Downloaded 29 times



















![Nervana Systems Proprietary
23
Reference
CER
(no LM)
WER
(no LM)
WER
(trigram LM)
WER
(trigram LM w/
enhancements)
Hannun, et al.
(2014)
10.7 35.8 14.1 N/A
Graves-Jaitly
(2014)
9.2 30.1 N/A 8.7
Hwang-Sung (2016) 10.6 38.4 8.88 8.1
Miao et al. (2015)
[Eesen]
N/A N/A 9.1 7.3
Bahdanau et al.
(2016)
6.4 18.6 10.8 9.3
Nervana-Speech 8.64 32.5 8.4 N/A
younited presidentiol is a lefe in surance
company
united presidential is a life insurance
company
that was sertainly true last week
that was certainly true last week
we're now ready to say we're intechnical
default a spokesman said
we're not ready to say we're in technical
default a spokesman said](https://image.slidesharecdn.com/meetup11301-161207190211/75/Intel-Nervana-Artificial-Intelligence-Meetup-11-30-16-23-2048.jpg)







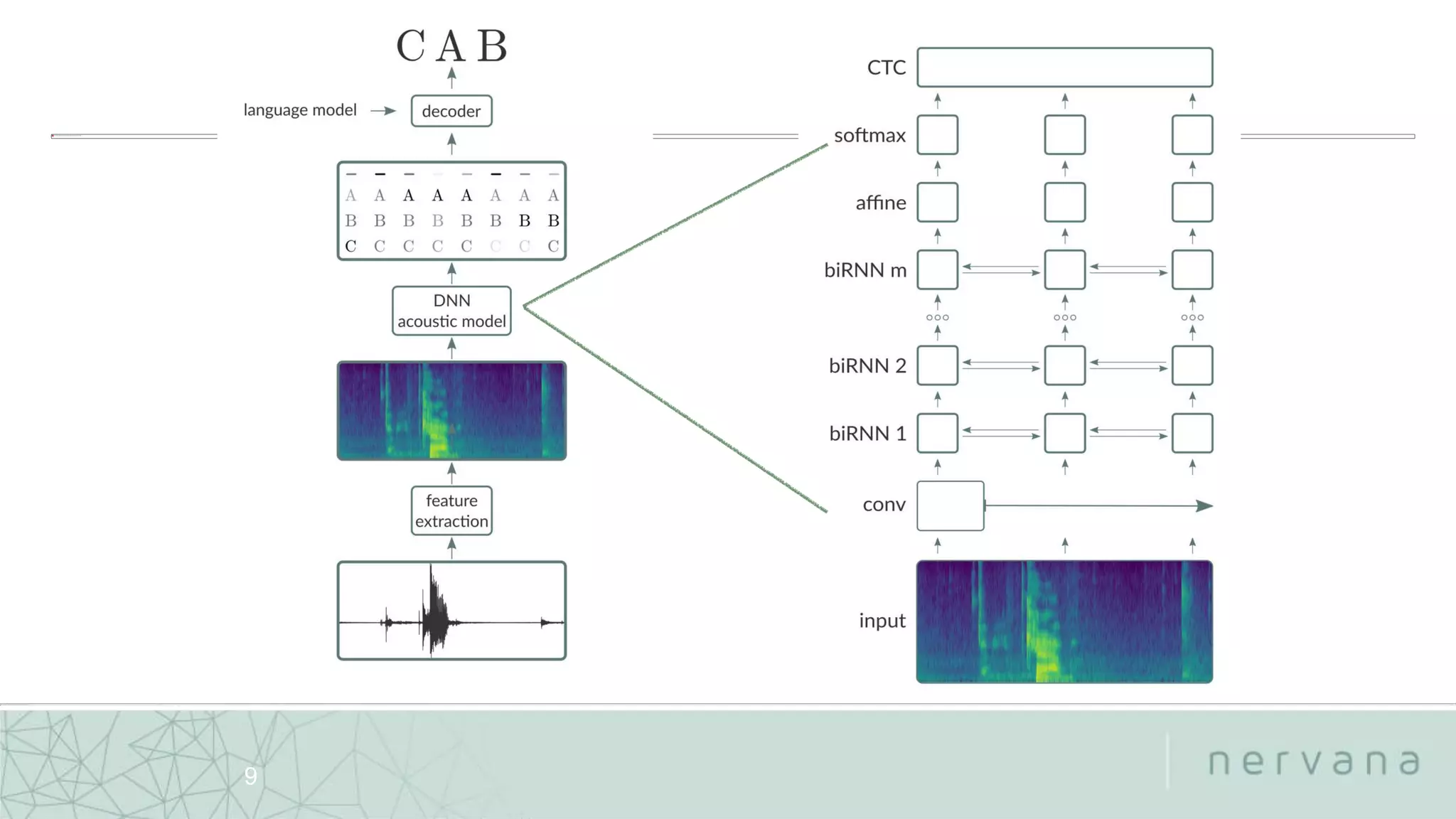
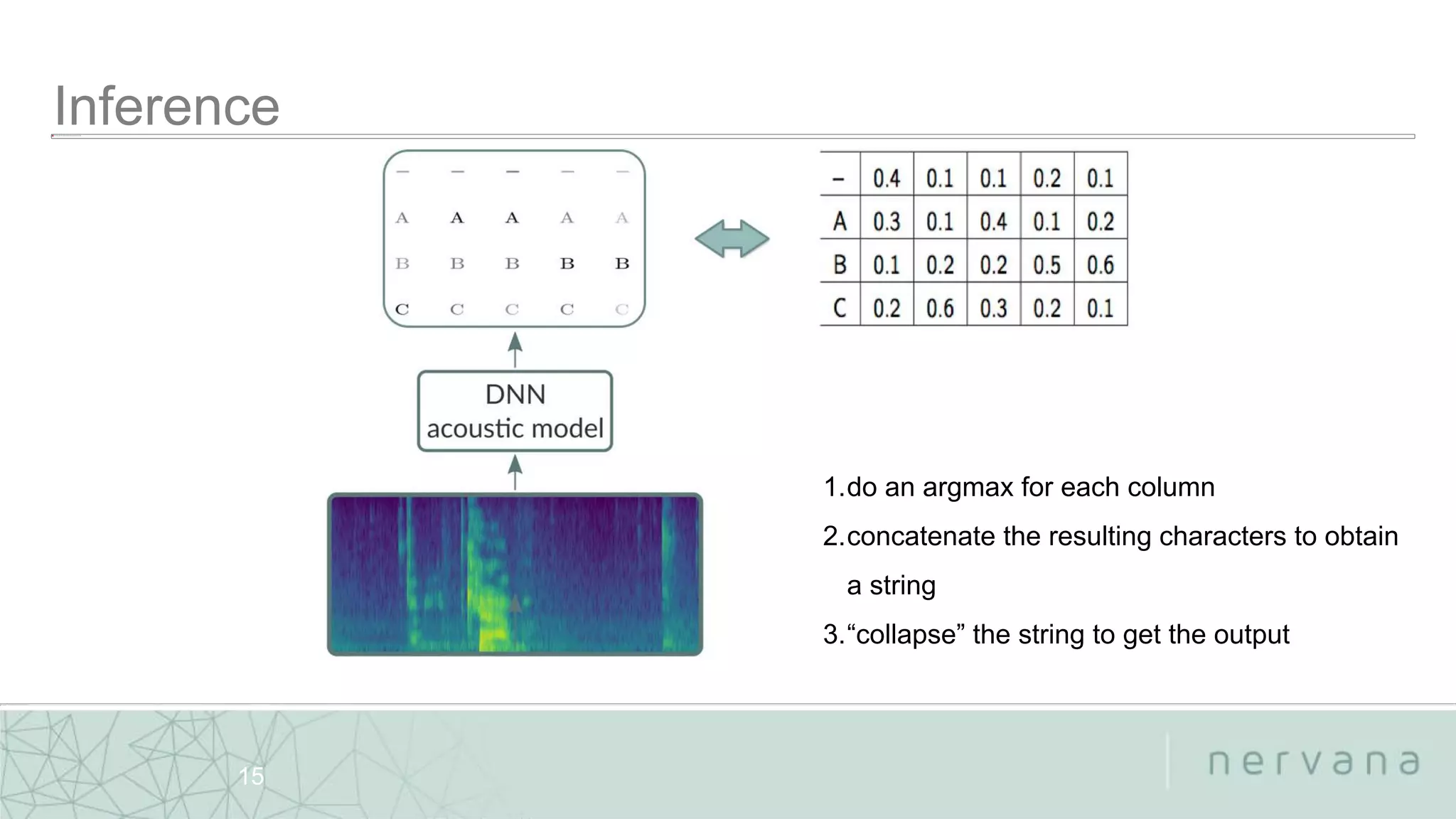
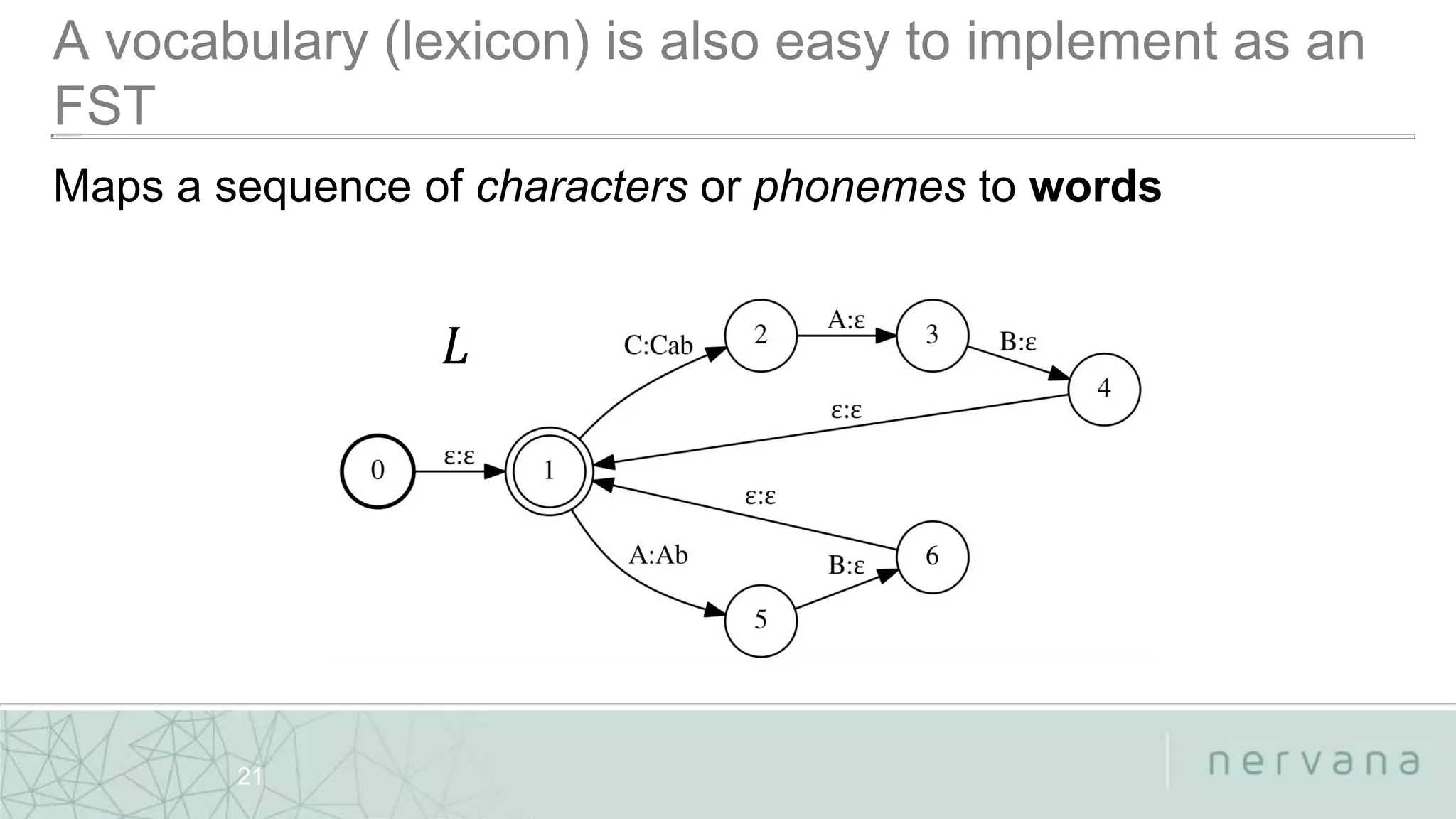
The document discusses end-to-end speech recognition technologies developed by Nervana Systems, emphasizing features like large vocabulary continuous speech recognition and the integration of weighted finite-state transducers for decoding. It also provides links to relevant GitHub repositories for further exploration of their deep learning tools and acoustic models. Various applications in healthcare, automotive, and finance sectors are highlighted, demonstrating the adaptability and performance of their systems.























































![[DSC Europe 23] Paweł Ekk-Cierniakowski - Video transcription with deep learn...](https://cdn.slidesharecdn.com/ss_thumbnails/paweekk-cierniakowski-videotranscriptionwithdeeplearningmoduleforrecognizingsounds-231129095108-362f9635-thumbnail.jpg?width=640&height=640&fit=bounds)


























