Download to read offline





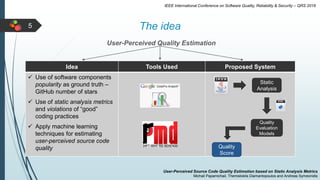

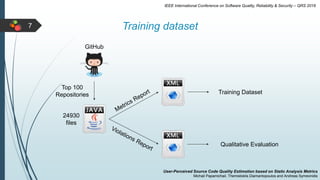


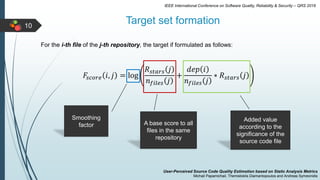





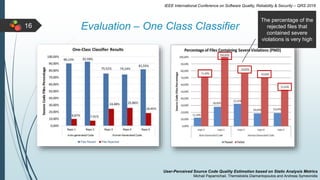
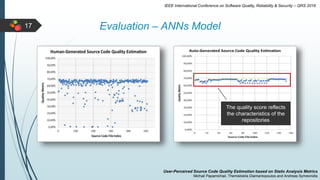
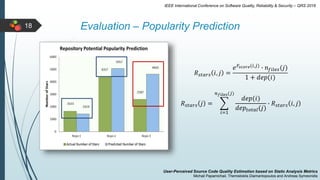



This document describes a system for estimating user-perceived source code quality based on static analysis metrics. It uses machine learning techniques to predict quality scores based on code popularity metrics and violations of coding practices. The system was evaluated on Java repositories from GitHub and shown to reliably distinguish high-quality code and estimate quality scores that reflect the characteristics of different repositories. It was also able to accurately predict the popularity of repositories based on the estimated quality of their source code files.















































![Treating Code Quality as a First Class Entity (icsme15) [doc. symposium]](https://cdn.slidesharecdn.com/ss_thumbnails/doctoralsymposium-150929075536-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
















































