WHAT ARE NEURALNETWORKS?
• BIOLOGICAL NEURAL NETWORKS INSPIRE THE COMPUTING SYSTEM TO PERFORM
DIFFERENT TASKS INVOLVING A VAST AMOUNT OF DATA, CALLED ARTIFICIAL
NEURAL NETWORKS OR ANN.
• DIFFERENT ALGORITHMS FROM THE CHANGING INPUTS WERE USED TO UNDERSTAND
THE RELATIONSHIPS IN A GIVEN DATA SET TO PRODUCE THE BEST RESULTS.
• THE NETWORK IS TRAINED TO PRODUCE THE DESIRED OUTPUTS, AND DIFFERENT
MODELS ARE USED TO PREDICT FUTURE RESULTS WITH THE DATA.
• THE NODES INTERCONNECT TO MIMIC THE FUNCTIONALITY OF THE HUMAN BRAIN.
• OTHER CORRELATIONS AND HIDDEN PATTERNS IN RAW DATA CLUSTER AND
CLASSIFY THE DATA.
3.
ARTIFICIAL NEURONS
• ARTIFICIALNEURONS ARE LIKE BIOLOGICAL NEURONS WHICH ARE CALLED AS
NODES.
• A NODE OR A NEURON CAN RECEIVE ONE OR MORE INPUT INFORMATION
AND PROCESS IT.
• ARTIFICIAL NEURONS OR NODES ARE CONNECTED BY CONNECTION LINKS TO
ONE ANOTHER.
• EACH CONNECTION LINK IS ASSOCIATED WITH A SYNAPTIC WEIGHT.
4.
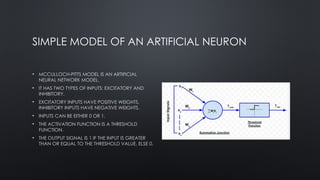
SIMPLE MODEL OFAN ARTIFICIAL NEURON
• MCCULLOCH-PITTS MODEL IS AN ARTIFICIAL
NEURAL NETWORK MODEL.
• IT HAS TWO TYPES OF INPUTS: EXCITATORY AND
INHIBITORY.
• EXCITATORY INPUTS HAVE POSITIVE WEIGHTS,
INHIBITORY INPUTS HAVE NEGATIVE WEIGHTS.
• INPUTS CAN BE EITHER 0 OR 1.
• THE ACTIVATION FUNCTION IS A THRESHOLD
FUNCTION.
• THE OUTPUT SIGNAL IS 1 IF THE INPUT IS GREATER
THAN OR EQUAL TO THE THRESHOLD VALUE, ELSE 0.
5.
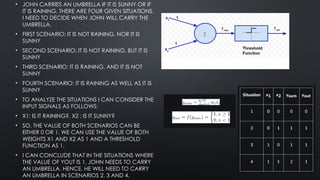
• JOHN CARRIESAN UMBRELLA IF IT IS SUNNY OR IF
IT IS RAINING. THERE ARE FOUR GIVEN SITUATIONS.
I NEED TO DECIDE WHEN JOHN WILL CARRY THE
UMBRELLA.
• FIRST SCENARIO: IT IS NOT RAINING, NOR IT IS
SUNNY
• SECOND SCENARIO: IT IS NOT RAINING, BUT IT IS
SUNNY
• THIRD SCENARIO: IT IS RAINING, AND IT IS NOT
SUNNY
• FOURTH SCENARIO: IT IS RAINING AS WELL AS IT IS
SUNNY
• TO ANALYZE THE SITUATIONS I CAN CONSIDER THE
INPUT SIGNALS AS FOLLOWS:
• X1: IS IT RAINING?, X2 : IS IT SUNNY?
• SO, THE VALUE OF BOTH SCENARIOS CAN BE
EITHER 0 OR 1. WE CAN USE THE VALUE OF BOTH
WEIGHTS X1 AND X2 AS 1 AND A THRESHOLD
FUNCTION AS 1.
• I CAN CONCLUDE THAT IN THE SITUATIONS WHERE
THE VALUE OF YOUT IS 1, JOHN NEEDS TO CARRY
AN UMBRELLA. HENCE, HE WILL NEED TO CARRY
AN UMBRELLA IN SCENARIOS 2, 3 AND 4.
6.
