






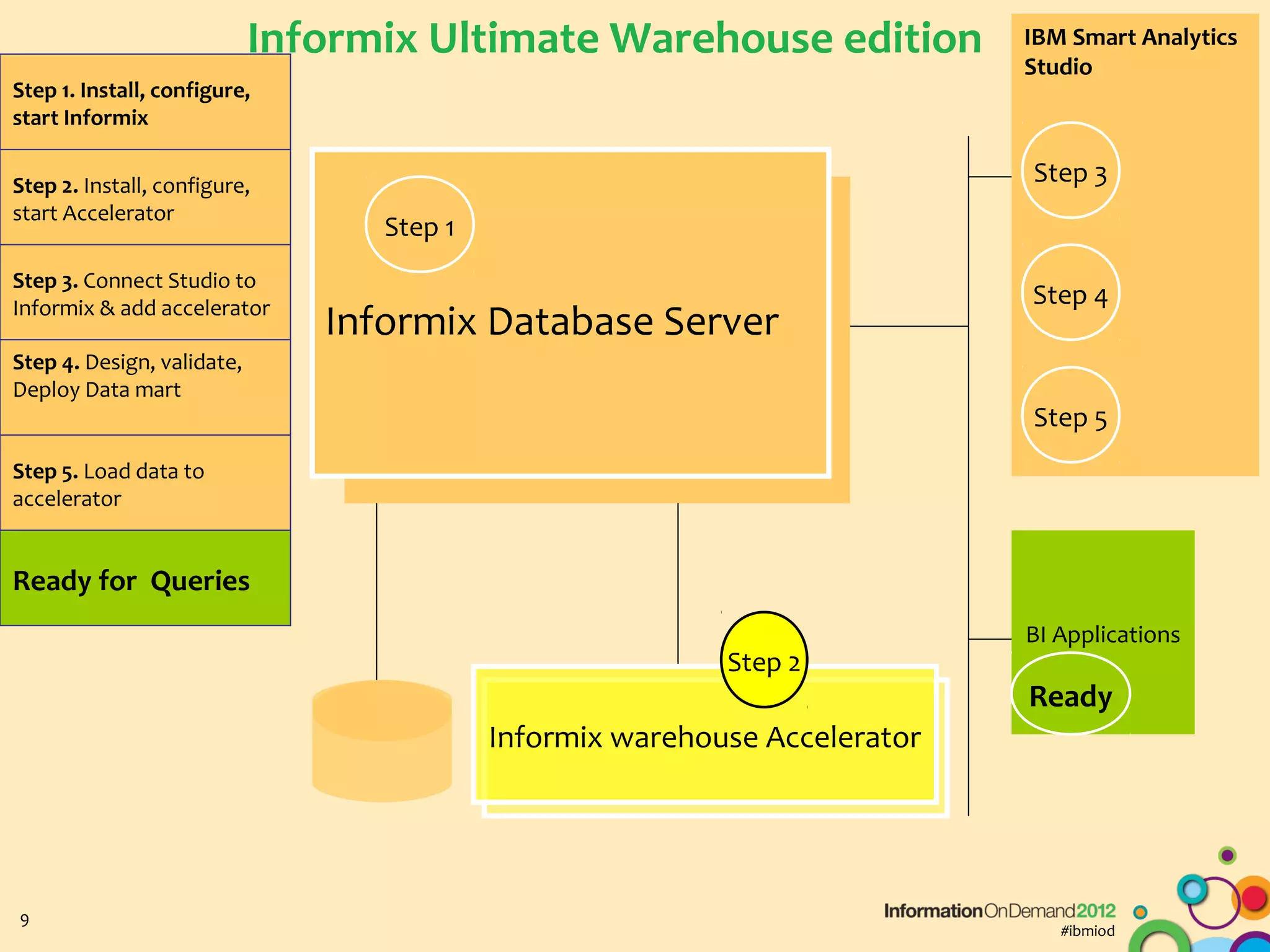
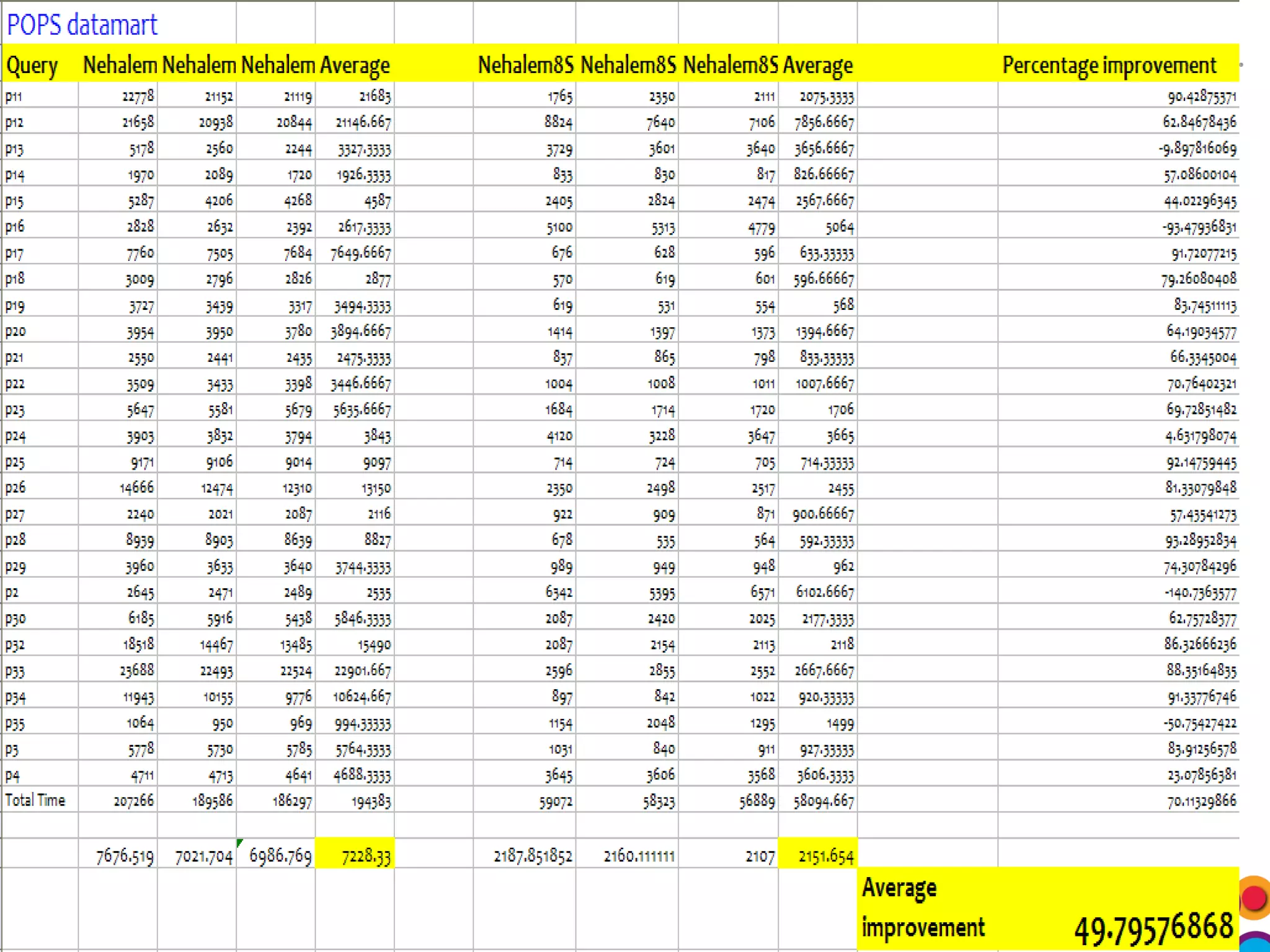
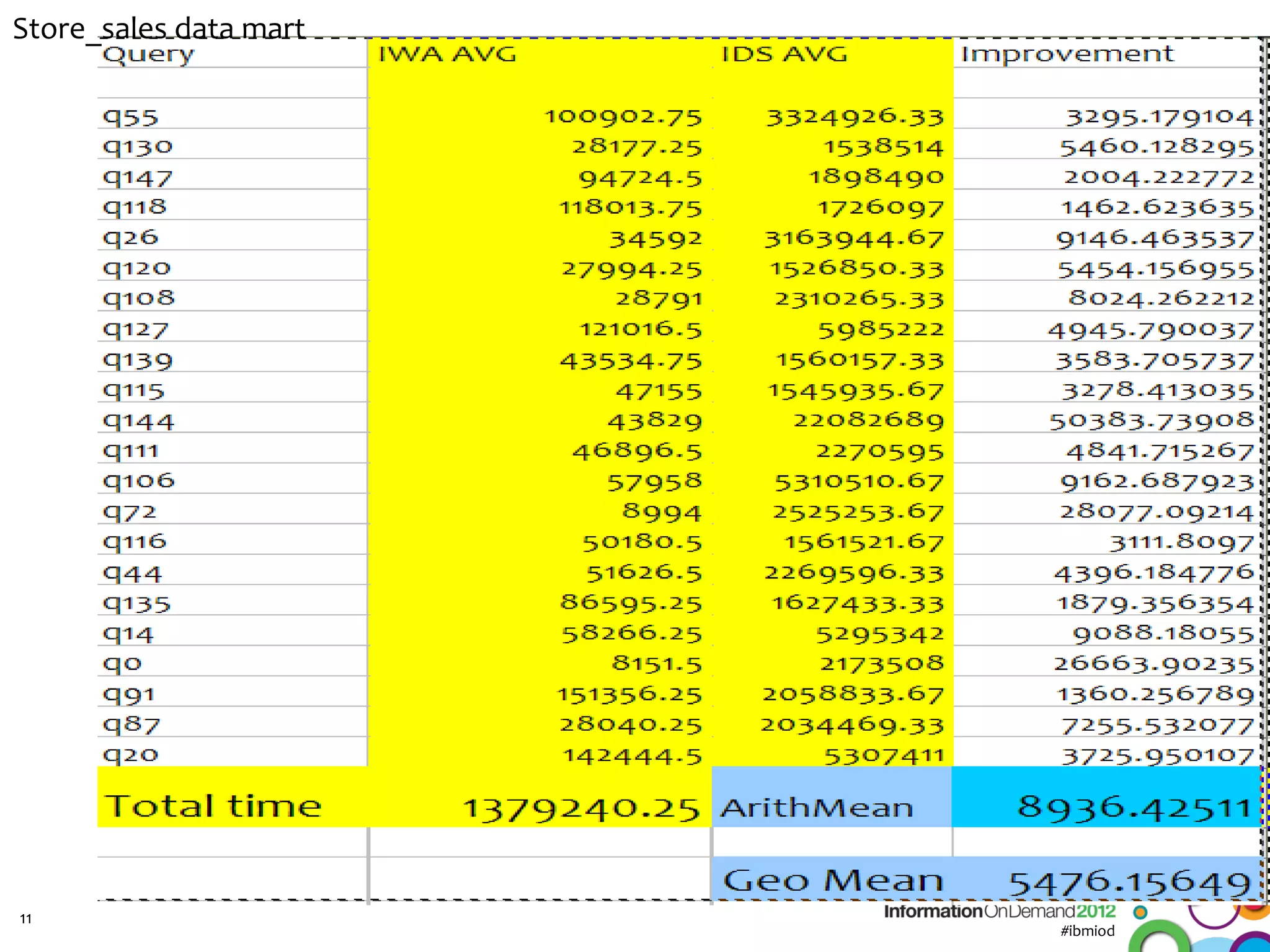

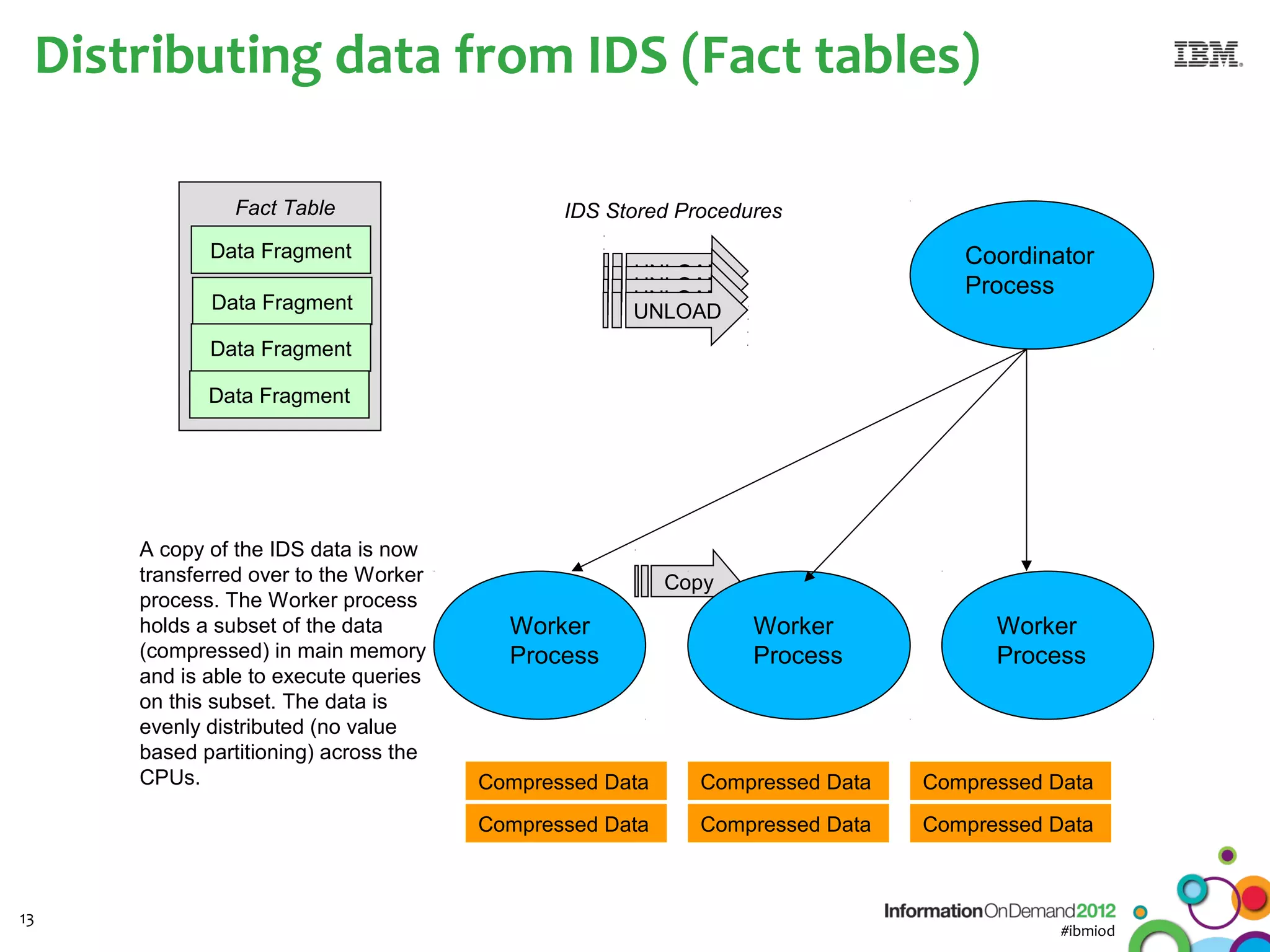
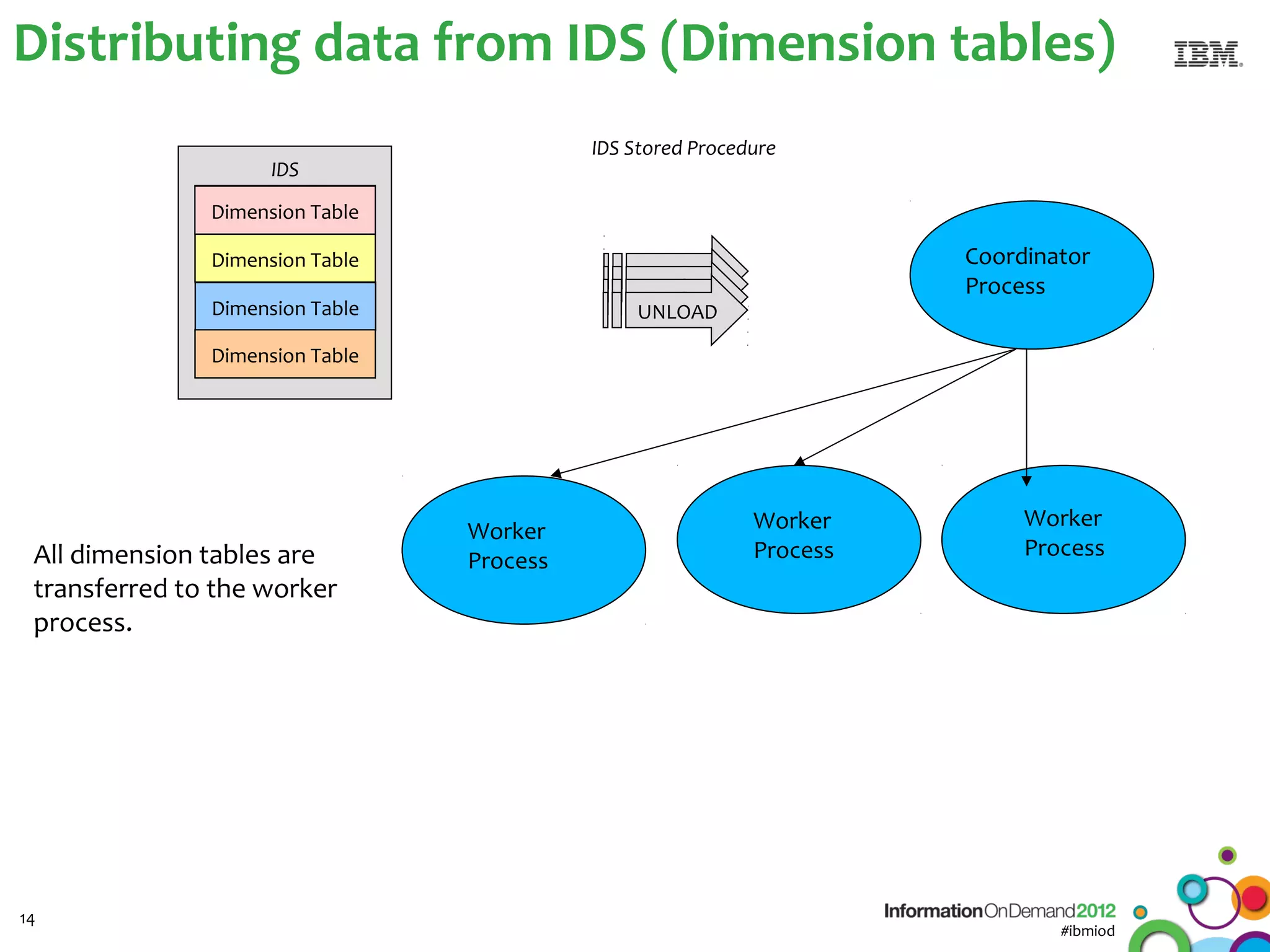
