Downloaded 12 times







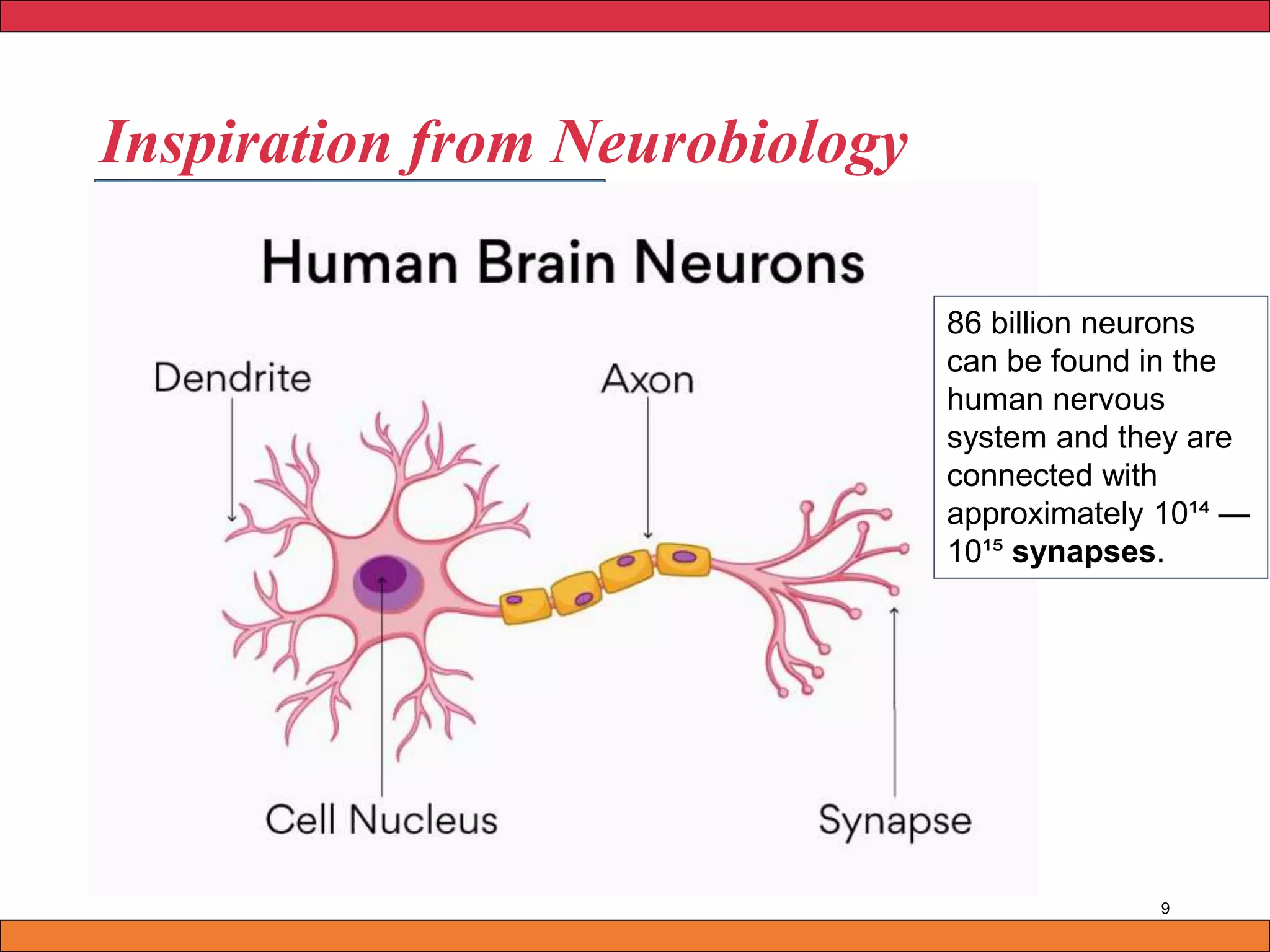
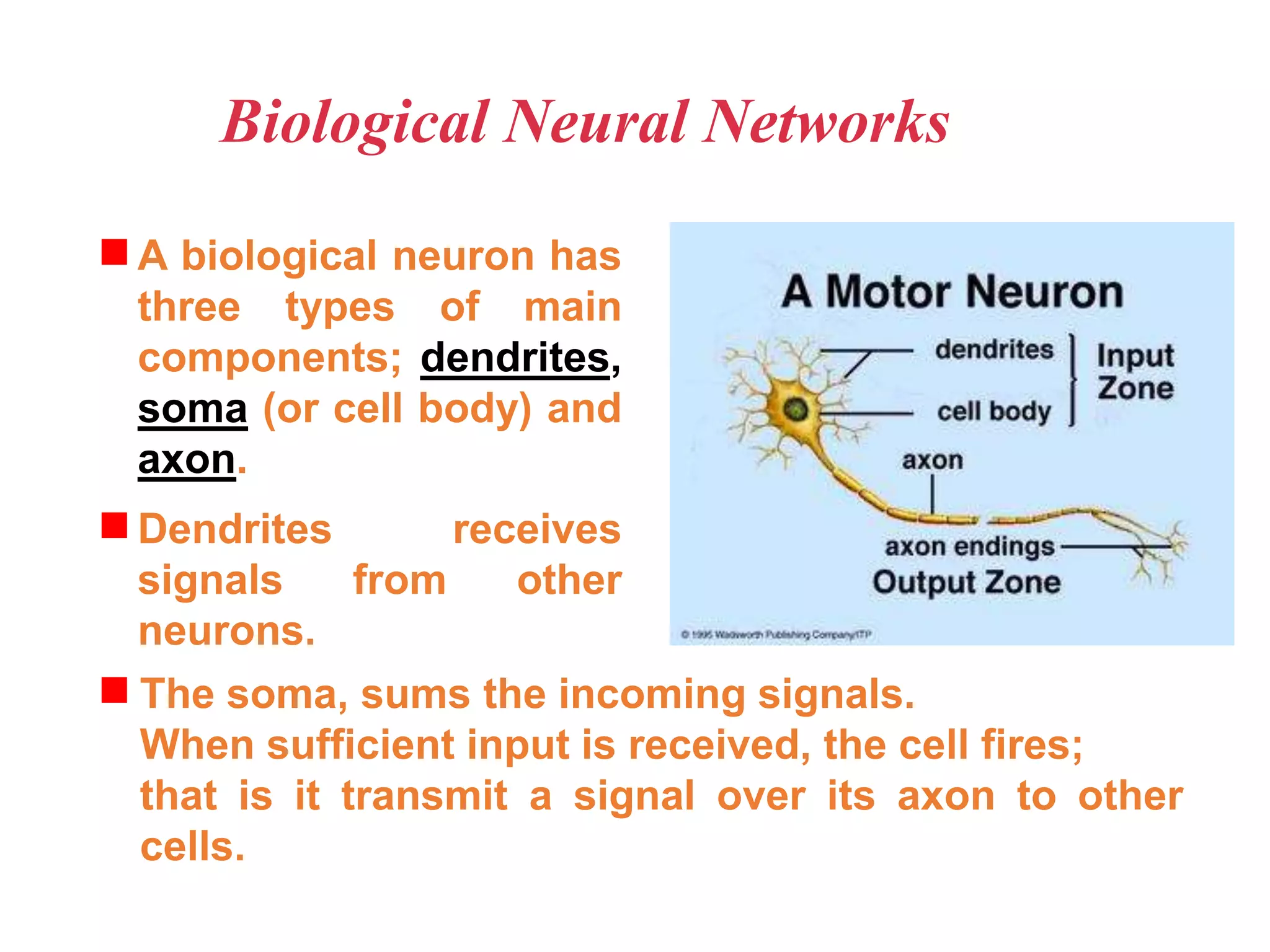

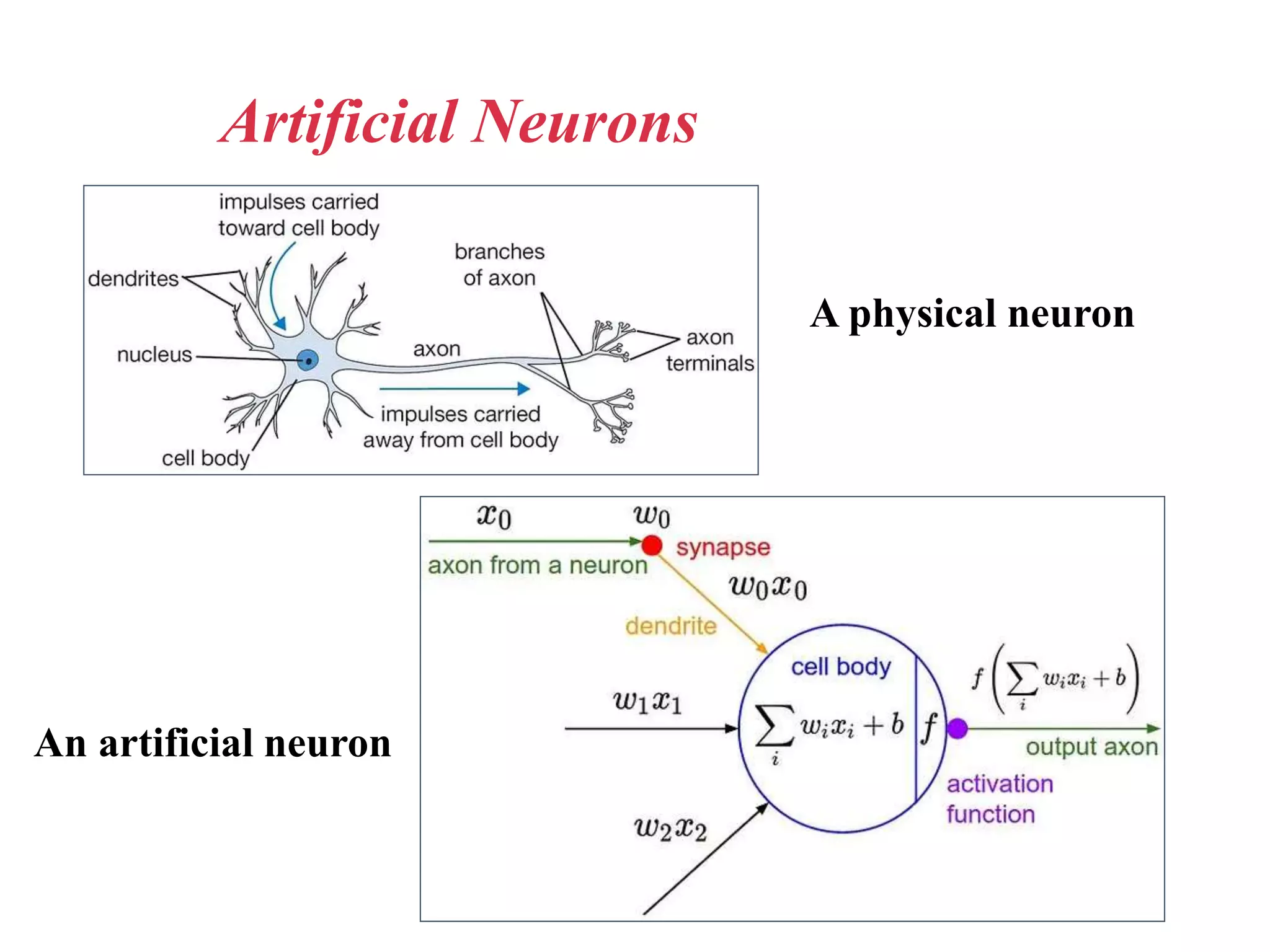
