Download as PDF, PPTX



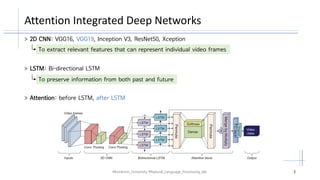

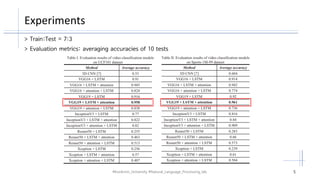



The document discusses the integration of attention mechanisms into deep networks for video classification, utilizing convolutional neural networks (CNN) and long short-term memory (LSTM) models. It presents experiments conducted on datasets such as UCF101 and Sports-1M, highlighting evaluation metrics and network hyper-parameters. The findings suggest that attention mechanisms improve accuracy and that VGG19 is optimal for integration due to its low dimensions.


































![[2A4]DeepLearningAtNAVER](https://cdn.slidesharecdn.com/ss_thumbnails/2a4deeplearningatnaver-140929210707-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[0114]hyun wook](https://cdn.slidesharecdn.com/ss_thumbnails/0114hyunwook-200316022403-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Impl] neural machine translation](https://cdn.slidesharecdn.com/ss_thumbnails/implneuralmachinetranslation-191030053355-thumbnail.jpg?width=640&height=640&fit=bounds)






