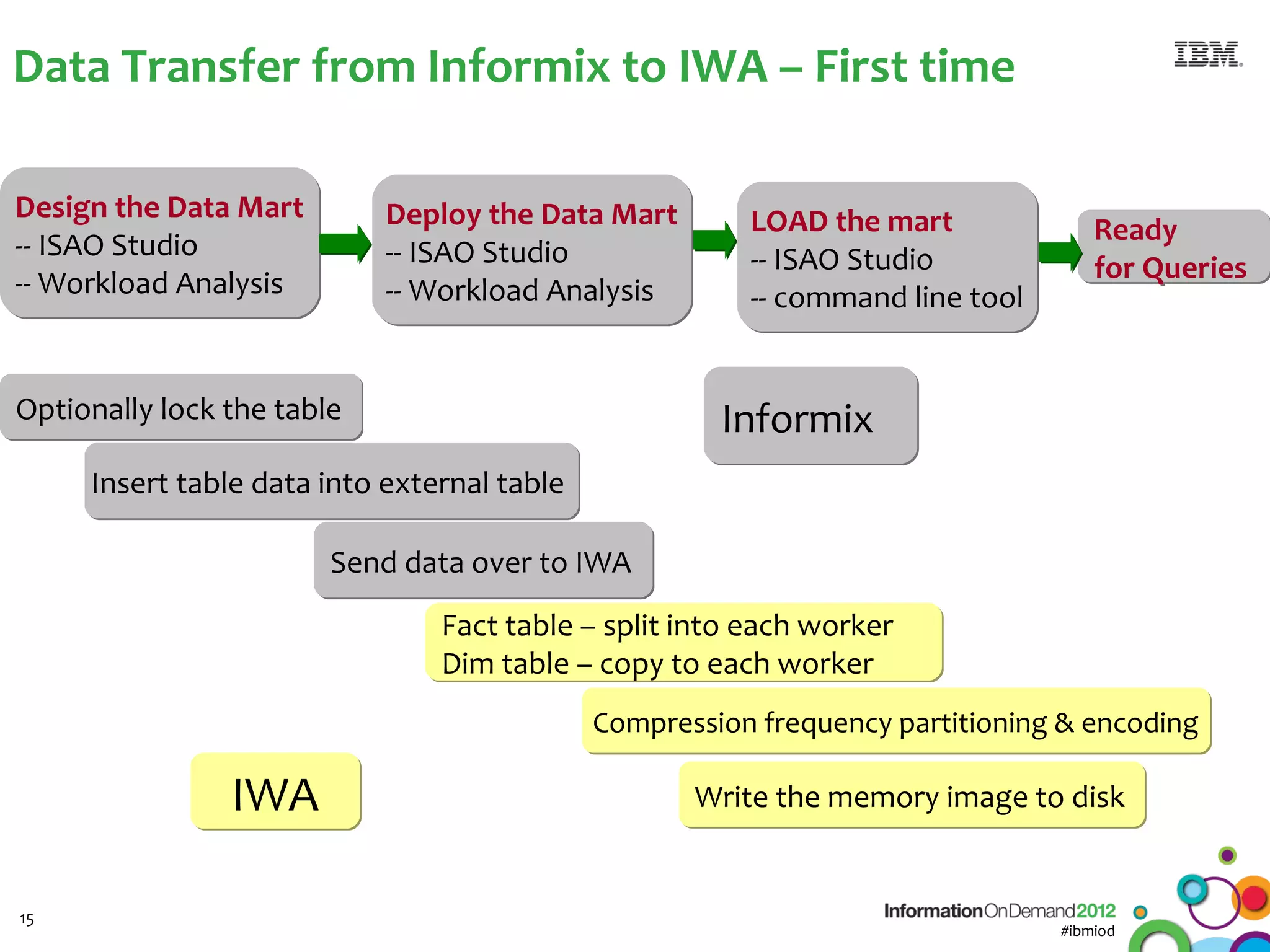
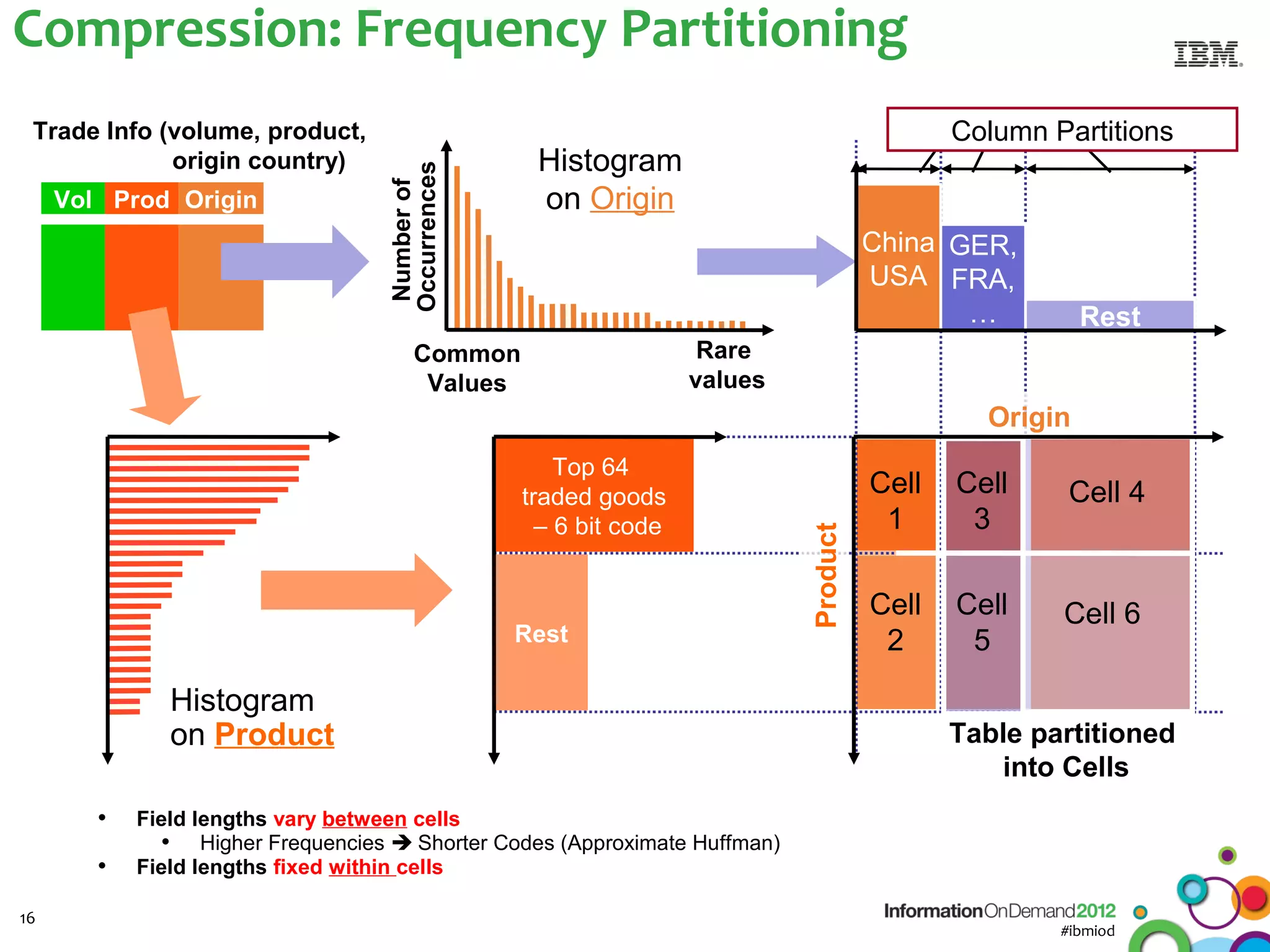

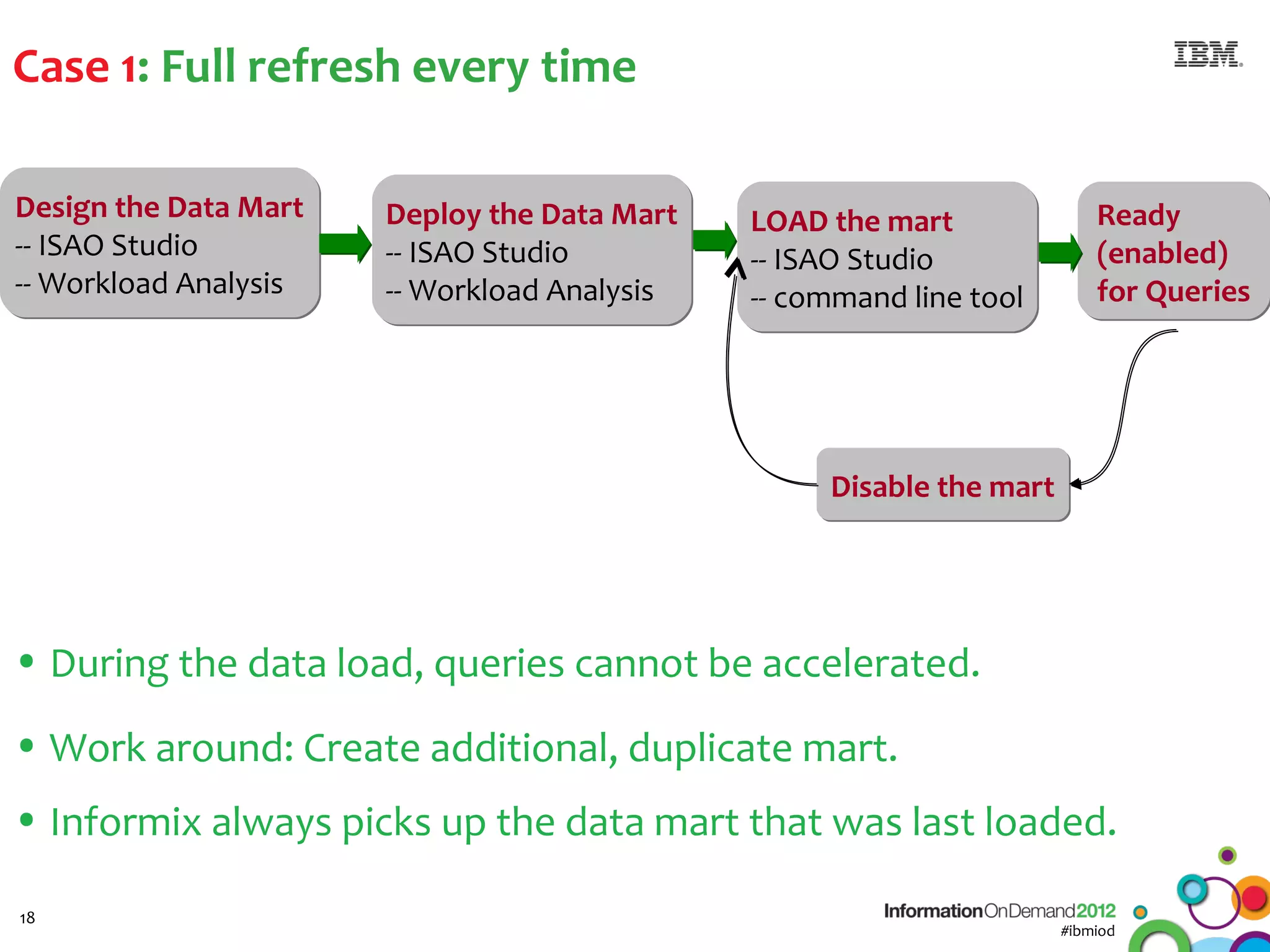
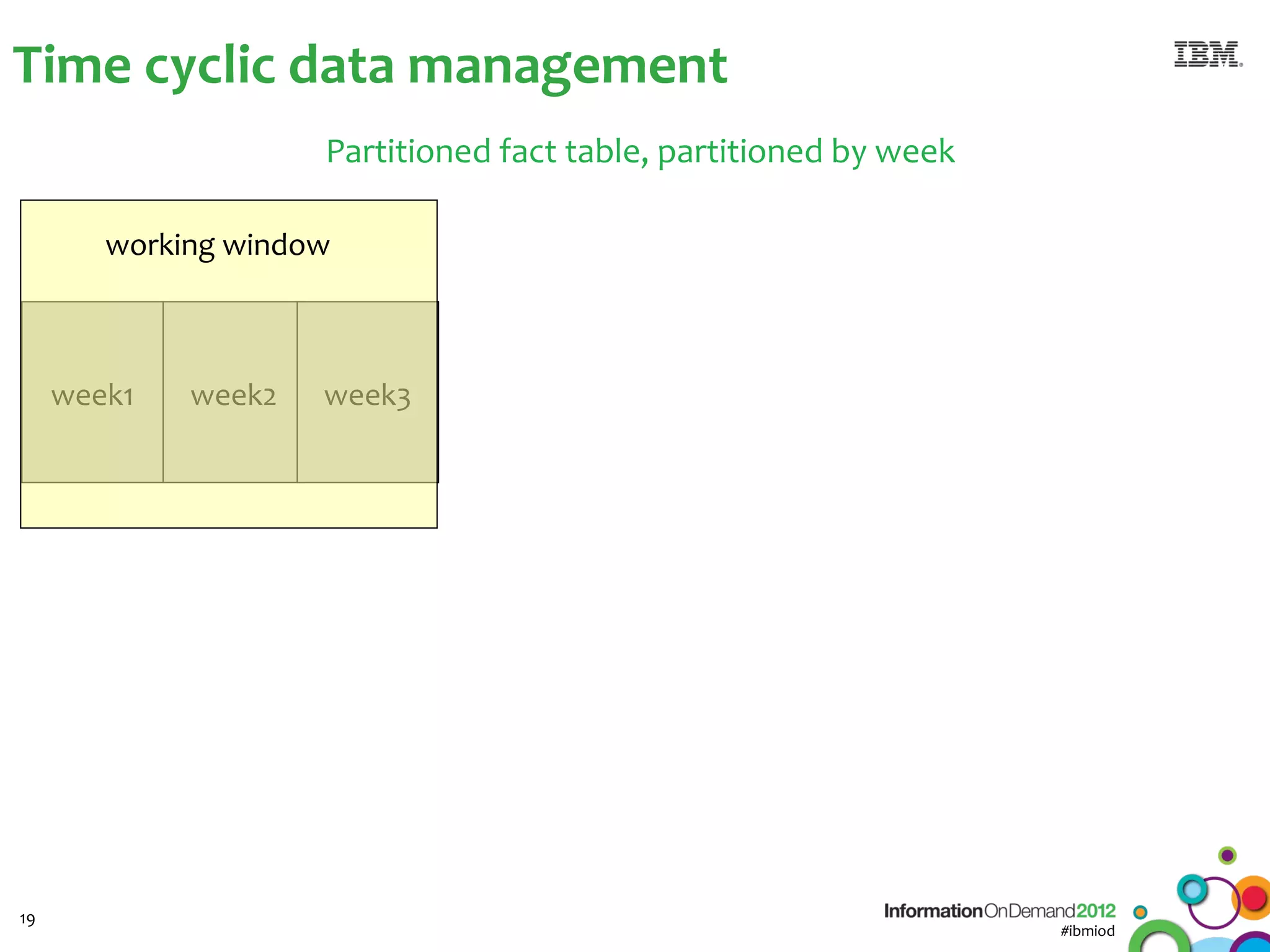
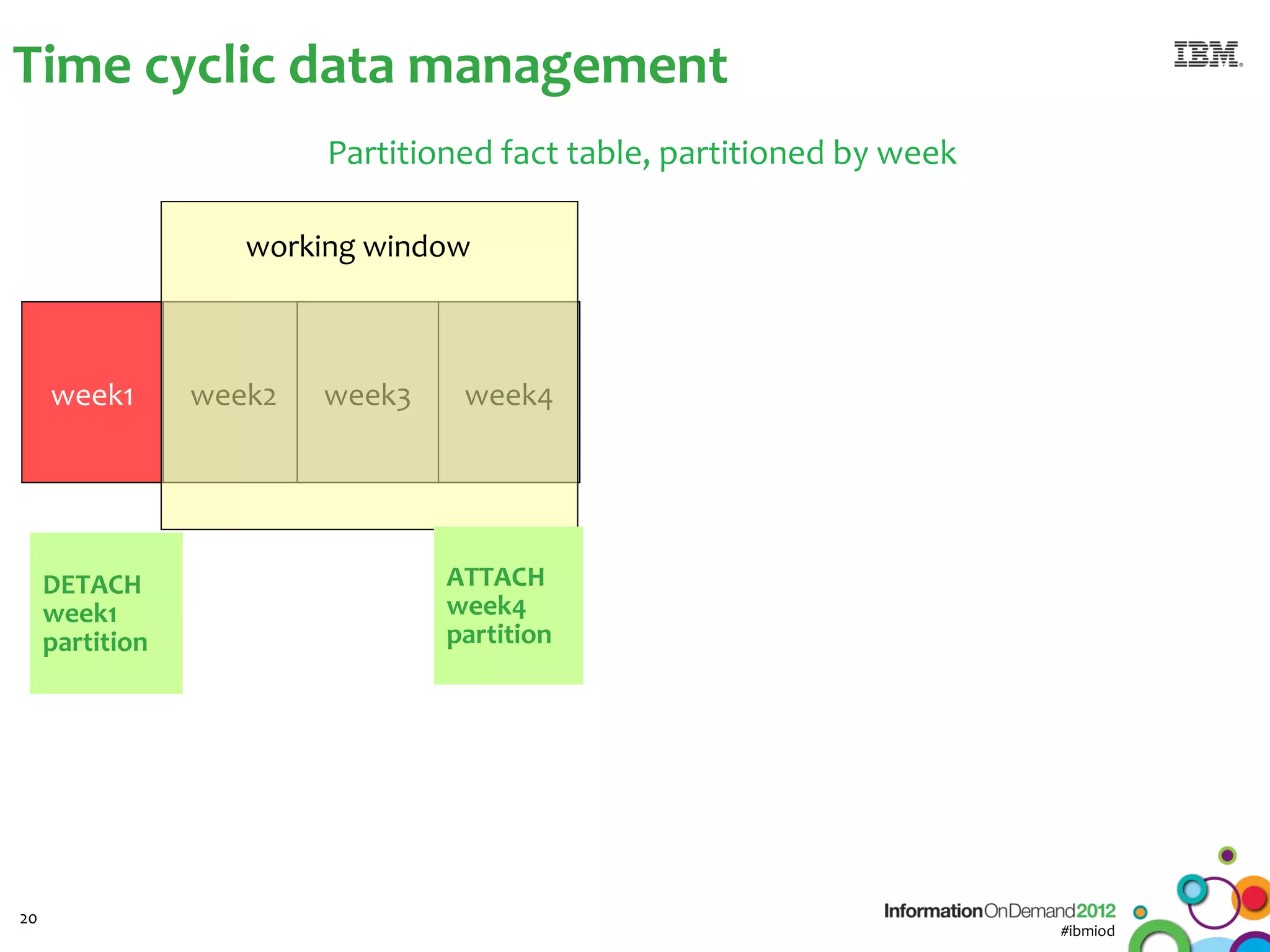