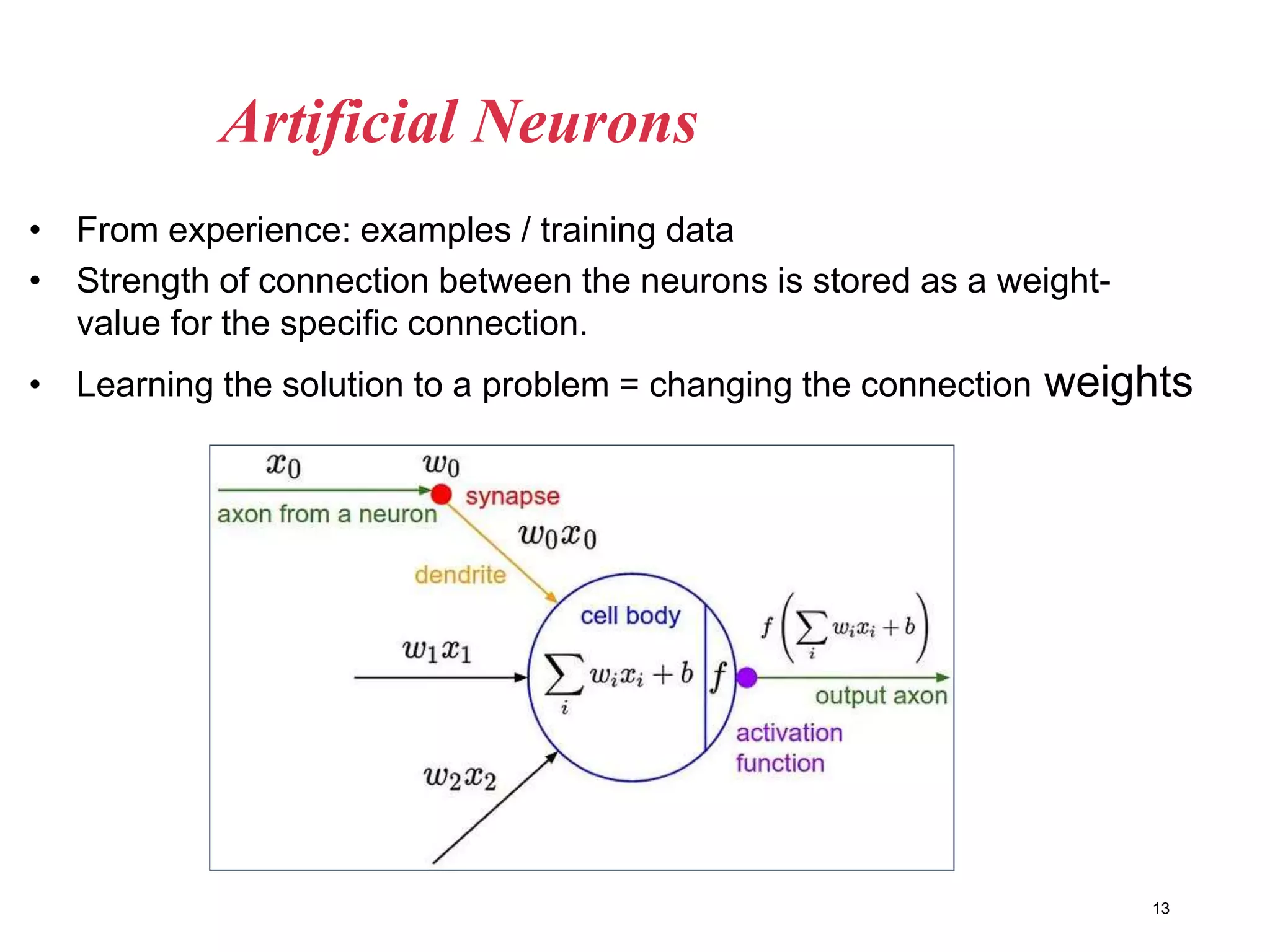
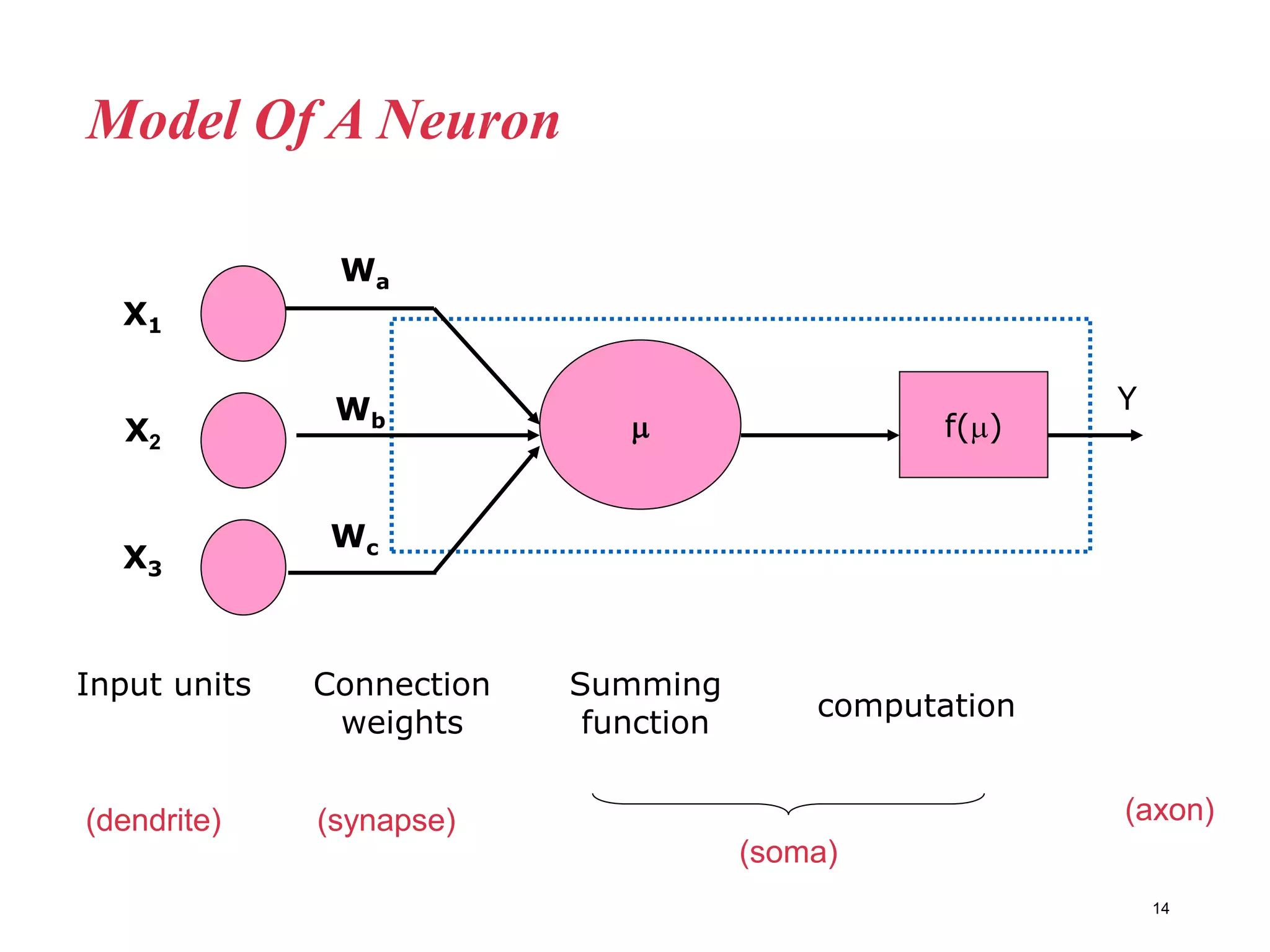


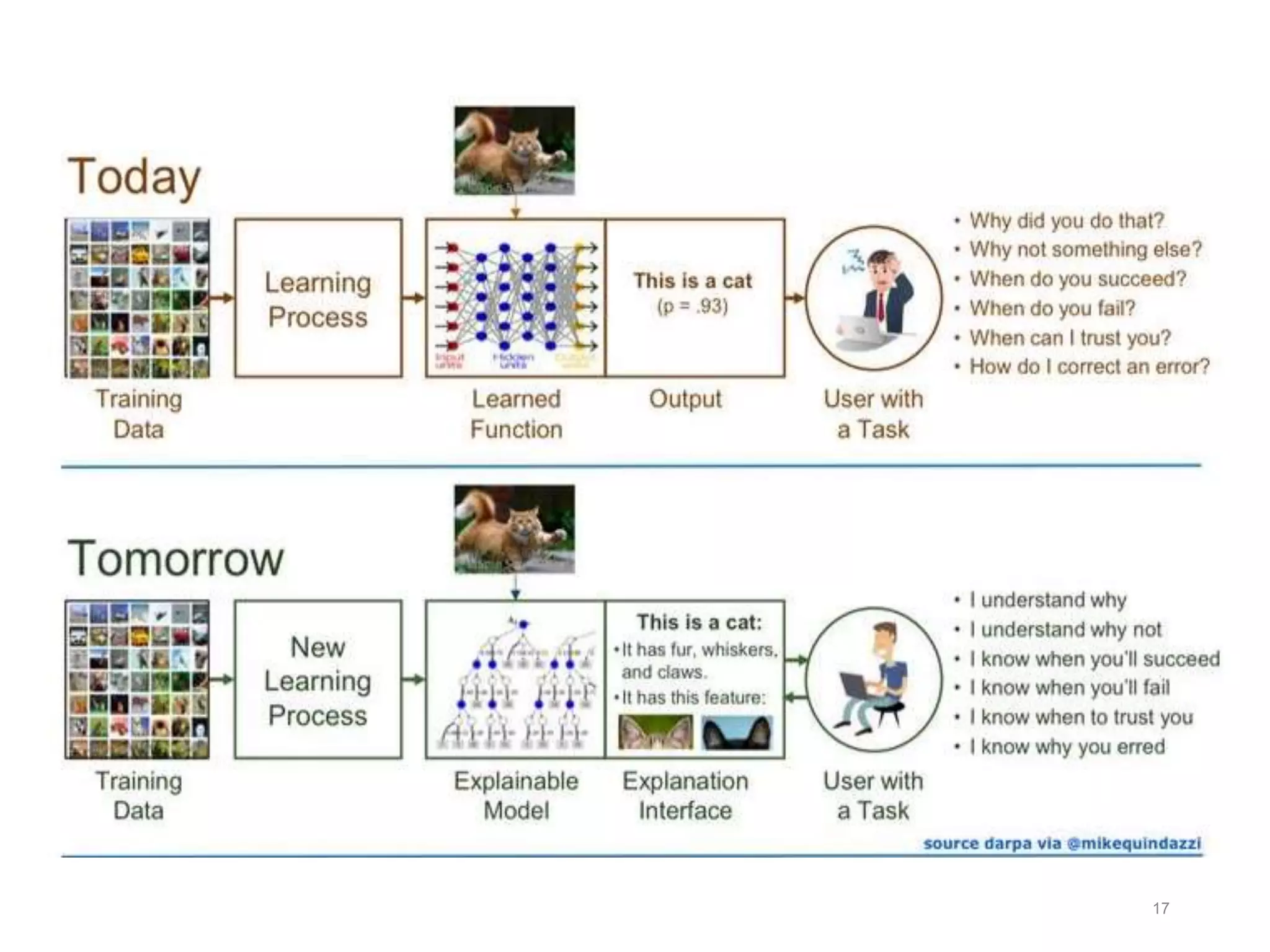

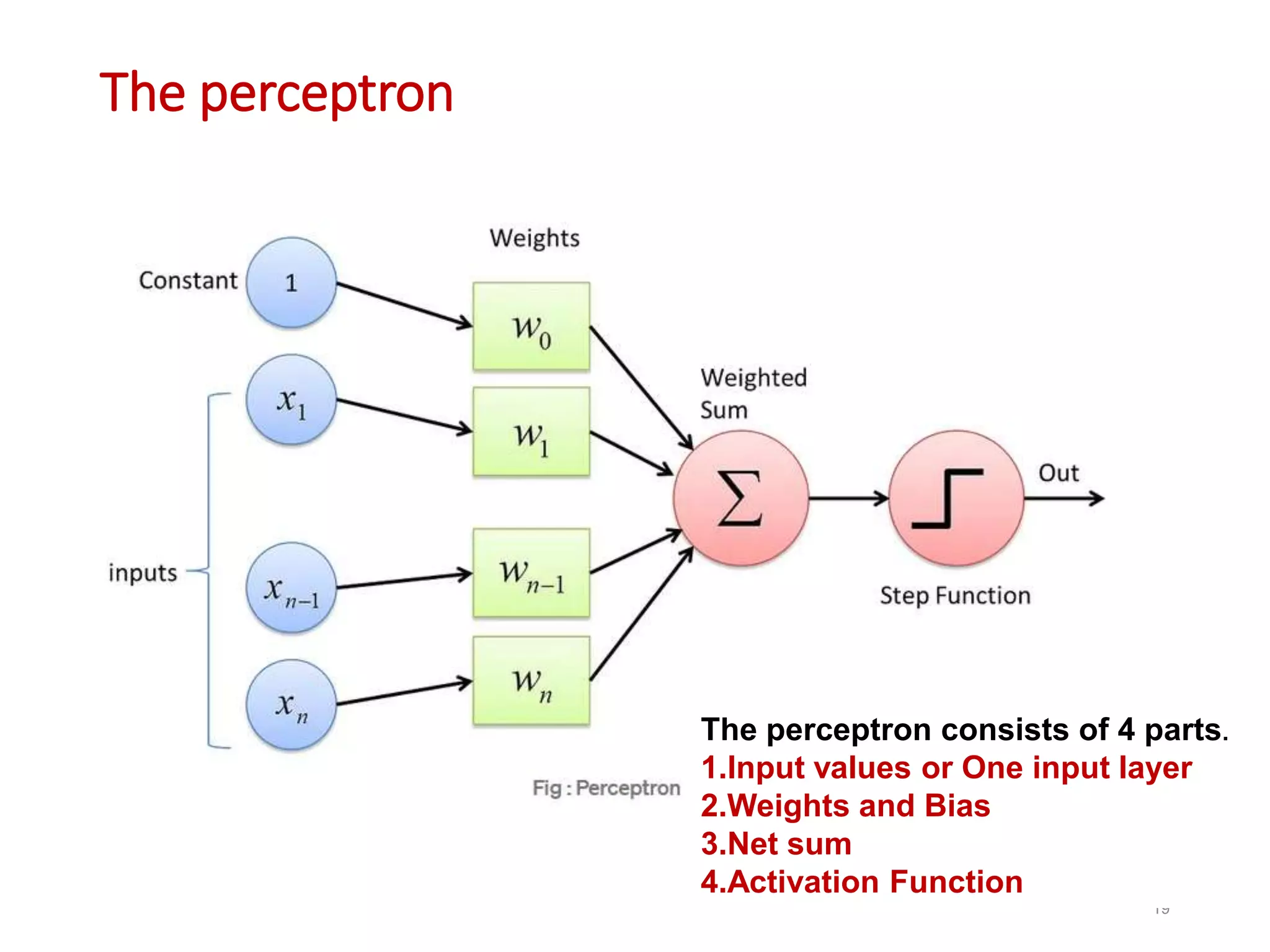


