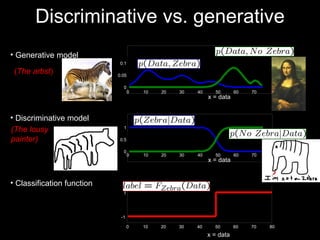
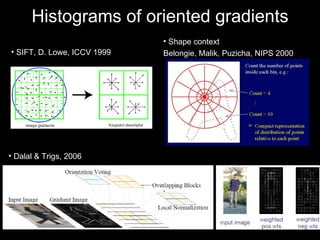
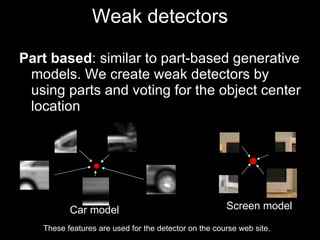
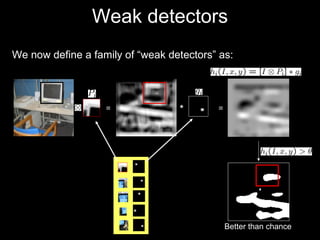
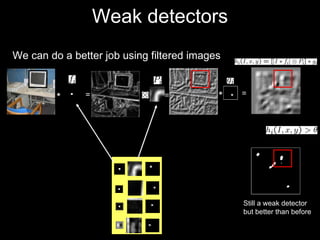
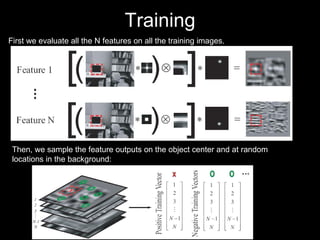
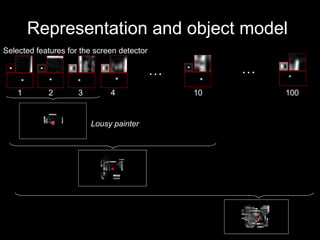
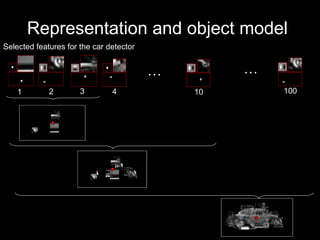
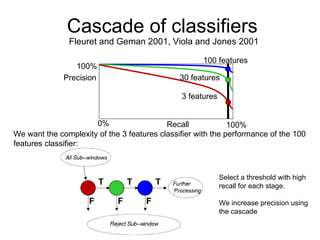
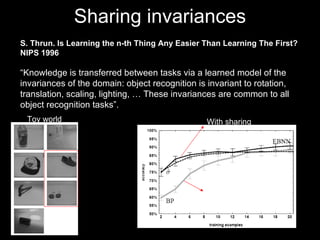
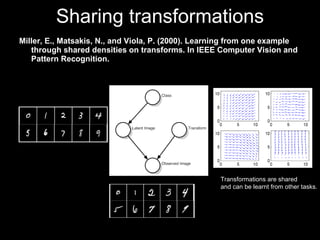
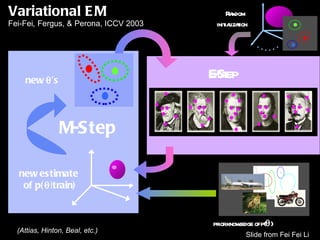
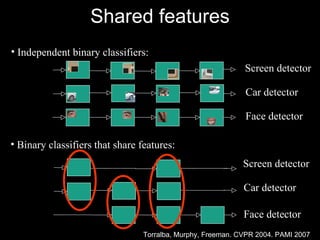
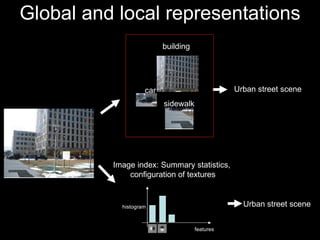
The document discusses classifier-based methods for object detection and recognition. It describes how object detection is formulated as a classification problem, with images partitioned into windows that are classified. Boosting algorithms like AdaBoost are used to combine weak classifiers into a strong joint classifier. A variety of weak classifiers based on image features like Haar wavelets and histograms of oriented gradients are presented. The strong classifier is used to detect objects by scanning the image at multiple scales.












