Downloaded 92 times










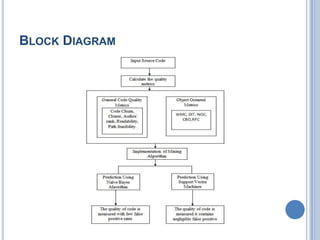






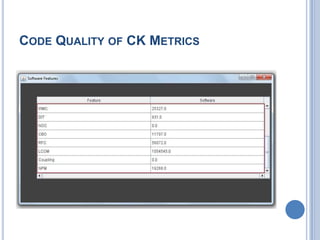
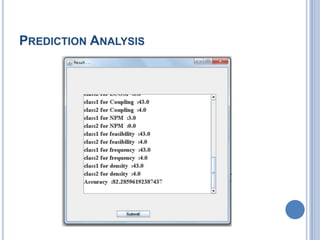


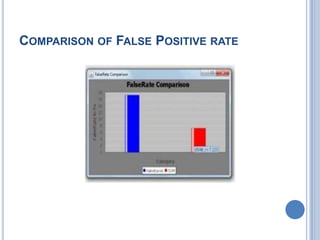




The document discusses the importance of measuring code quality using software metrics to enhance specification mining, highlighting that poor software quality costs the U.S. billions annually. It proposes a system utilizing support vector machine algorithms to predict software quality and significantly reduce false positive rates from 90% to 5%, while improving accuracy to 95%. The analysis indicates that advancements in automatic specification mining can lower maintenance costs and improve software reliability before deployment.























































