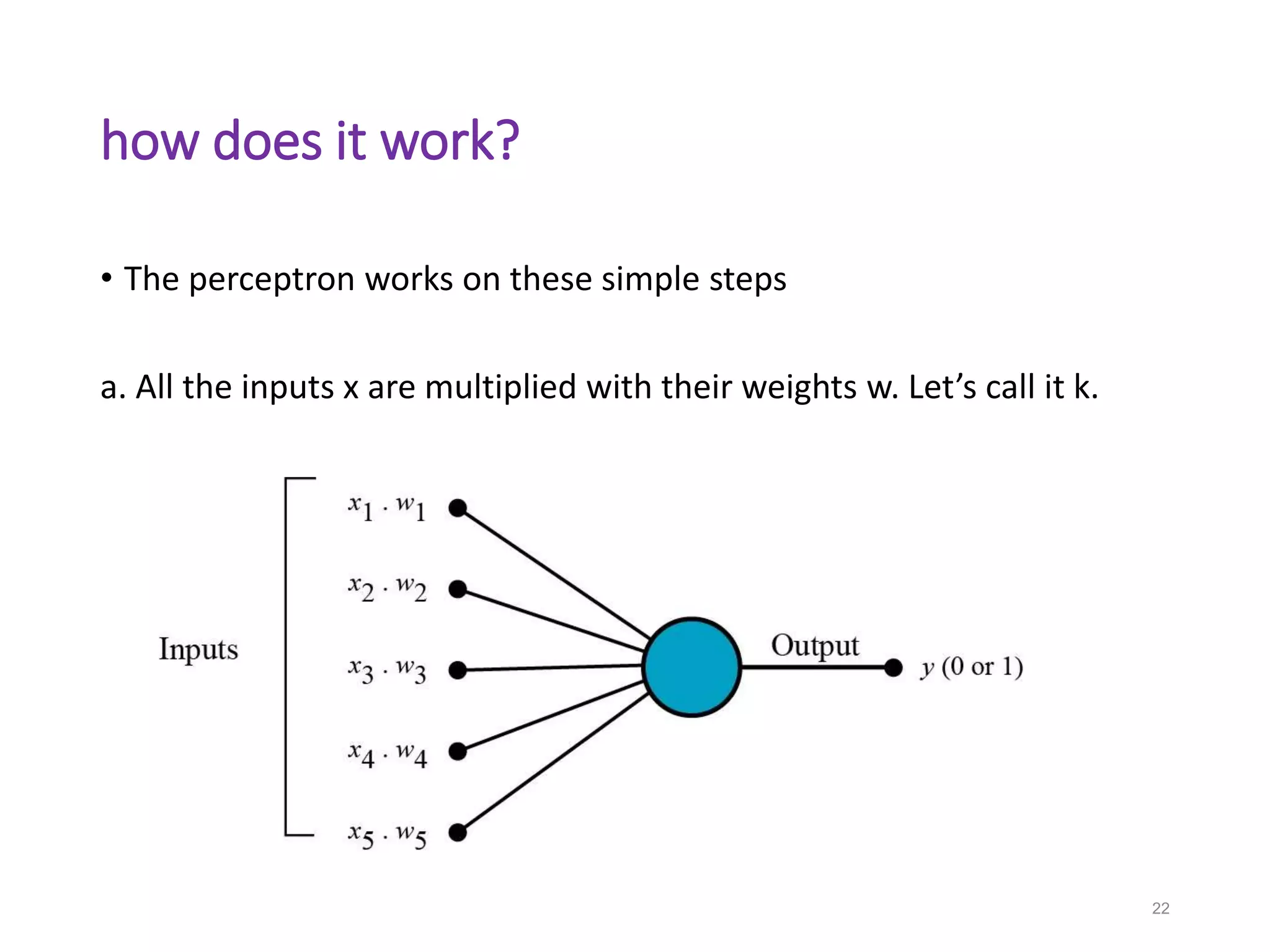
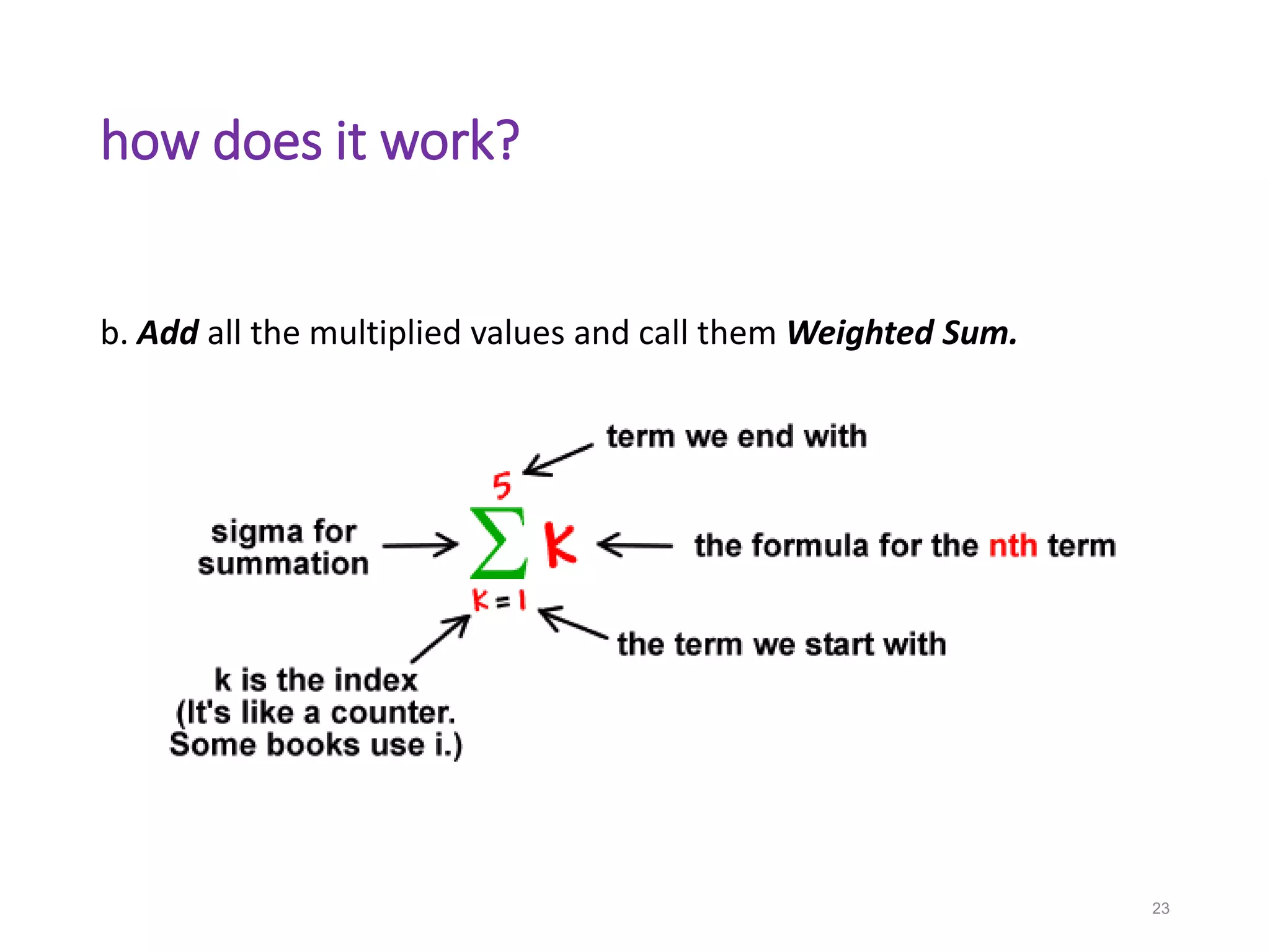



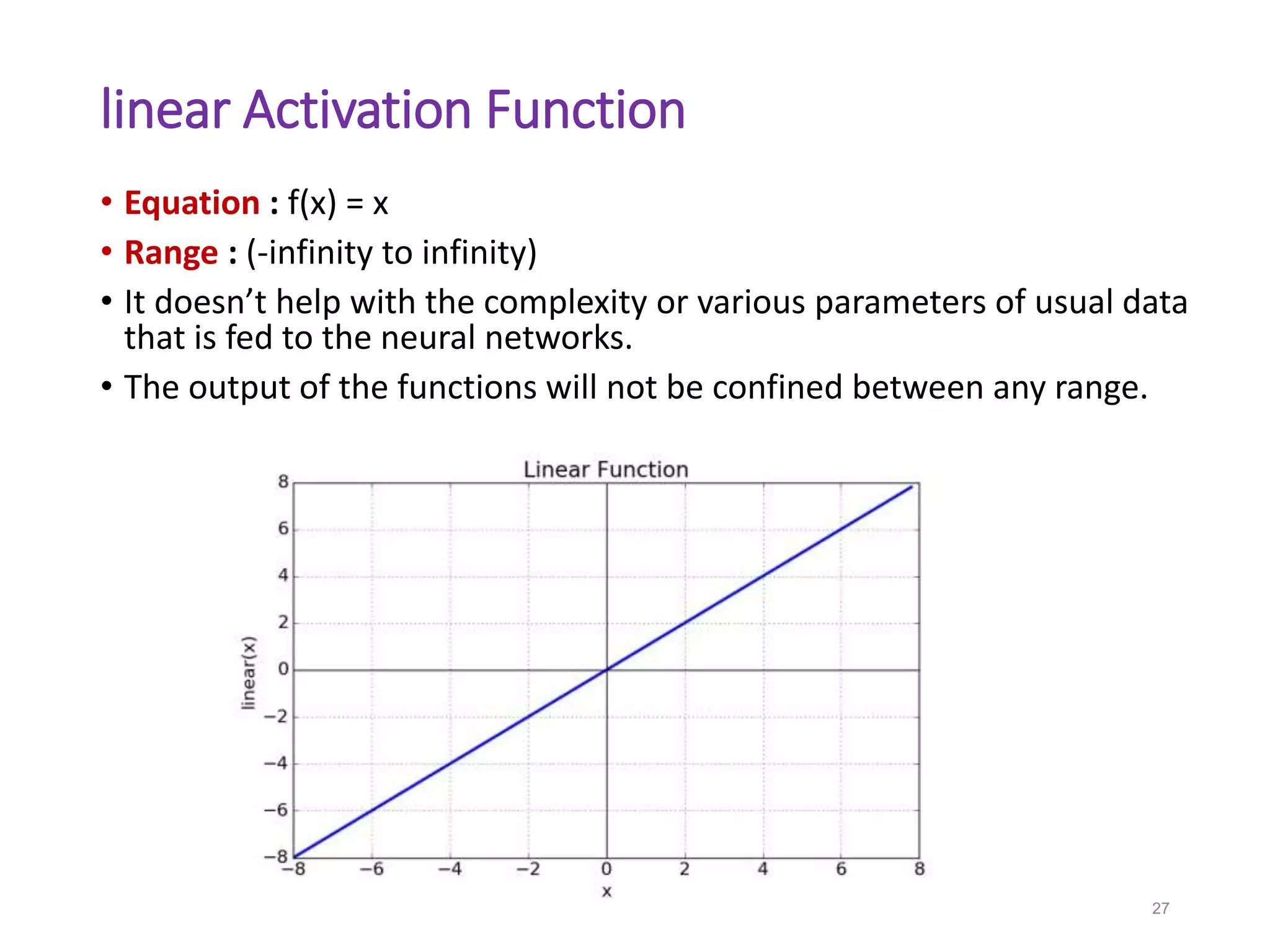
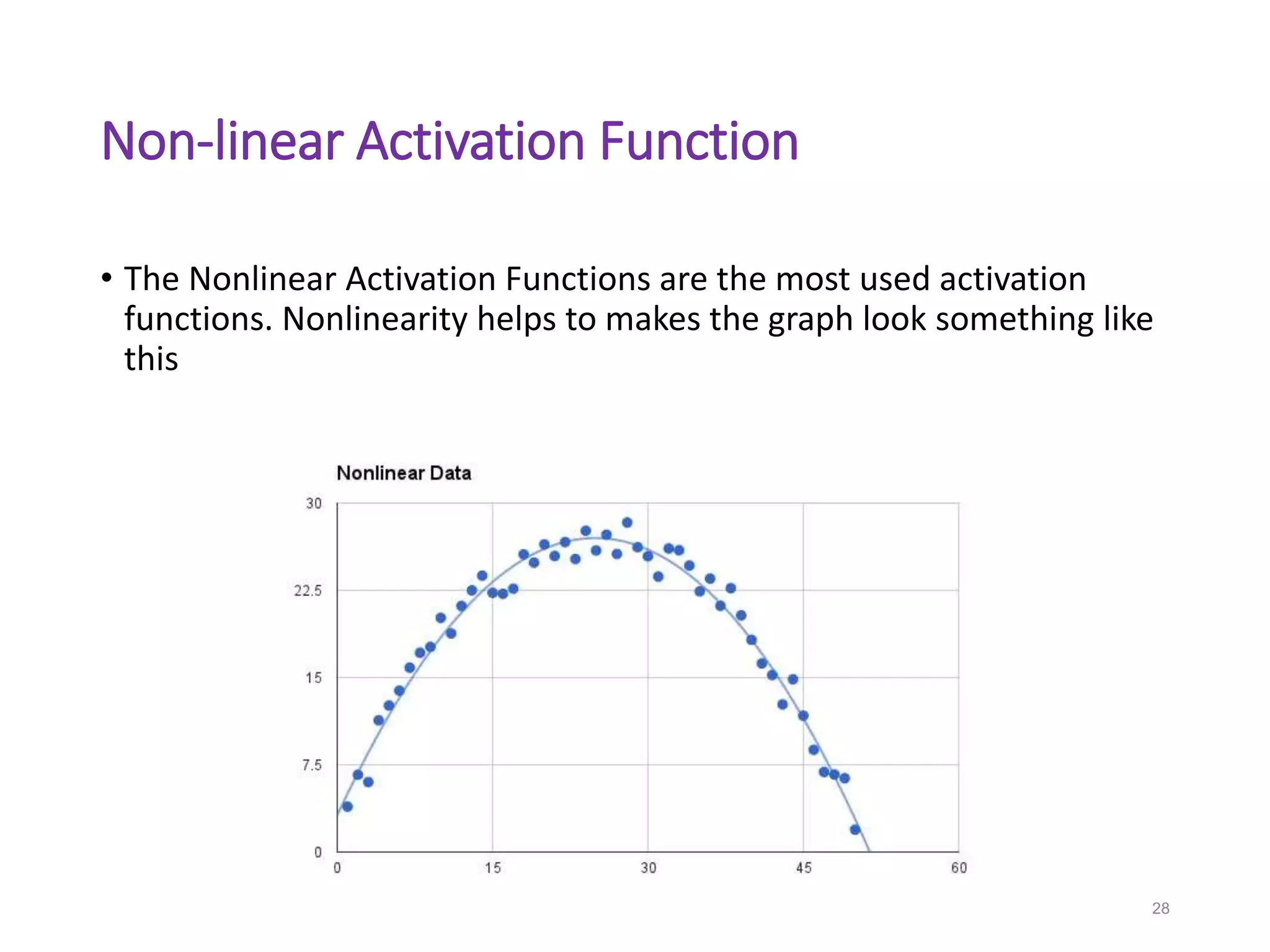