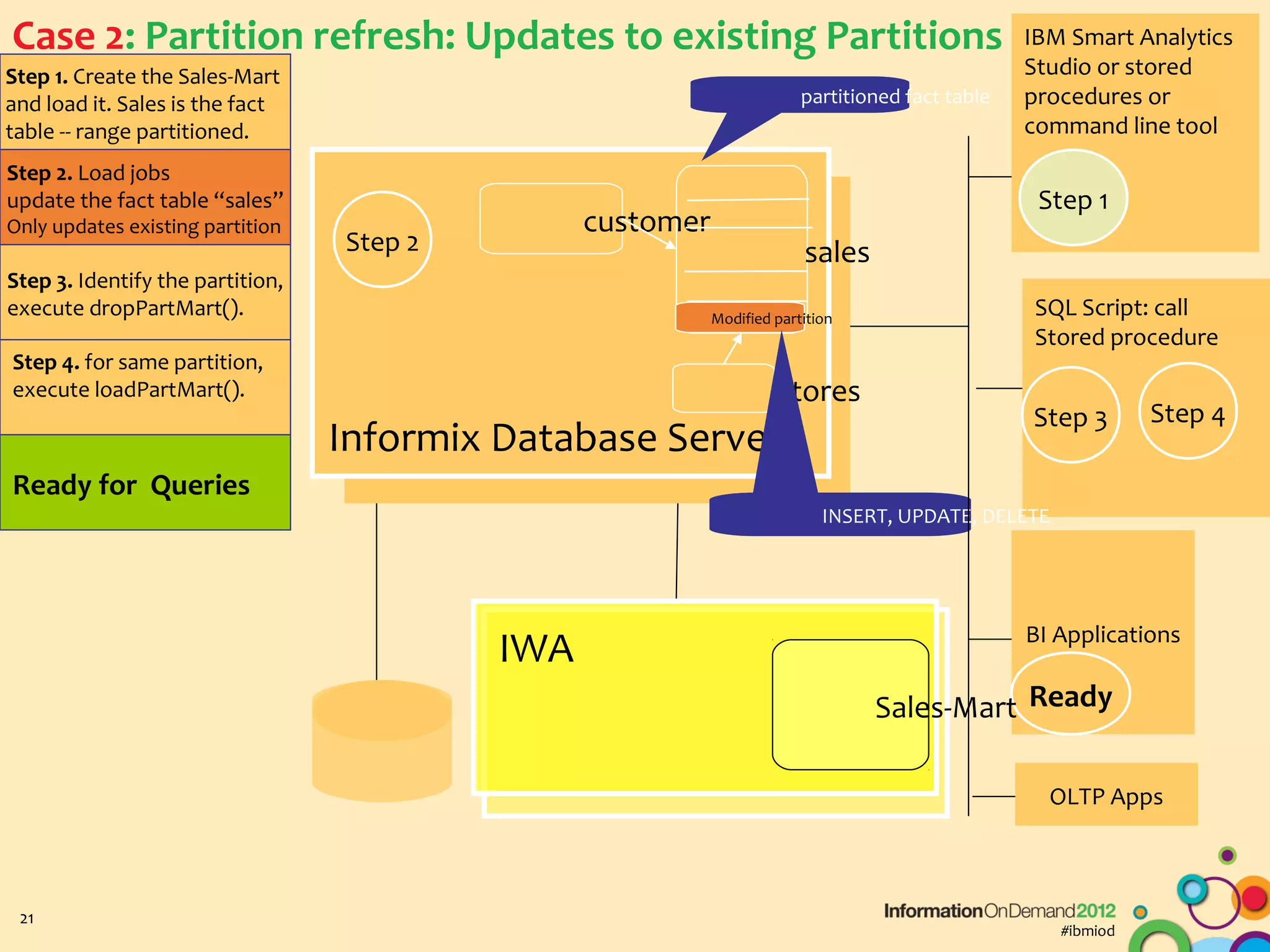
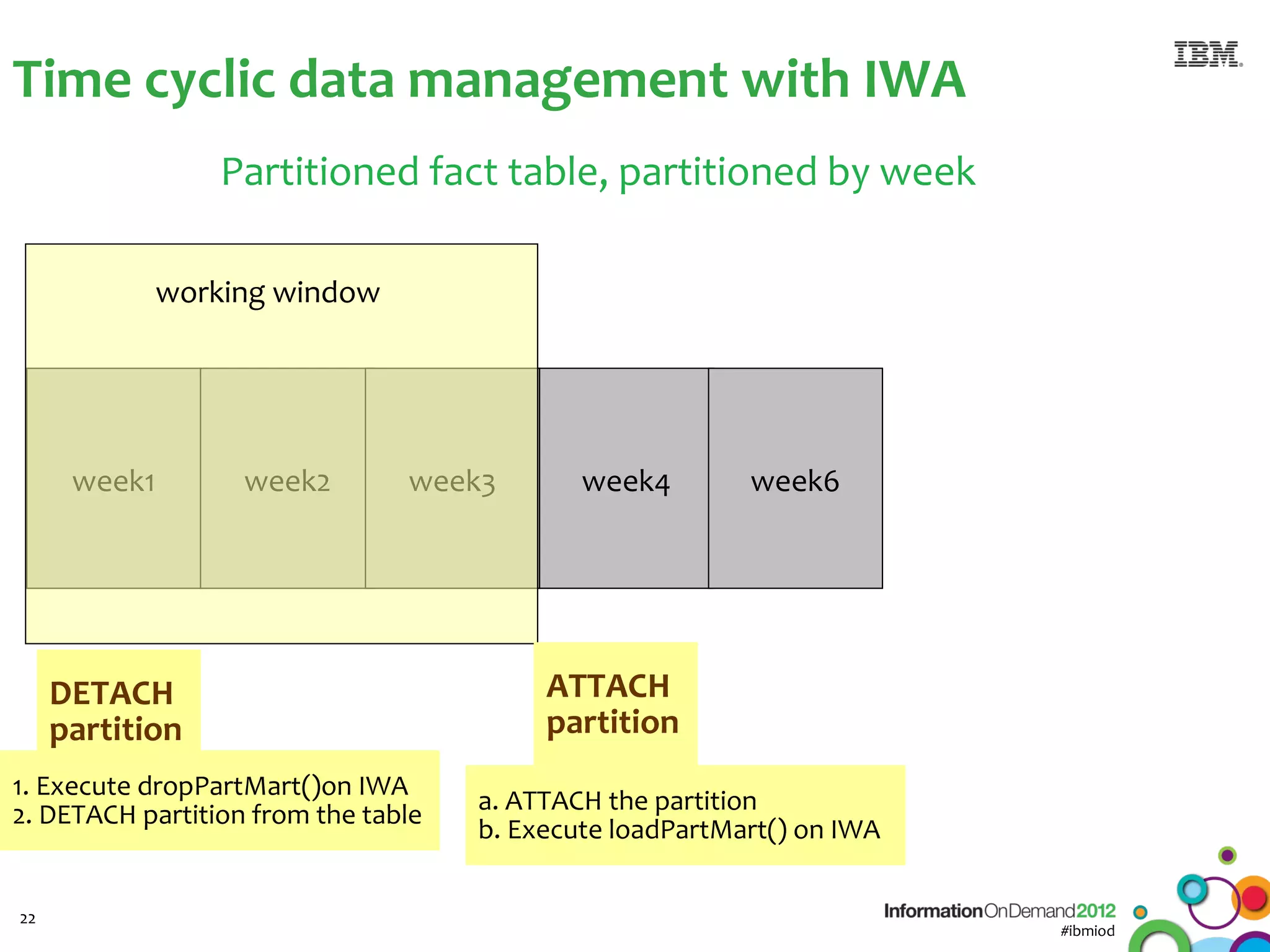
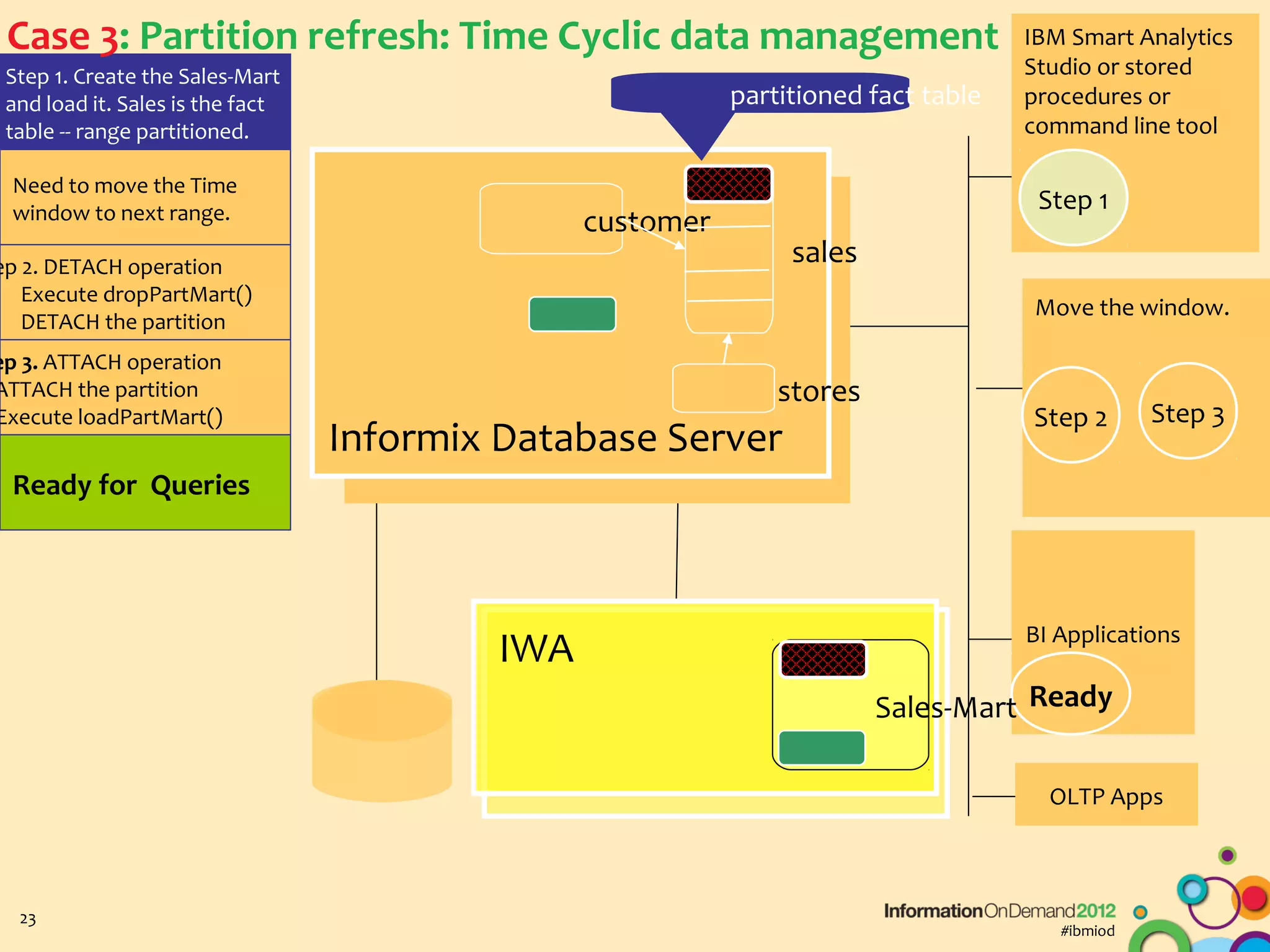




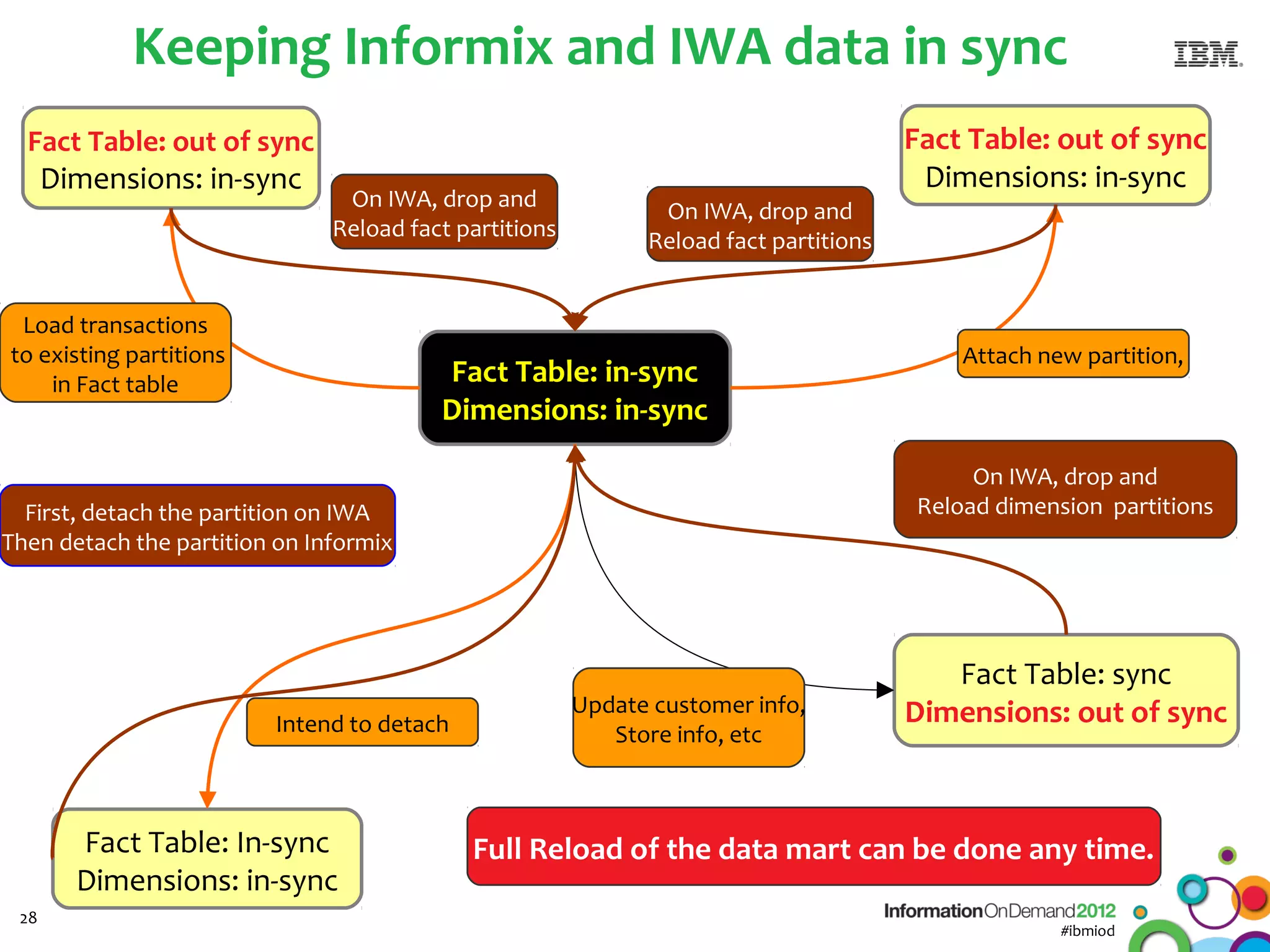

