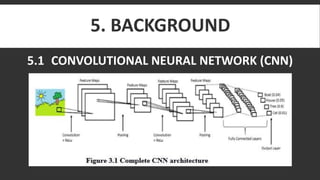
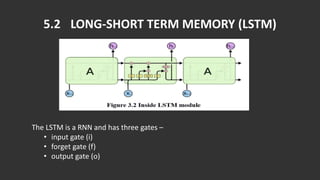
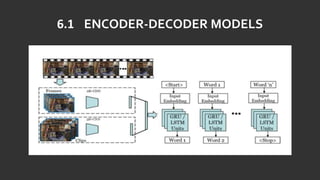
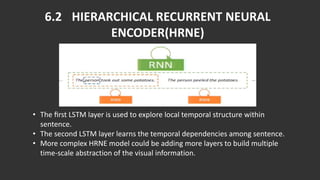
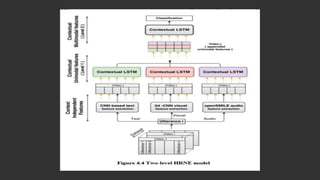
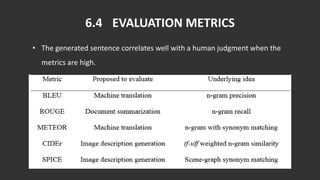
The document discusses the process of automatically generating natural language descriptions for videos using deep learning techniques, focusing on challenges and advancements in video description tasks. It details a system that employs diverse models like CNNs and LSTMs to extract features and produce coherent outputs, along with a literature survey of previous methodologies. The advantages, limitations, and system requirements are outlined, concluding that the hierarchical model overcomes issues in processing temporal structures in videos.















![REFERENCES
[1] N. Krishnamoorthy, G. Malkarnenkar, R. J. Mooney, K. Saenko, and S. Guadarrama.
Generating natural-language video descriptions using text-mined knowledge. In AAAI, July
2013.
[2] Z. Wu, T. Yao, Y. Fu, and Y. Jiang. Deep learning for video classification and captioning. In S.
hang, editor, Frontiers of Multimedia Research, pages 3–29. ACM Books, 2018
[3] S Olivastri, G Singh, F Cuzzolin. End-to-End Video Captioning. In Large Scale Holistic Video
Understanding, ICCVW 2019
[4] Pan, Boxiao & Cai, Haoye & Huang, De-An & Lee, Kuan-Hui & Gaidon, Adrien & Adeli, Ehsan
& Niebles, Juan Carlos. Spatio-Temporal Graph for Video Captioning with Knowledge
Distillation. Computer Vision and Pattern Recognition (CVPR),2020
[5] Lijun Li and Boqing Gong. End-to-end video captioning with multitask reinforcement
learning. arXiv preprint arXiv:1803.07950, 2018.](https://image.slidesharecdn.com/seminarpptformatted-200718124142/85/Video-Description-using-Deep-Learning-21-320.jpg)
![[6] Yuling Gui, Dan Guo, Ye Zhao. Semantic Enhanced Encoder-Decoder Network (SEN) for
Video Captioning. In MAHCI '19 2019
[7] K. Simonyan, A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image
Recognition. In International Conference on Learning Representations, 2015
[8] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, Learning Spatiotemporal Features
with 3D Convolutional Networks, ICCV 2015
[9] Nayyer Aafaq, Ajmal Mian, Wei Liu, Syed Zulqarnain Gilani, and Mubarak Shah. Video
Description: A Survey of Methods, Datasets and Evaluation Metrics. In ACM Computing Surveys
(CSUR),2019
[10] Pingbo Pan, Zhongwen Xu, Yi Yang, Fei Wu, Yueting Zhuang. Hierarchical Recurrent Neural
Encoder for Video Representation with Application to Captioning. In IEEE Conference on
Computer Vision and Pattern Recognition (CVPR)](https://image.slidesharecdn.com/seminarpptformatted-200718124142/85/Video-Description-using-Deep-Learning-22-320.jpg)




























