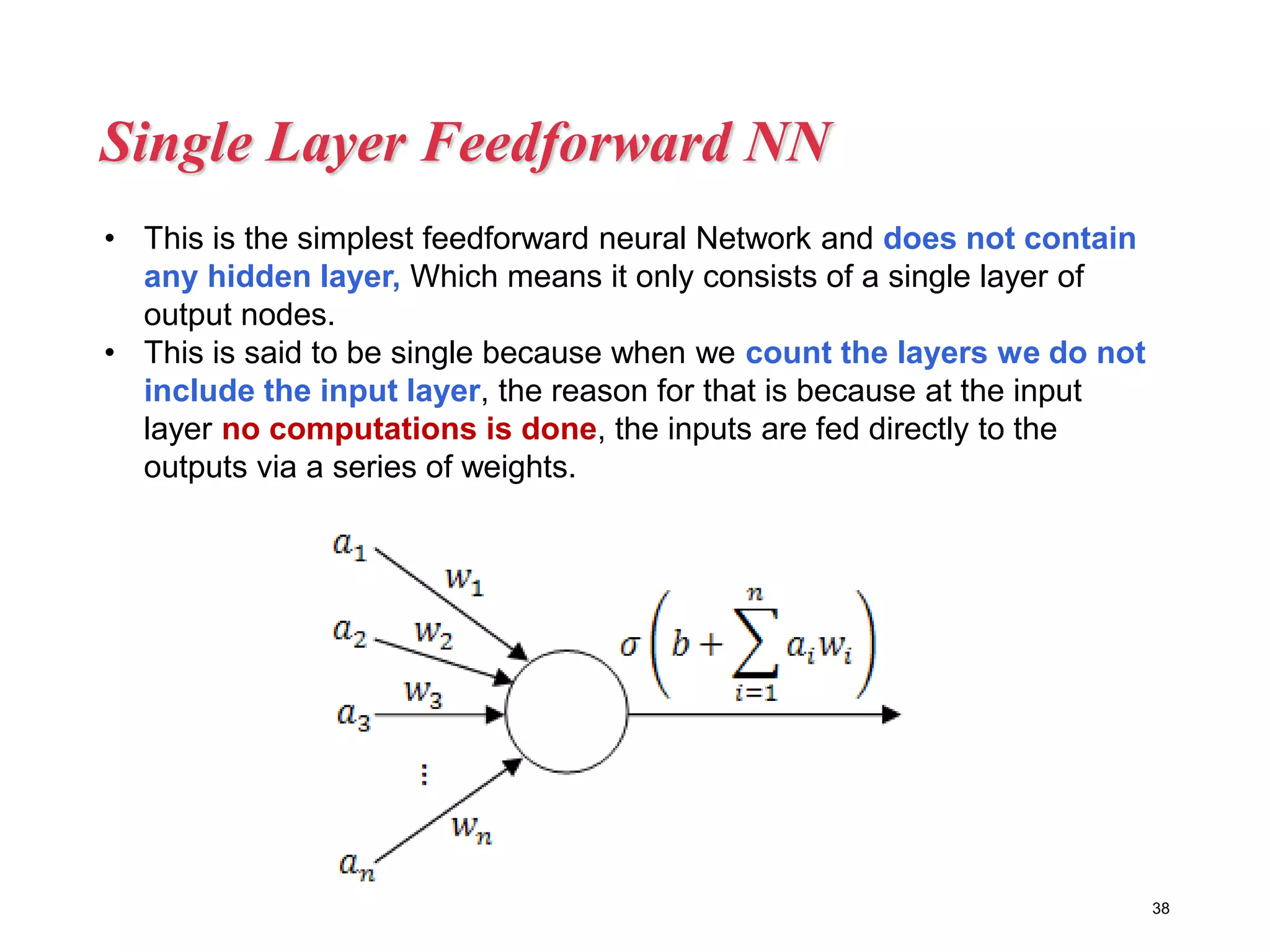
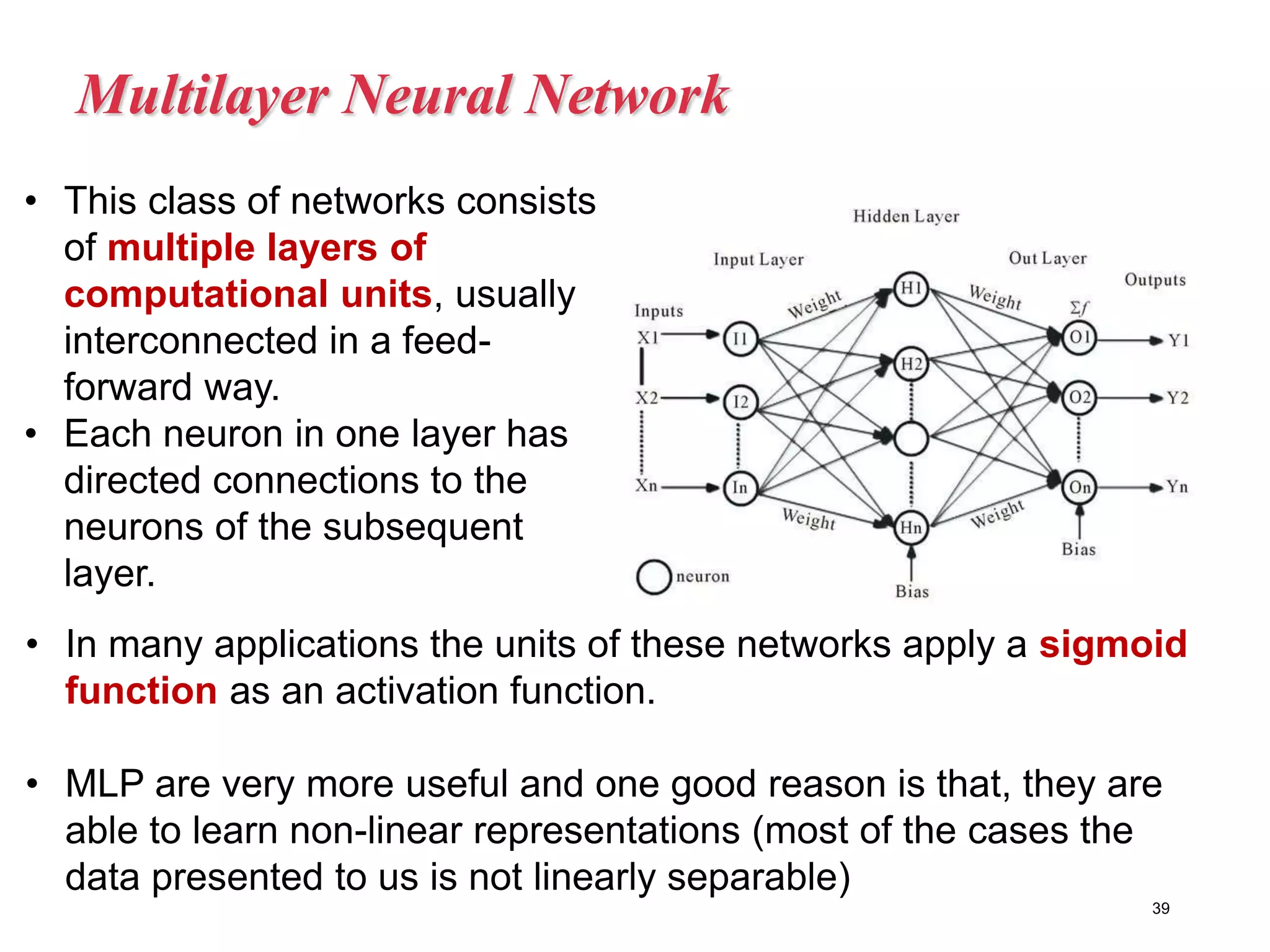

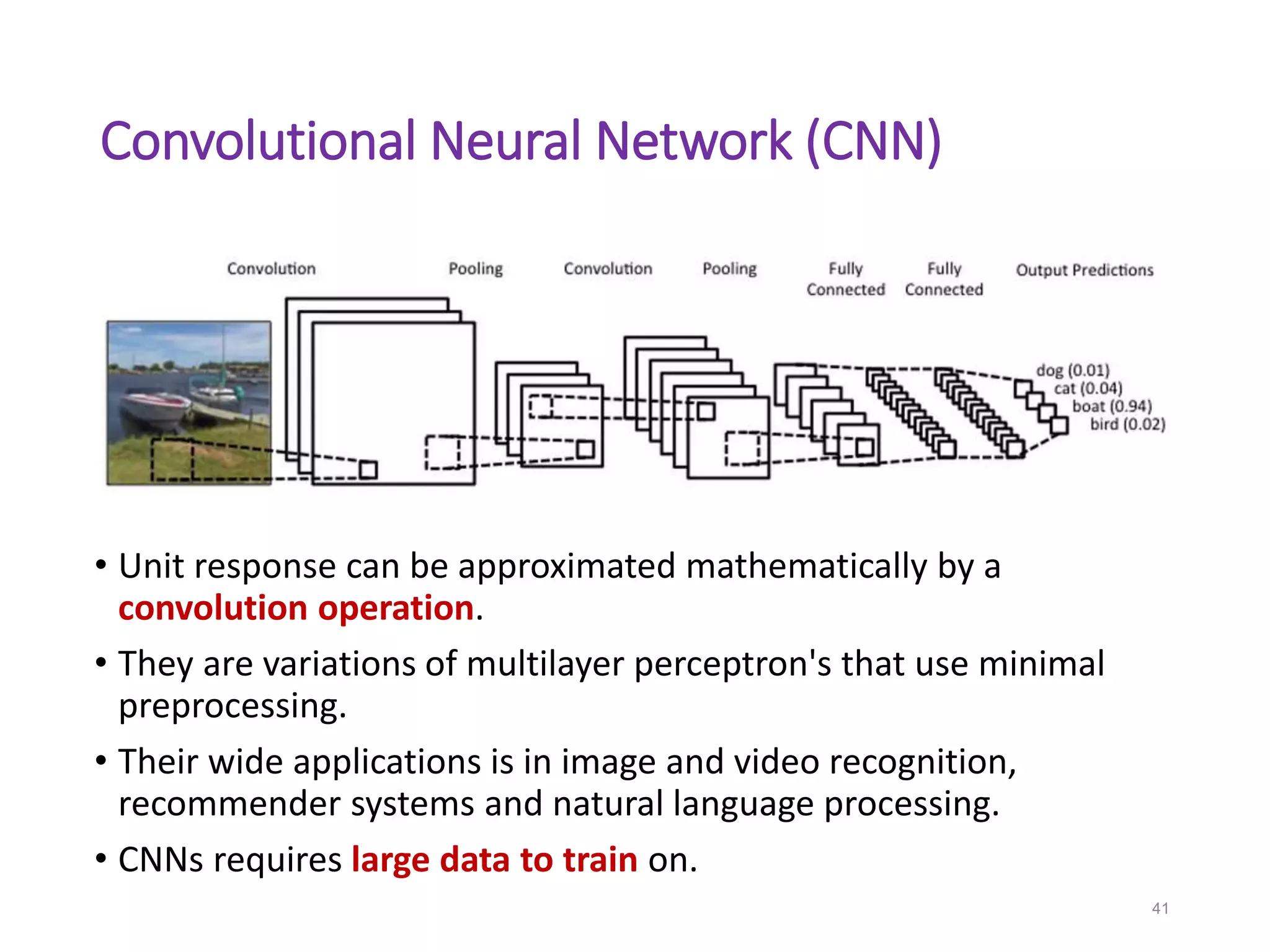

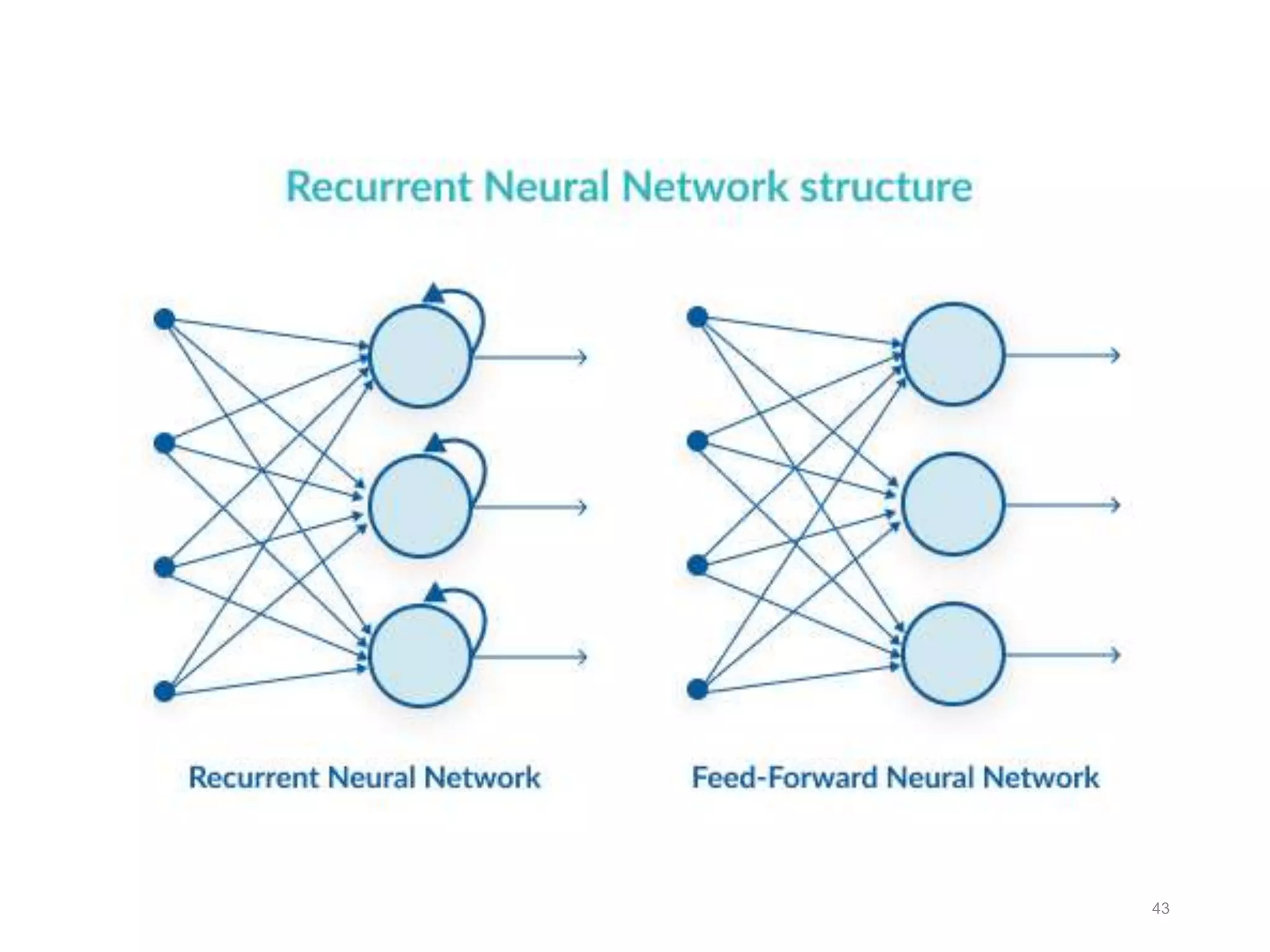













Neural networks are inspired by biological neurons and are used to learn relationships in data. The document defines an artificial neural network as a large number of interconnected processing elements called neurons that learn from examples. It outlines the key components of artificial neurons including weights, inputs, summation, and activation functions. Examples of neural network architectures include single-layer perceptrons, multi-layer perceptrons, convolutional neural networks, and recurrent neural networks. Common applications of neural networks include pattern recognition, data classification, and processing sequences.