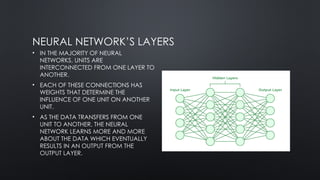
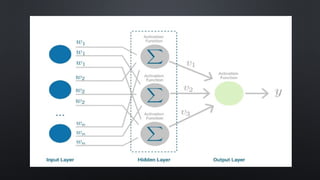
NEURAL NETWORK’S LAYERS
•THE NODE LAYER IS THE PUREST FORM OF THE NEURAL NETWORK, WHICH
CONTAINS THE THREE DIFFERENT LAYER TYPES AS BELOW.
• INPUT LAYER: IT CONTAINS THE NEURONS THAT RECEIVE INPUT. THE DATA IS
SUBSEQUENTLY PASSED ON TO THE NEXT TIER. THE INPUT LAYER’S TOTAL NUMBER
OF NEURONS IS EQUAL TO THE NUMBER OF VARIABLES IN THE DATASET.
• HIDDEN LAYER: THIS IS THE INTERMEDIATE LAYER, WHICH IS CONCEALED
BETWEEN THE INPUT AND OUTPUT LAYERS. THIS LAYER HAS A LARGE NUMBER OF
NEURONS THAT PERFORM ALTERATIONS ON THE INPUTS. THEY THEN
COMMUNICATE WITH THE OUTPUT LAYER.
• OUTPUT LAYER: IT IS THE LAST LAYER AND IS DEPENDING ON THE MODEL’S
CONSTRUCTION. ADDITIONALLY, THE OUTPUT LAYER IS THE EXPECTED FEATURE,
AS YOU ARE AWARE OF THE DESIRED OUTCOME.
7.
NEURAL NETWORK’S LAYERS
•IN THE MAJORITY OF NEURAL
NETWORKS, UNITS ARE
INTERCONNECTED FROM ONE LAYER TO
ANOTHER.
• EACH OF THESE CONNECTIONS HAS
WEIGHTS THAT DETERMINE THE
INFLUENCE OF ONE UNIT ON ANOTHER
UNIT.
• AS THE DATA TRANSFERS FROM ONE
UNIT TO ANOTHER, THE NEURAL
NETWORK LEARNS MORE AND MORE
ABOUT THE DATA WHICH EVENTUALLY
RESULTS IN AN OUTPUT FROM THE
OUTPUT LAYER.
8.
WHAT IS ANACTIVATION FUNCTION AND WHY
USE THEM?
• THE ACTIVATION FUNCTION DECIDES WHETHER A NEURON SHOULD BE
ACTIVATED OR NOT BY CALCULATING THE WEIGHTED SUM AND FURTHER
ADDING BIAS TO IT.
• THE PURPOSE OF THE ACTIVATION FUNCTION IS TO INTRODUCE NON-
LINEARITY INTO THE OUTPUT OF A NEURON.
9.
VARIANTS OF ACTIVATIONFUNCTION
LINEAR FUNCTION
• EQUATION : LINEAR FUNCTION HAS THE EQUATION SIMILAR TO AS OF A STRAIGHT LINE I.E. Y =
X
• NO MATTER HOW MANY LAYERS WE HAVE, IF ALL ARE LINEAR IN NATURE, THE FINAL
ACTIVATION FUNCTION OF LAST LAYER IS NOTHING BUT JUST A LINEAR FUNCTION OF THE
INPUT OF FIRST LAYER.
• RANGE : -INF TO +INF
• USES : LINEAR ACTIVATION FUNCTION IS USED AT JUST ONE PLACE I.E. OUTPUT LAYER.
• ISSUES : IF WE WILL DIFFERENTIATE LINEAR FUNCTION TO BRING NON-LINEARITY, RESULT WILL
NO MORE DEPEND ON INPUT “X” AND FUNCTION WILL BECOME CONSTANT, IT WON’T
INTRODUCE ANY GROUND-BREAKING BEHAVIOR TO OUR ALGORITHM.
• FOR EXAMPLE : CALCULATION OF PRICE OF A HOUSE IS A REGRESSION PROBLEM. HOUSE
PRICE MAY HAVE ANY BIG/SMALL VALUE, SO WE CAN APPLY LINEAR ACTIVATION AT OUTPUT
LAYER. EVEN IN THIS CASE NEURAL NET MUST HAVE ANY NON-LINEAR FUNCTION AT HIDDEN
LAYERS.
10.
