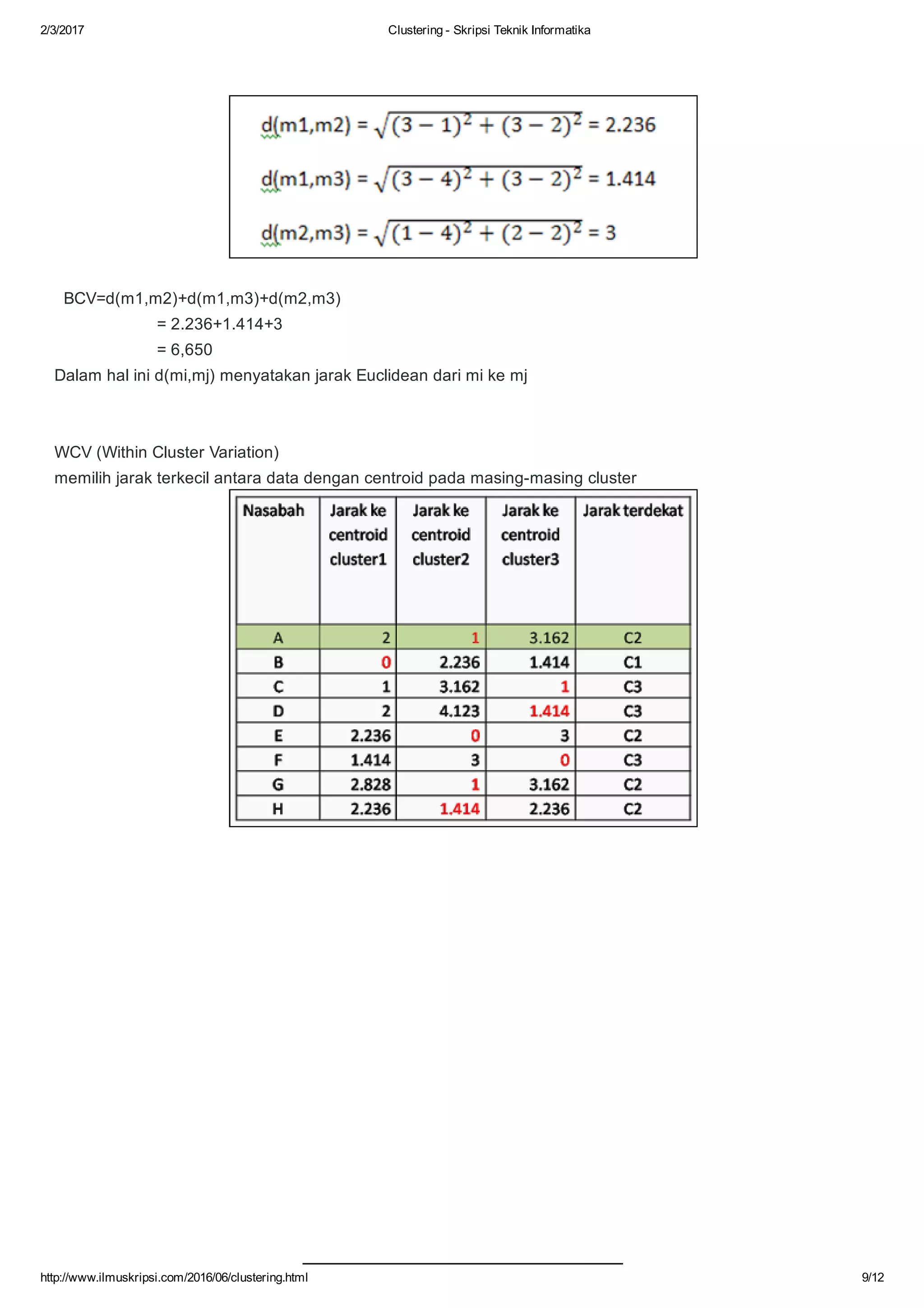
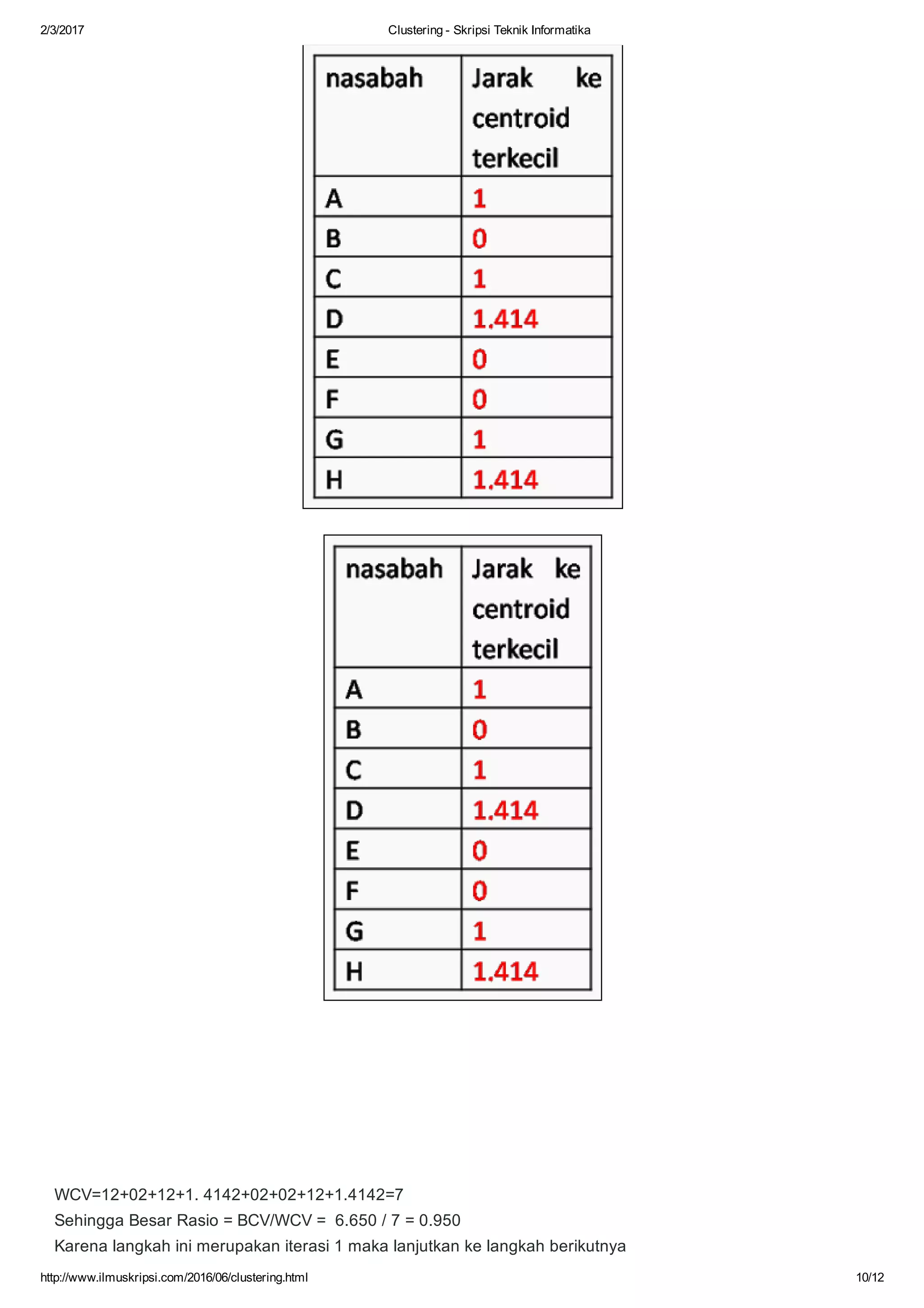



Dokumen ini membahas tentang algoritma clustering dalam data mining, mendefinisikan clustering sebagai pengelompokan entitas yang serupa dan membedakan mereka dari kelompok lain. Berbagai aplikasi clustering di berbagai bidang seperti biomedis, astronomi, dan analisis sosial serta tujuan dan jenis metode clustering seperti hierarchical dan k-means dijelaskan. Selain itu, algoritma k-means diuraikan secara mendetail, termasuk proses perhitungan jarak dan pembaruan centroid.