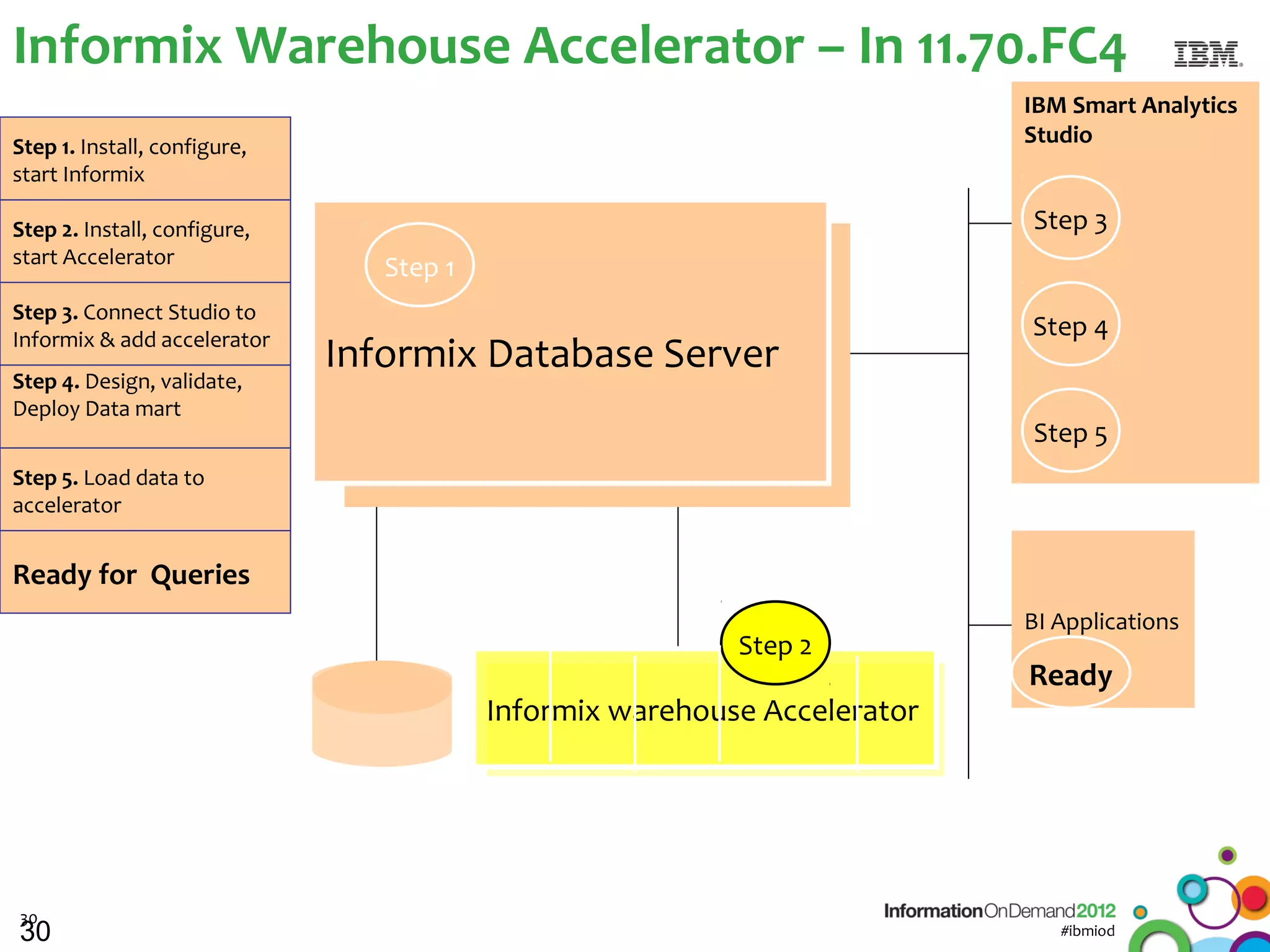

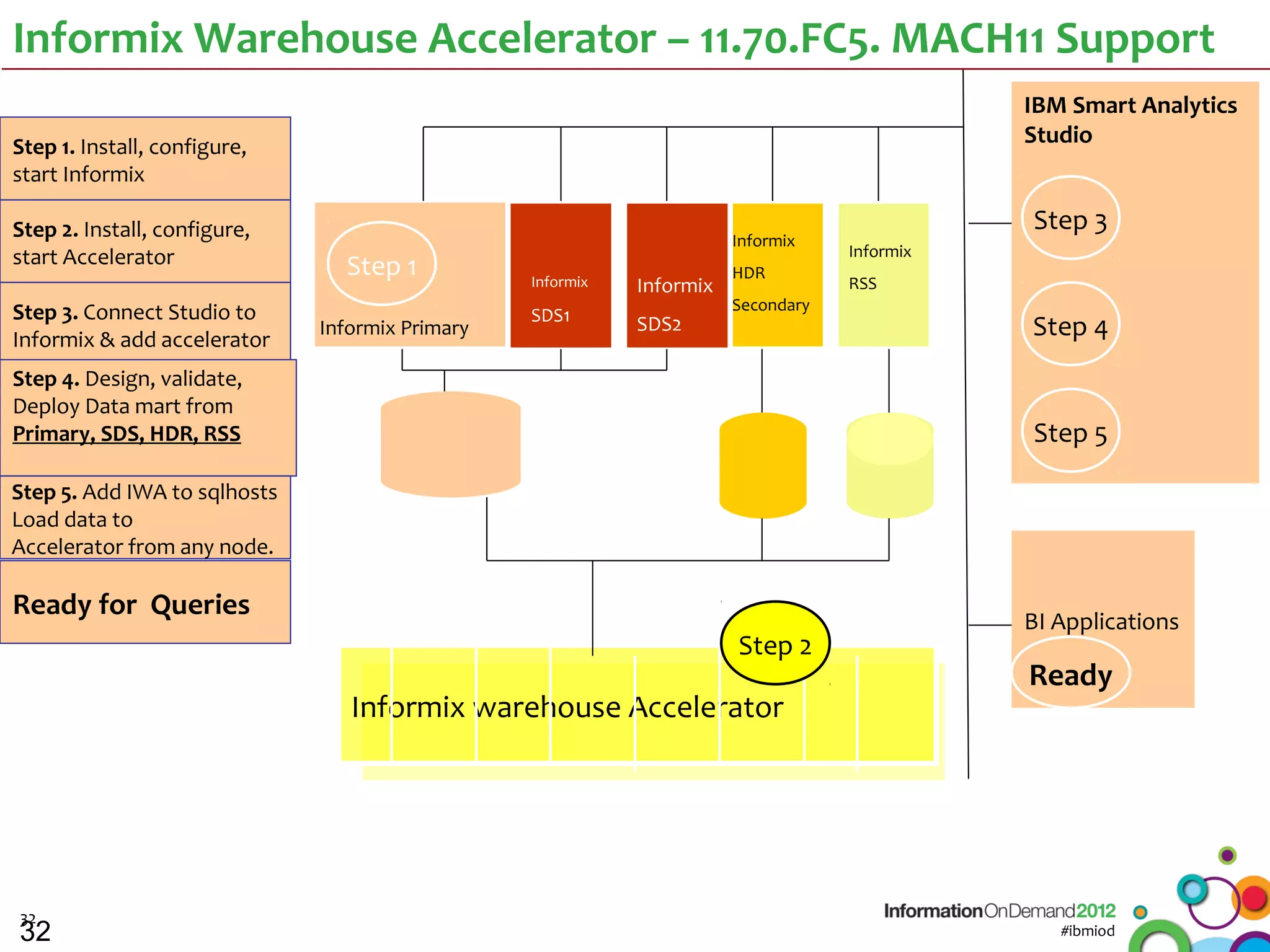






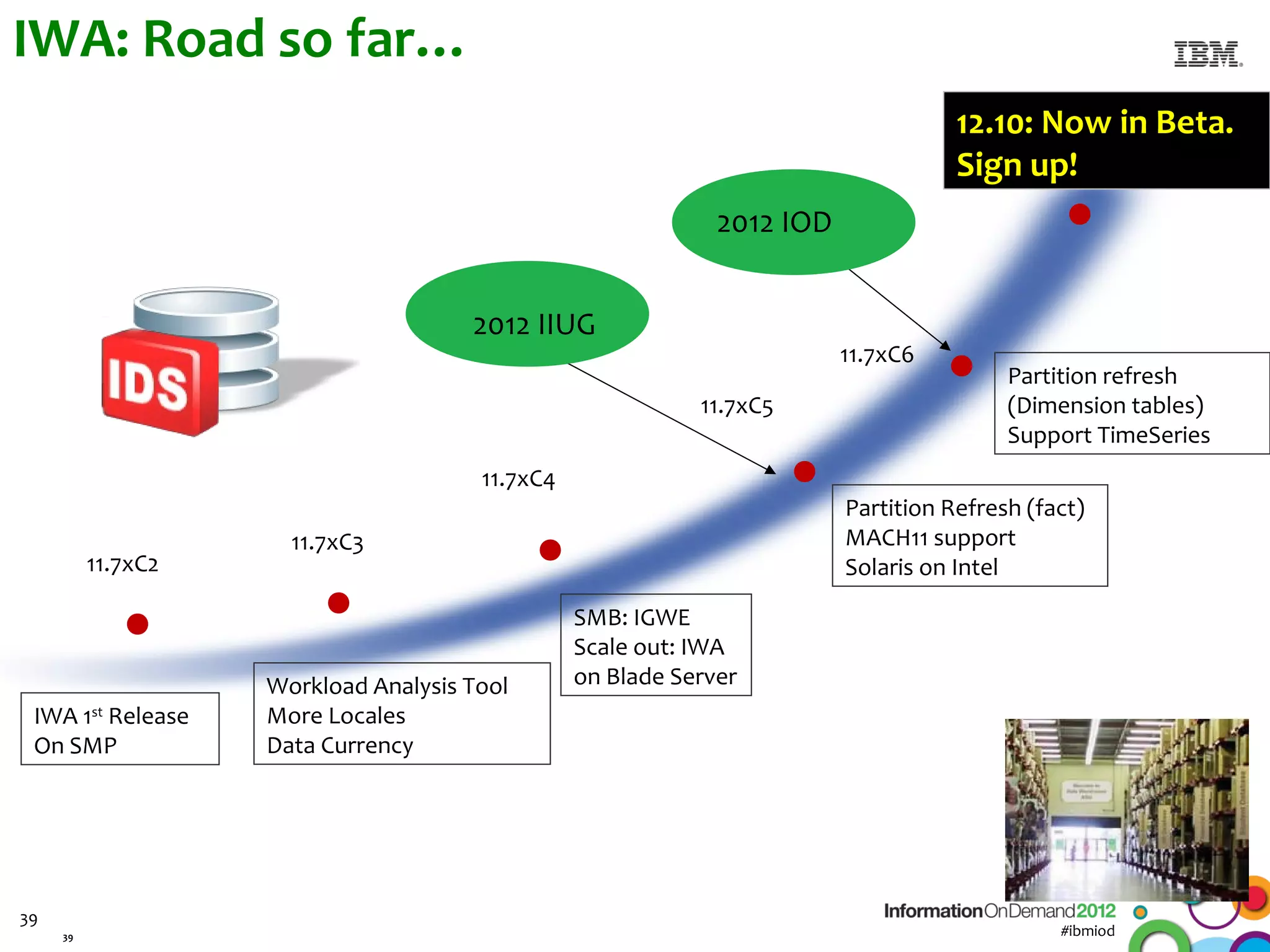



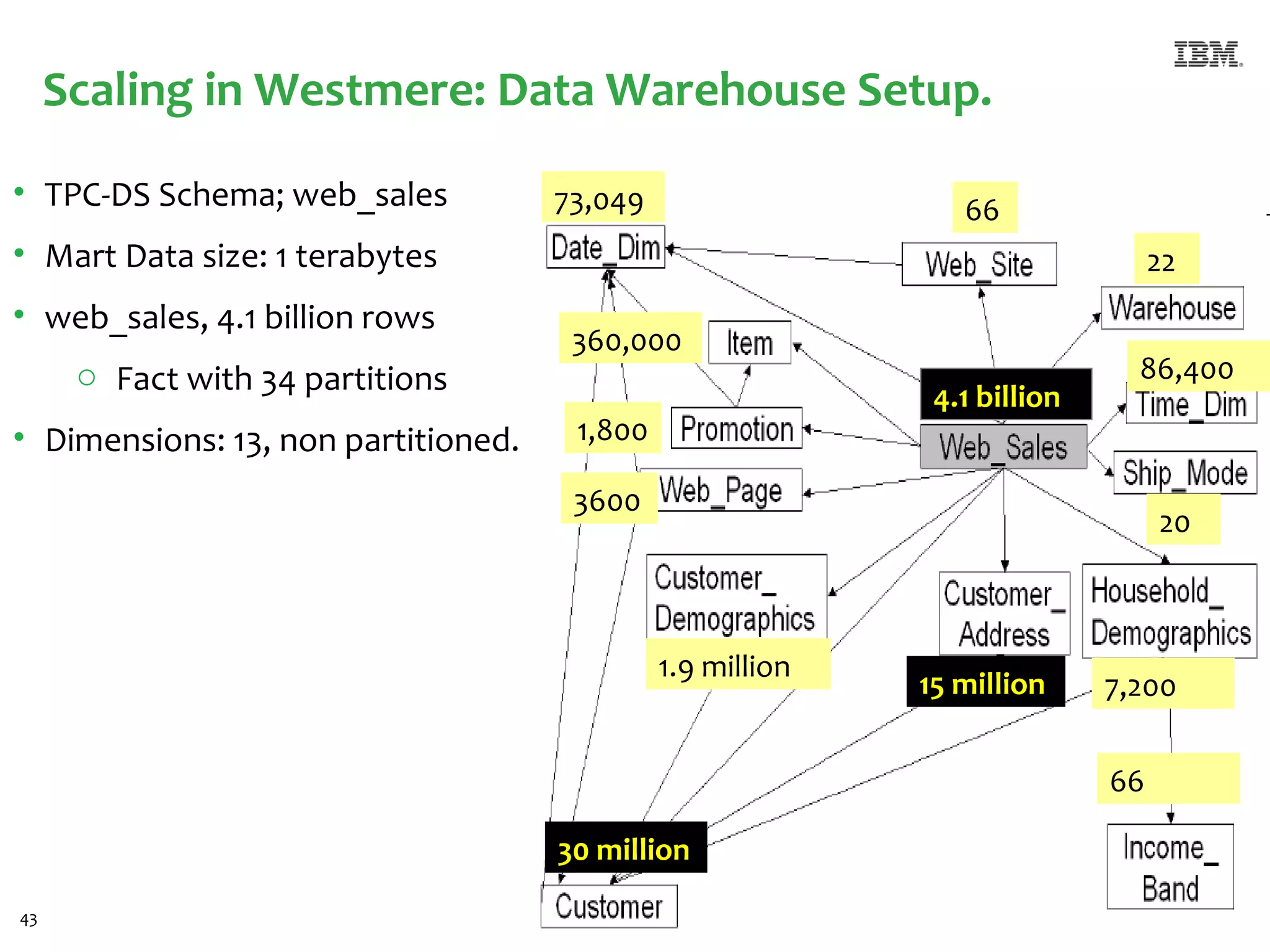
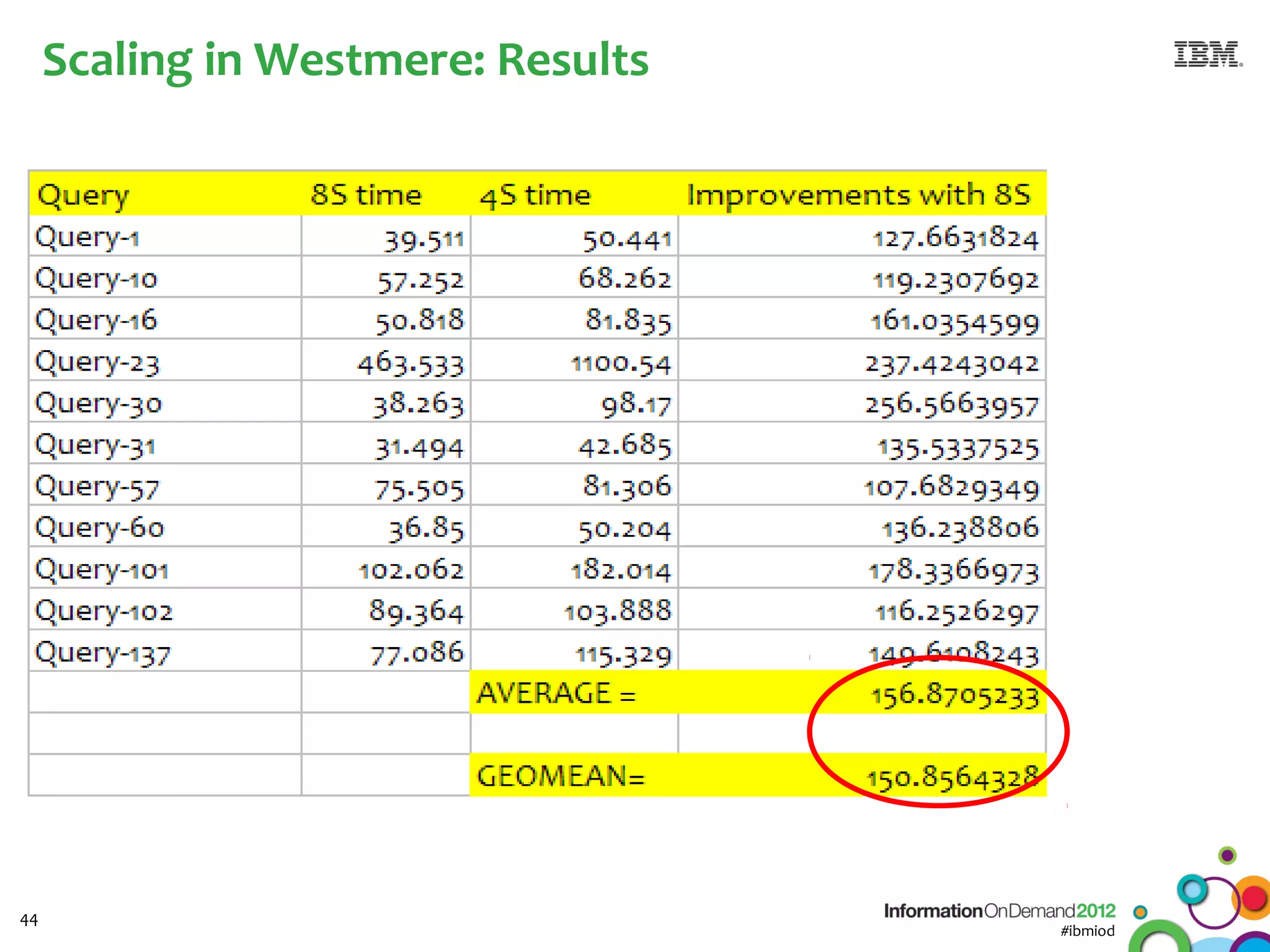