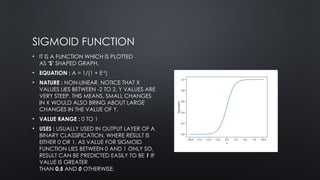
SIGMOID FUNCTION
• ITIS A FUNCTION WHICH IS PLOTTED
AS ‘S’ SHAPED GRAPH.
• EQUATION : A = 1/(1 + E-X
)
• NATURE : NON-LINEAR. NOTICE THAT X
VALUES LIES BETWEEN -2 TO 2, Y VALUES ARE
VERY STEEP. THIS MEANS, SMALL CHANGES
IN X WOULD ALSO BRING ABOUT LARGE
CHANGES IN THE VALUE OF Y.
• VALUE RANGE : 0 TO 1
• USES : USUALLY USED IN OUTPUT LAYER OF A
BINARY CLASSIFICATION, WHERE RESULT IS
EITHER 0 OR 1, AS VALUE FOR SIGMOID
FUNCTION LIES BETWEEN 0 AND 1 ONLY SO,
RESULT CAN BE PREDICTED EASILY TO BE 1 IF
VALUE IS GREATER
THAN 0.5 AND 0 OTHERWISE.
11.
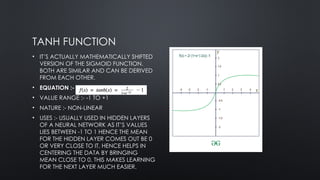
TANH FUNCTION
• IT’SACTUALLY MATHEMATICALLY SHIFTED
VERSION OF THE SIGMOID FUNCTION.
BOTH ARE SIMILAR AND CAN BE DERIVED
FROM EACH OTHER.
• EQUATION :-
• VALUE RANGE :- -1 TO +1
• NATURE :- NON-LINEAR
• USES :- USUALLY USED IN HIDDEN LAYERS
OF A NEURAL NETWORK AS IT’S VALUES
LIES BETWEEN -1 TO 1 HENCE THE MEAN
FOR THE HIDDEN LAYER COMES OUT BE 0
OR VERY CLOSE TO IT, HENCE HELPS IN
CENTERING THE DATA BY BRINGING
MEAN CLOSE TO 0. THIS MAKES LEARNING
FOR THE NEXT LAYER MUCH EASIER.
12.
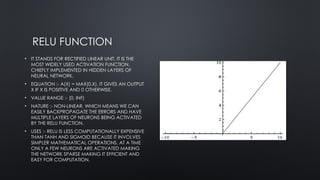
RELU FUNCTION
• ITSTANDS FOR RECTIFIED LINEAR UNIT. IT IS THE
MOST WIDELY USED ACTIVATION FUNCTION.
CHIEFLY IMPLEMENTED IN HIDDEN LAYERS OF
NEURAL NETWORK.
• EQUATION :- A(X) = MAX(0,X). IT GIVES AN OUTPUT
X IF X IS POSITIVE AND 0 OTHERWISE.
• VALUE RANGE :- [0, INF)
• NATURE :- NON-LINEAR, WHICH MEANS WE CAN
EASILY BACKPROPAGATE THE ERRORS AND HAVE
MULTIPLE LAYERS OF NEURONS BEING ACTIVATED
BY THE RELU FUNCTION.
• USES :- RELU IS LESS COMPUTATIONALLY EXPENSIVE
THAN TANH AND SIGMOID BECAUSE IT INVOLVES
SIMPLER MATHEMATICAL OPERATIONS. AT A TIME
ONLY A FEW NEURONS ARE ACTIVATED MAKING
THE NETWORK SPARSE MAKING IT EFFICIENT AND
EASY FOR COMPUTATION.
13.
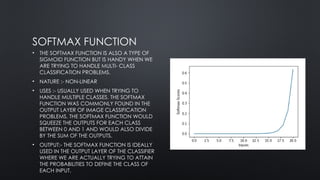
SOFTMAX FUNCTION
• THESOFTMAX FUNCTION IS ALSO A TYPE OF
SIGMOID FUNCTION BUT IS HANDY WHEN WE
ARE TRYING TO HANDLE MULTI- CLASS
CLASSIFICATION PROBLEMS.
