Download to read offline



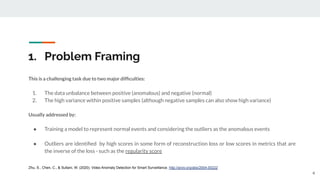



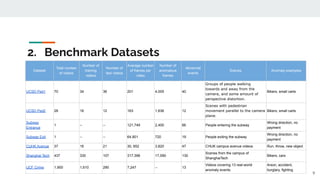

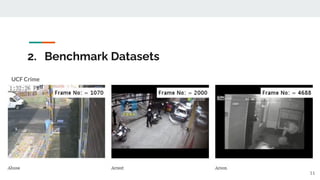





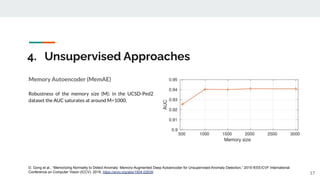


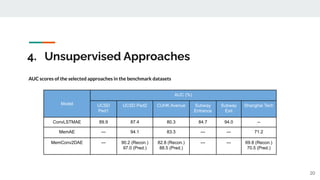
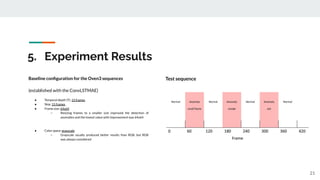
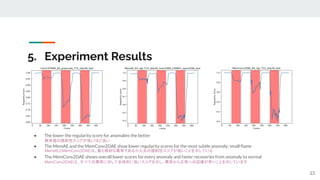
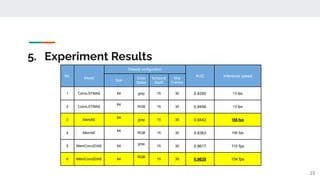
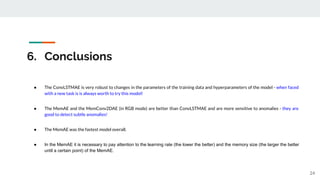


The presentation provided an overview of unsupervised video anomaly detection techniques. It discussed benchmark datasets, approaches like convolutional LSTM autoencoders, memory-augmented autoencoders, and memory-augmented convolutional autoencoders. Experiments on these approaches were conducted on standard datasets and a new oven dataset. The memory-augmented convolutional autoencoder achieved the best performance, being more sensitive to anomalies while maintaining fast inference speed. The presentation concluded with recommendations on the discussed techniques.

















![[DL輪読会]Variational Autoencoder with Arbitrary Conditioning](https://cdn.slidesharecdn.com/ss_thumbnails/190412nonakadlhacksv2-190422075347-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Generative Models of Visually Grounded Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20170602-170602005505-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NS][Lab_Seminar_250203]KAG-prompt (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250203kag-prompt1-250203110738-340efeca-thumbnail.jpg?width=640&height=640&fit=bounds)














![Anomaly Detection with VAEGAN and Attention [JSAI2019 report]](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2019report-190612095817-thumbnail.jpg?width=640&height=640&fit=bounds)



