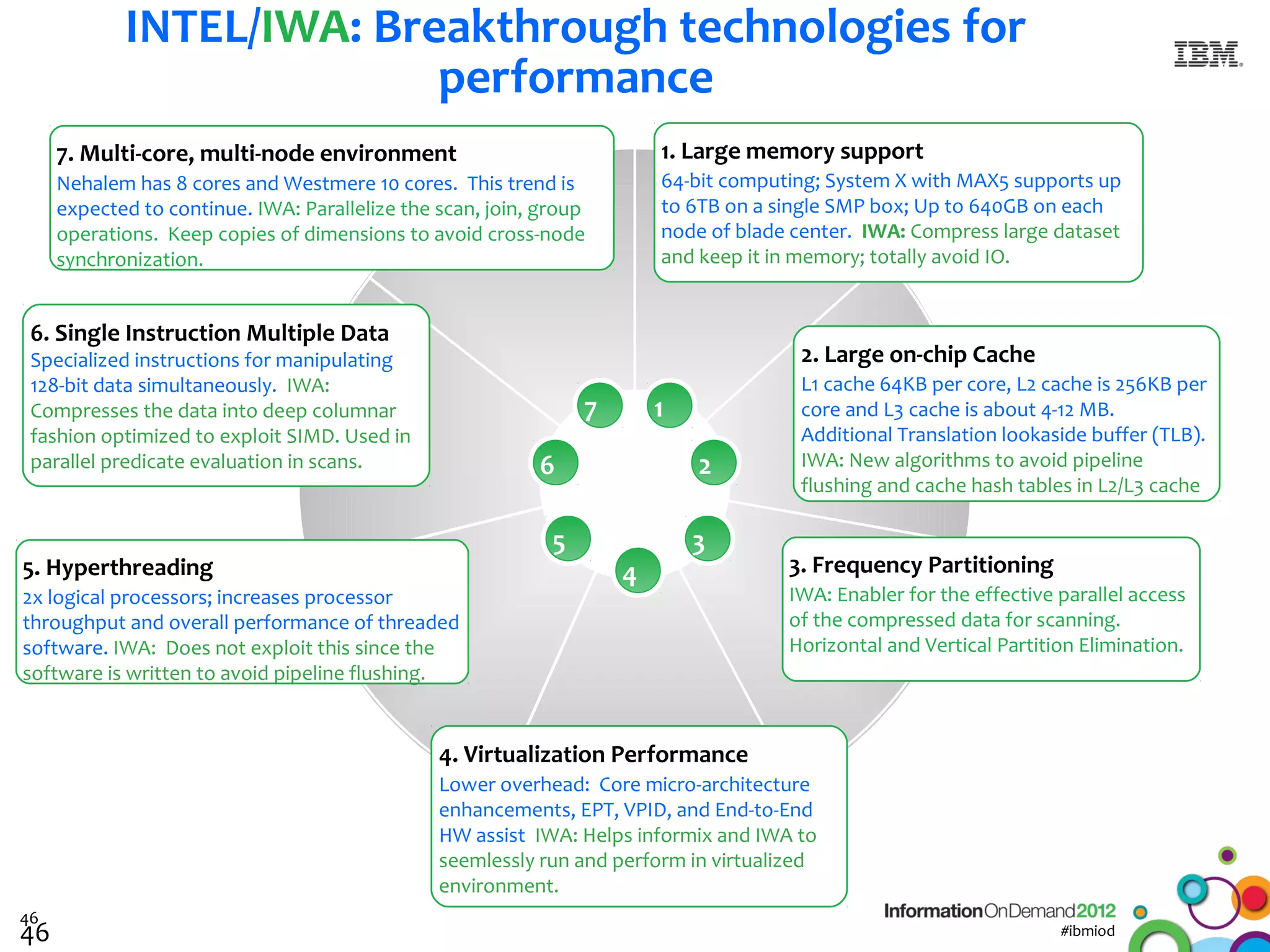
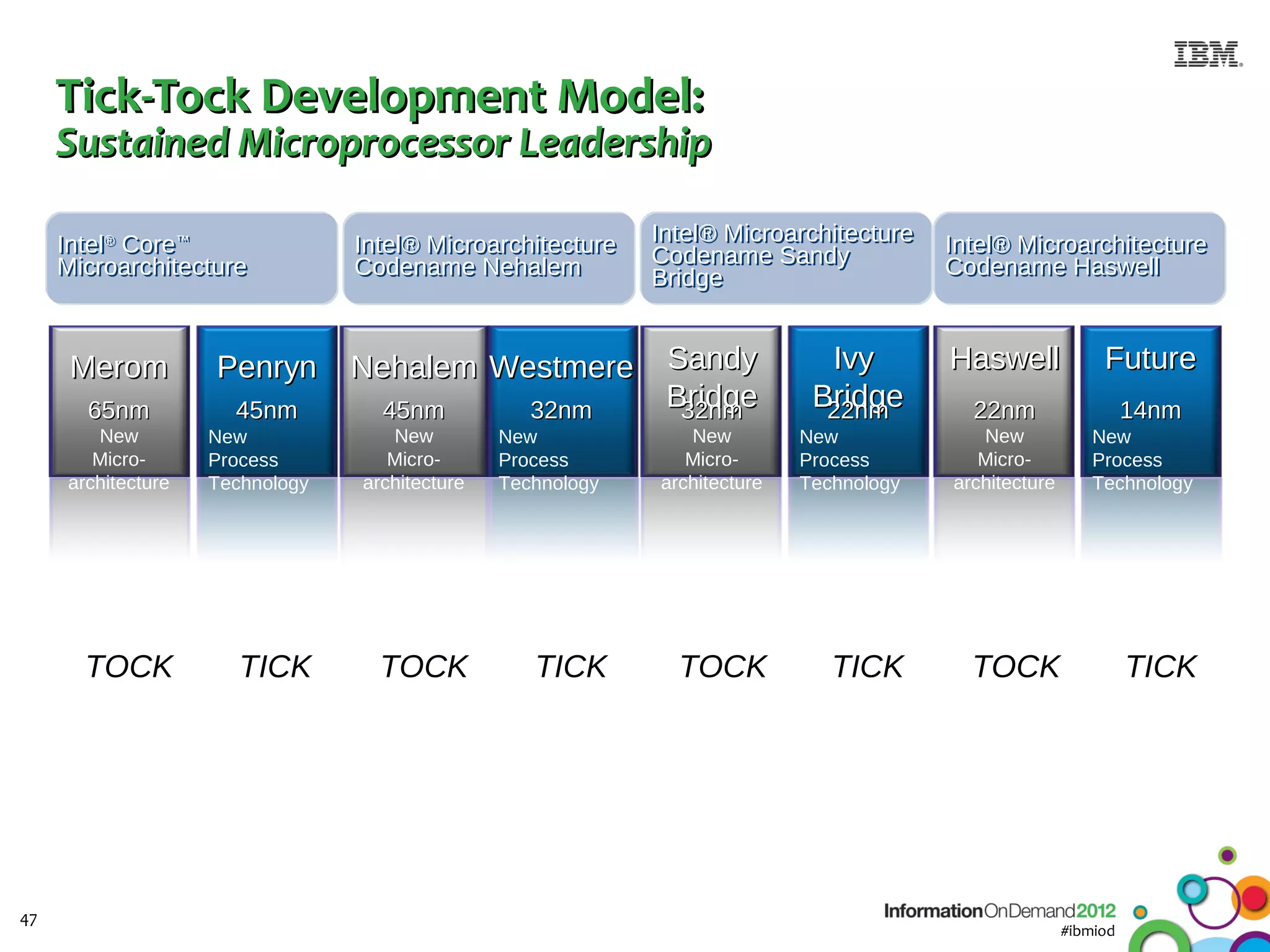
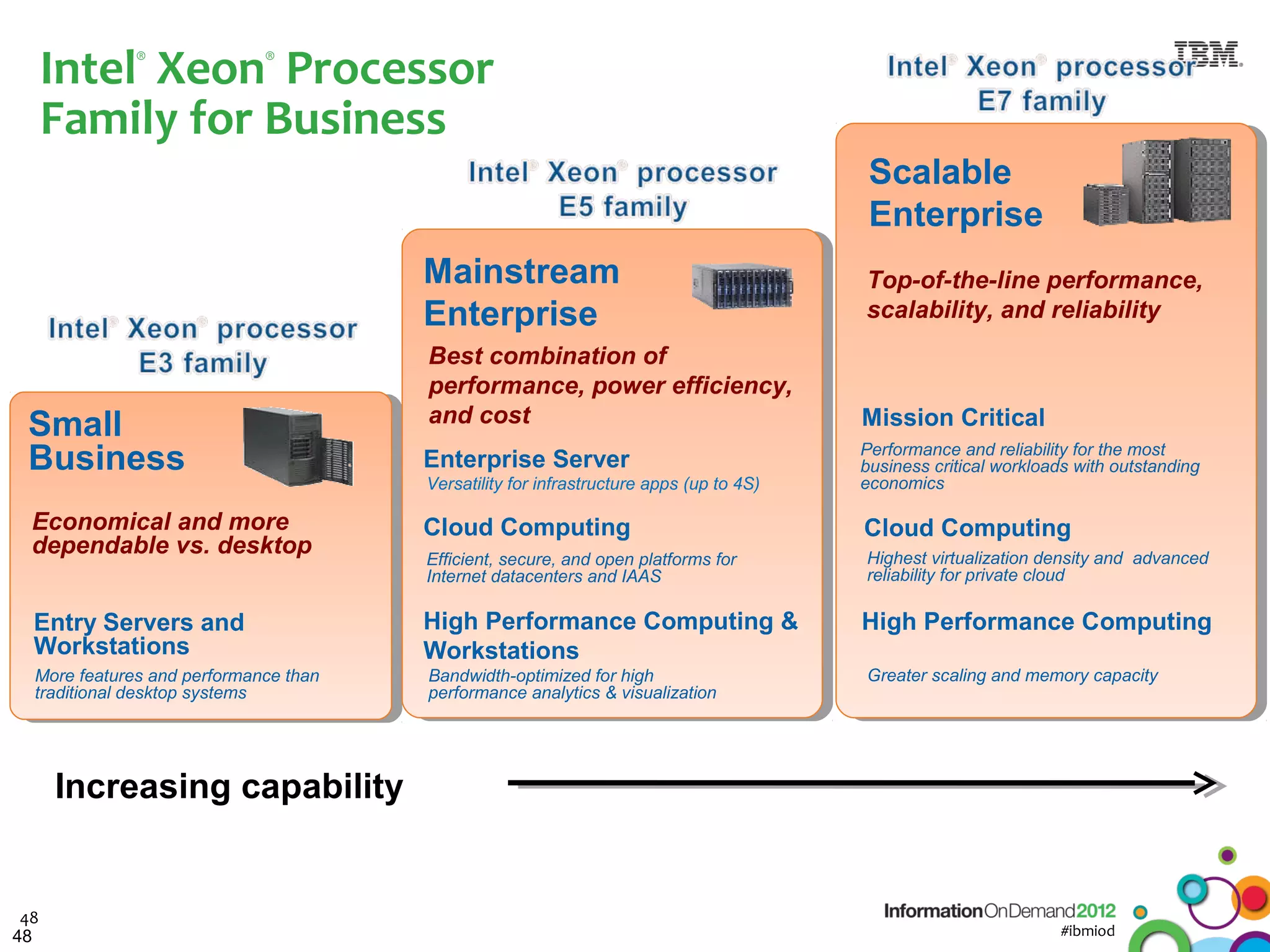
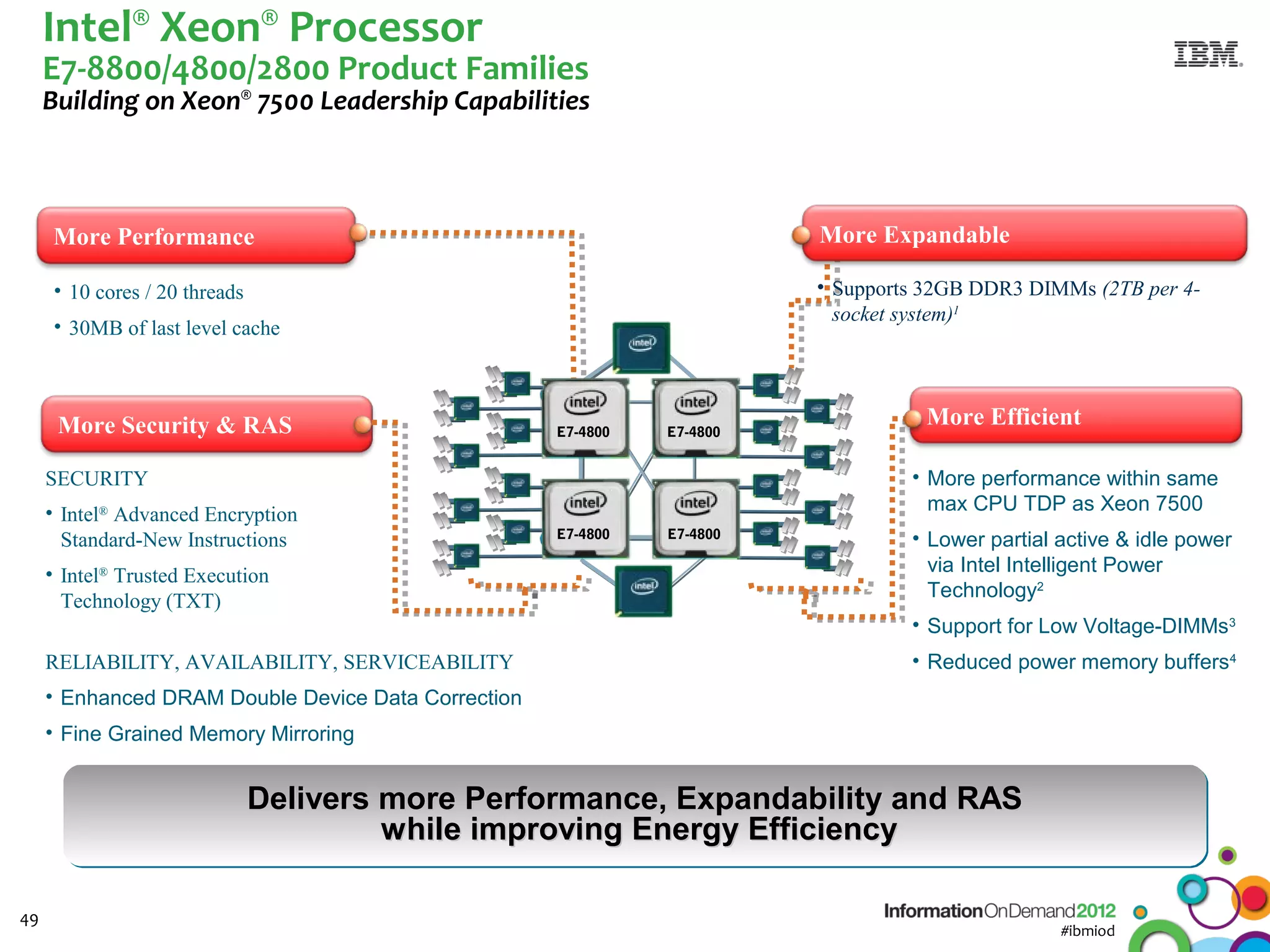


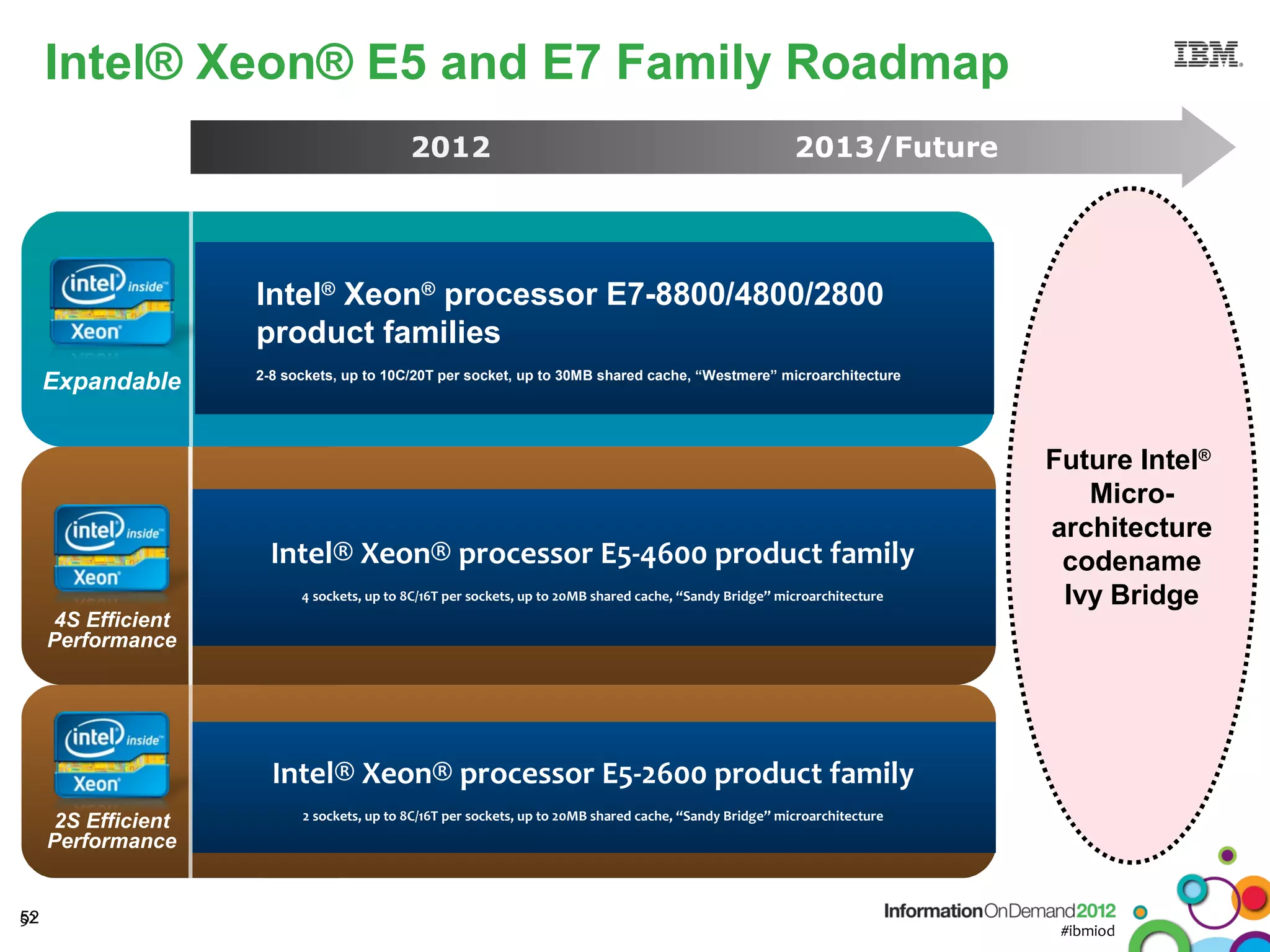