• NATURE :- NON-LINEAR
• USES :- USUALLY USED WHEN TRYING TO
HANDLE MULTIPLE CLASSES. THE SOFTMAX
FUNCTION WAS COMMONLY FOUND IN THE
OUTPUT LAYER OF IMAGE CLASSIFICATION
PROBLEMS. THE SOFTMAX FUNCTION WOULD
SQUEEZE THE OUTPUTS FOR EACH CLASS
BETWEEN 0 AND 1 AND WOULD ALSO DIVIDE
BY THE SUM OF THE OUTPUTS.
• OUTPUT:- THE SOFTMAX FUNCTION IS IDEALLY
USED IN THE OUTPUT LAYER OF THE CLASSIFIER
WHERE WE ARE ACTUALLY TRYING TO ATTAIN
THE PROBABILITIES TO DEFINE THE CLASS OF
EACH INPUT.
14.
HOW DOES PERCEPTRONWORK?
• IN MACHINE LEARNING, PERCEPTRON IS CONSIDERED AS A SINGLE-LAYER
NEURAL NETWORK THAT CONSISTS OF FOUR MAIN PARAMETERS NAMED INPUT
VALUES (INPUT NODES), WEIGHTS AND BIAS, NET SUM, AND AN ACTIVATION
FUNCTION.
• THE PERCEPTRON MODEL BEGINS WITH THE MULTIPLICATION OF ALL INPUT
VALUES AND THEIR WEIGHTS, THEN ADDS THESE VALUES TOGETHER TO CREATE
THE WEIGHTED SUM. THEN THIS WEIGHTED SUM IS APPLIED TO THE ACTIVATION
FUNCTION 'F' TO OBTAIN THE DESIRED OUTPUT. THIS ACTIVATION FUNCTION IS
ALSO KNOWN AS THE STEP FUNCTION AND IS REPRESENTED BY 'F’.
• THIS STEP FUNCTION OR ACTIVATION FUNCTION PLAYS A VITAL ROLE IN
ENSURING THAT OUTPUT IS MAPPED BETWEEN REQUIRED VALUES (0,1) OR (-1,1).
IT IS IMPORTANT TO NOTE THAT THE WEIGHT OF INPUT IS INDICATIVE OF THE
STRENGTH OF A NODE. SIMILARLY, AN INPUT'S BIAS VALUE GIVES THE ABILITY TO
SHIFT THE ACTIVATION FUNCTION CURVE UP OR DOWN.
15.
• PERCEPTRON MODELWORKS IN TWO
IMPORTANT STEPS AS FOLLOWS:
• IN THE FIRST STEP FIRST, MULTIPLY ALL INPUT
VALUES WITH CORRESPONDING WEIGHT
VALUES AND THEN ADD THEM TO
DETERMINE THE WEIGHTED SUM.
MATHEMATICALLY, WE CAN CALCULATE
THE WEIGHTED SUM AS FOLLOWS:
∑WI*XI = X1*W1 + X2*W2 +…WN*XN
• ADD A SPECIAL TERM CALLED BIAS 'B' TO
THIS WEIGHTED SUM TO IMPROVE THE
MODEL’S PERFORMANCE.
∑WI*XI + B
• IN THE SECOND STEP, AN ACTIVATION
FUNCTION IS APPLIED WITH THE ABOVE-
MENTIONED WEIGHTED SUM, WHICH GIVES
US OUTPUT EITHER IN BINARY FORM OR A
CONTINUOUS VALUE AS FOLLOWS:
Y = F(∑WI*XI + B)
16.
• CALCULATE THEERROR BY SUBTRACTING THE ESTIMATED OUTPUT YESTIMATED
FROM THE DESIRED OUTPUT YDESIRED. ERROR E(T)= YDESIRED – YESTIMATED.
• UPDATE THE WEIGTHS IF THERE IS AN ERROR: ▲WI = * E(T) * XI, WI = WI + ▲WI
WHERE, XI IS THE INPUT VALUE, E(T) IS THE ERROR AT STEP T, IS THE LEARNING
RATE AND ▲WI IS THE DIFFERENCE IN WEIGHT THAT HAS TO BE ADDED TO WI.
17.
SINGLE-LAYER FEED-FORWARD NETWORK
•A SINGLE-LAYER FEED-FORWARD
NETWORK IS A TYPE OF NEURAL
NETWORK THAT HAS ONLY ONE LAYER
OF NEURONS THAT DIRECTLY CONNECTS
THE INPUT TO THE OUTPUT. THIS TYPE OF
NETWORK IS ALSO KNOWN AS A
PERCEPTRON.
