Downloaded 132 times








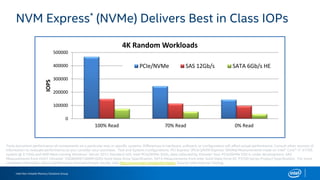
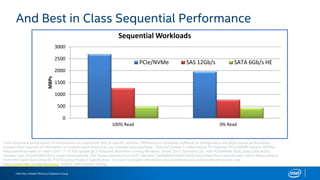
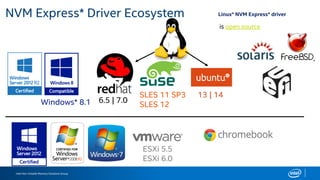
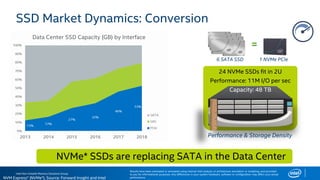
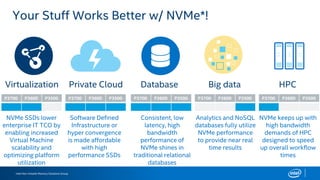



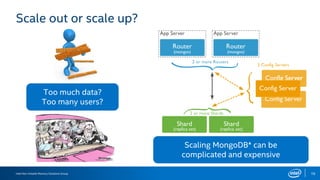
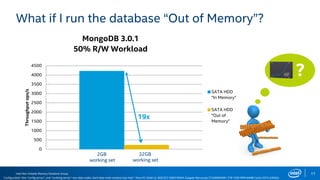



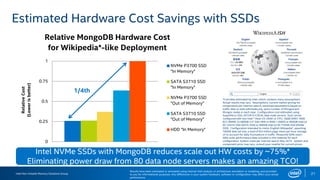


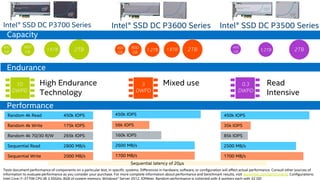
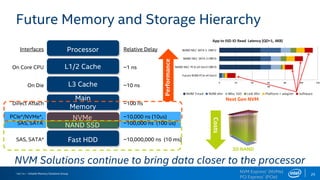



The document discusses the benefits of using NVMe SSDs to scale MongoDB applications, emphasizing improvements in performance, efficiency, and cost-effectiveness compared to traditional SSDs and HDDs. It highlights that NVMe technology can significantly enhance database throughput and reduce hardware costs for enterprises by improving scalability and optimizing resource utilization. Additionally, it provides insights into market trends and expected future developments in storage solutions.





















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)