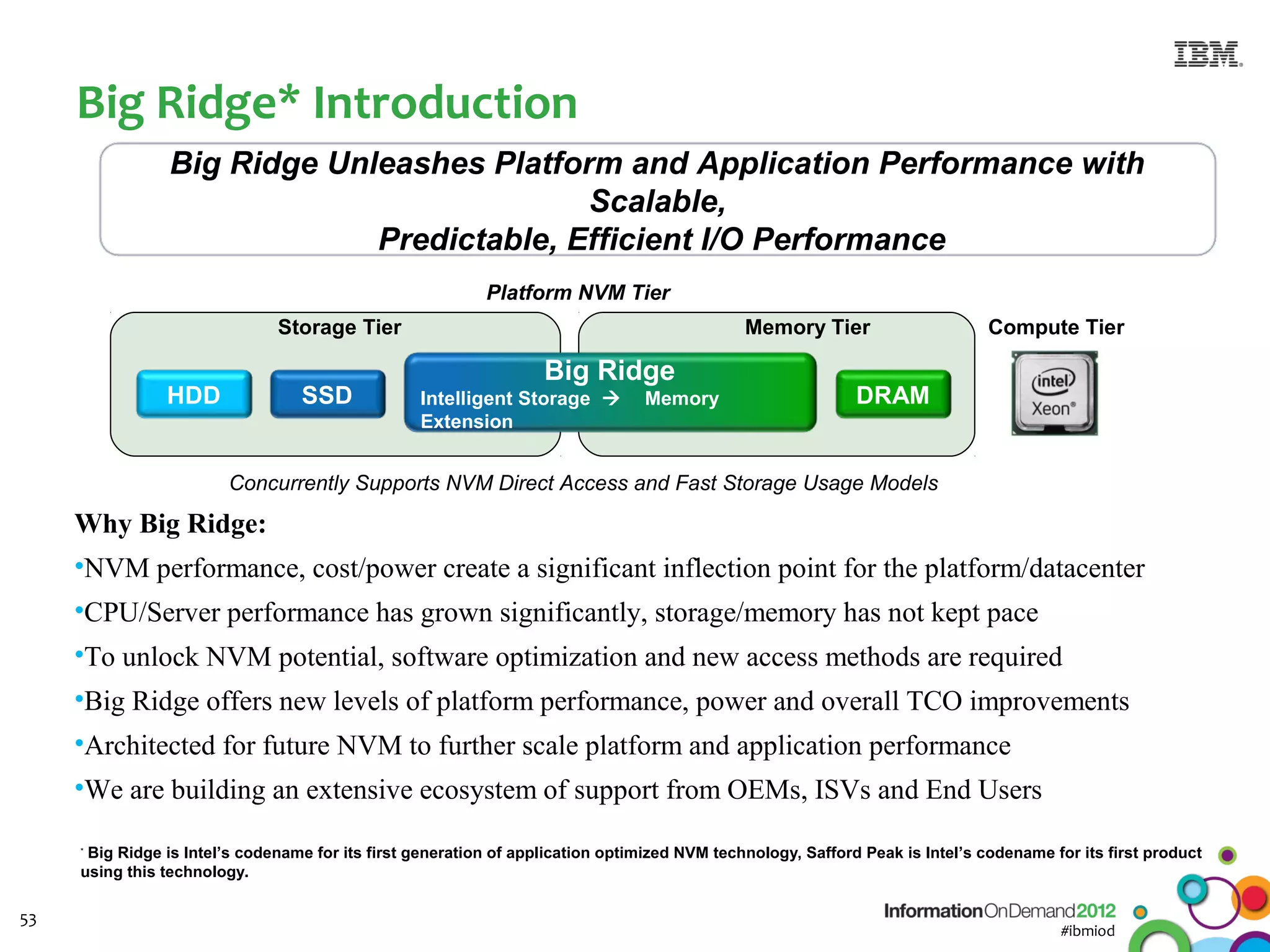


The document discusses the integration of Informix Warehouse Accelerator with Intel Xeon processors to enhance data life cycle management and improve data query performance. It highlights performance benchmarks, technical specifications, and the benefits of using Informix for business insights through accelerated query processing. Additionally, it outlines data management scenarios, configuration steps, and key features of the Informix Warehouse Accelerator.






















































