![Weak classifiers The input is a set of weighted training samples (x,y,w) Regression stumps: simple but commonly used in object detection. Four parameters: b=E w (y [x> ]) a=E w (y [x< ]) x f m (x) ](https://image.slidesharecdn.com/cvpr2007objectcategoryrecognition-p3-discriminativemodels-110514214032-phpapp02/85/Cvpr2007-object-category-recognition-p3-discriminative-models-15-320.jpg)


























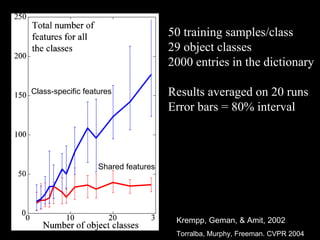
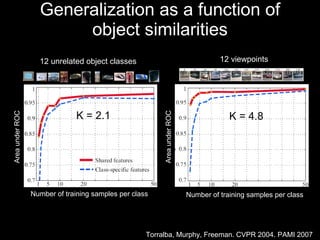
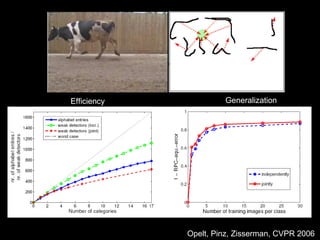









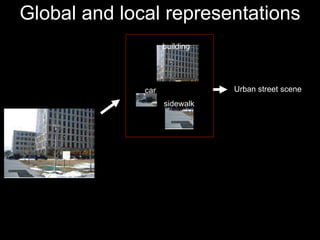

![3d Scene Context Image World [Hoiem, Efros, Hebert ICCV 2005]](https://image.slidesharecdn.com/cvpr2007objectcategoryrecognition-p3-discriminativemodels-110514214032-phpapp02/85/Cvpr2007-object-category-recognition-p3-discriminative-models-72-320.jpg)
![3d Scene Context Image Support Vertical Sky V-Left V-Center V-Right V-Porous V-Solid [Hoiem, Efros, Hebert ICCV 2005] Object Surface? Support?](https://image.slidesharecdn.com/cvpr2007objectcategoryrecognition-p3-discriminativemodels-110514214032-phpapp02/85/Cvpr2007-object-category-recognition-p3-discriminative-models-73-320.jpg)

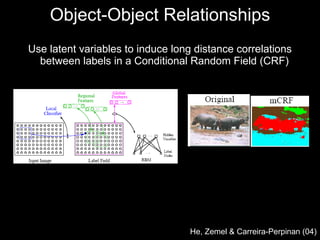

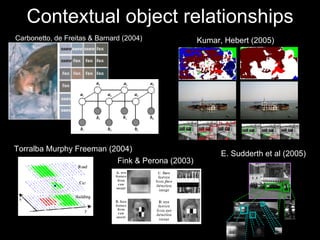
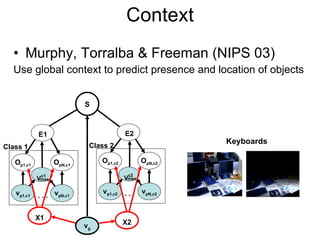
![CRFs Object-Object Relationships [Torralba Murphy Freeman 2004] [Kumar Hebert 2005]](https://image.slidesharecdn.com/cvpr2007objectcategoryrecognition-p3-discriminativemodels-110514214032-phpapp02/85/Cvpr2007-object-category-recognition-p3-discriminative-models-77-320.jpg)

































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










