Download as PDF, PPTX





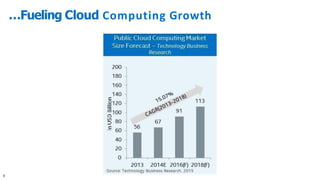
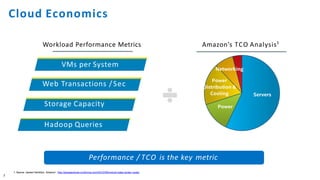


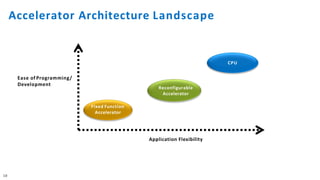
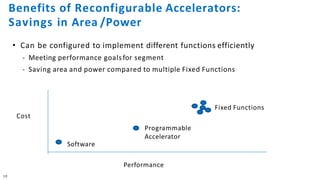


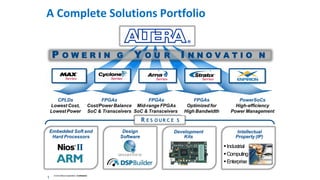
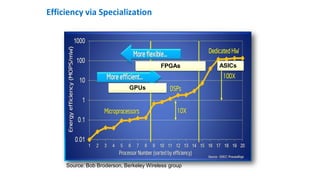



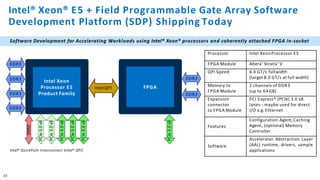
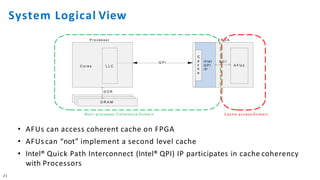
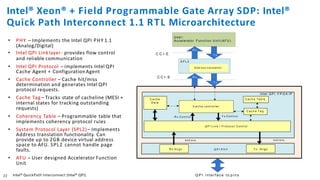

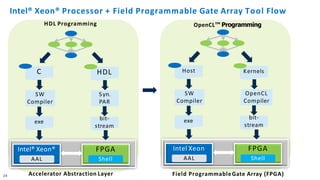
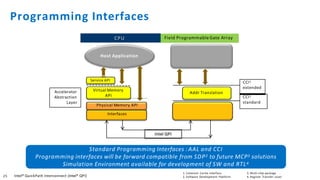
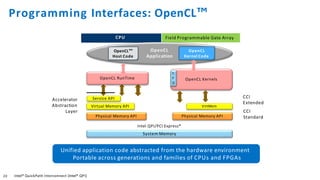

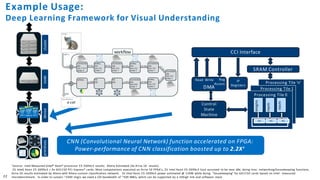
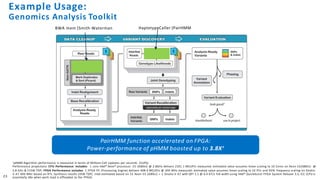
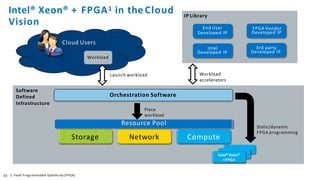
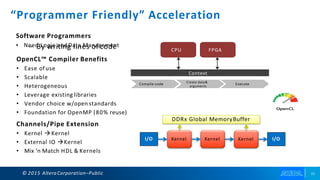
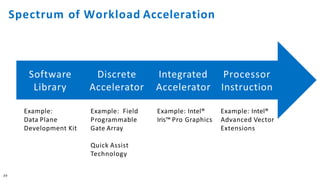




The document discusses the integration of Intel Xeon processors with field programmable gate arrays (FPGAs) to enhance computing performance and reduce total cost of ownership for specific workloads. It outlines the benefits of FPGAs, including their reprogrammability and efficiency compared to custom-designed chips, and highlights use cases in areas like deep learning and genomics. Additionally, it addresses various risk factors and uncertainties related to Intel's product offerings and market conditions.











































































