18.
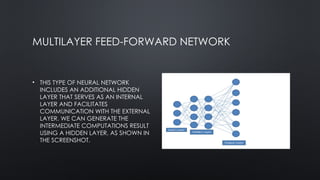
MULTILAYER FEED-FORWARD NETWORK
•THIS TYPE OF NEURAL NETWORK
INCLUDES AN ADDITIONAL HIDDEN
LAYER THAT SERVES AS AN INTERNAL
LAYER AND FACILITATES
COMMUNICATION WITH THE EXTERNAL
LAYER. WE CAN GENERATE THE
INTERMEDIATE COMPUTATIONS RESULT
USING A HIDDEN LAYER, AS SHOWN IN
THE SCREENSHOT.
19.
FULLY CONNECTED NEURALNETWORK
• A FULLY CONNECTED NEURAL NETWORK
CONSISTS OF A SERIES OF FULLY CONNECTED
LAYERS THAT CONNECT EVERY NEURON IN
ONE LAYER TO EVERY NEURON IN THE OTHER
LAYER.
• THE MAJOR ADVANTAGE OF FULLY
CONNECTED NETWORKS IS THAT THEY ARE
“STRUCTURE AGNOSTIC” I.E. THERE ARE NO
SPECIAL ASSUMPTIONS NEEDED TO BE MADE
ABOUT THE INPUT.
• WHILE BEING STRUCTURE AGNOSTIC MAKES
FULLY CONNECTED NETWORKS VERY
BROADLY APPLICABLE, SUCH NETWORKS DO
TEND TO HAVE WEAKER PERFORMANCE THAN
SPECIAL-PURPOSE NETWORKS TUNED TO THE
STRUCTURE OF A PROBLEM SPACE.
20.
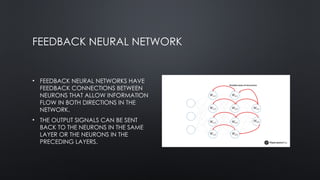
FEEDBACK NEURAL NETWORK
•FEEDBACK NEURAL NETWORKS HAVE
FEEDBACK CONNECTIONS BETWEEN
NEURONS THAT ALLOW INFORMATION
FLOW IN BOTH DIRECTIONS IN THE
NETWORK.
• THE OUTPUT SIGNALS CAN BE SENT
BACK TO THE NEURONS IN THE SAME
LAYER OR THE NEURONS IN THE
PRECEDING LAYERS.
21.
MULTI-LAYERED PERCEPTRON MODEL
•THE MULTI-LAYER PERCEPTRON MODEL IS ALSO KNOWN AS THE BACKPROPAGATION ALGORITHM,
WHICH EXECUTES IN TWO STAGES AS FOLLOWS:
• FORWARD STAGE: ACTIVATION FUNCTIONS START FROM THE INPUT LAYER IN THE FORWARD STAGE
AND TERMINATE ON THE OUTPUT LAYER.
• BACKWARD STAGE: IN THE BACKWARD STAGE, WEIGHT AND BIAS VALUES ARE MODIFIED AS PER
THE MODEL'S REQUIREMENT. IN THIS STAGE, THE ERROR BETWEEN ACTUAL OUTPUT AND
DEMANDED ORIGINATED BACKWARD ON THE OUTPUT LAYER AND ENDED ON THE INPUT LAYER.
• HENCE, A MULTI-LAYERED PERCEPTRON MODEL HAS CONSIDERED AS MULTIPLE ARTIFICIAL NEURAL
NETWORKS HAVING VARIOUS LAYERS IN WHICH ACTIVATION FUNCTION DOES NOT REMAIN
LINEAR. INSTEAD OF LINEAR, ACTIVATION FUNCTION CAN BE EXECUTED AS SIGMOID, TANH, RELU,
ETC., FOR DEPLOYMENT.
• A MULTI-LAYER PERCEPTRON MODEL HAS GREATER PROCESSING POWER AND CAN PROCESS
LINEAR AND NON-LINEAR PATTERNS. FURTHER, IT CAN ALSO IMPLEMENT LOGIC GATES SUCH AS
AND, OR, XOR, NAND, NOT, XNOR, NOR.
23.
A SIMPLIFIED VERSIONOF THE FEED FORWARD
NEURAL NETWORK ALGORITHM:
• INITIALIZE THE WEIGHTS: RANDOMLY INITIALIZE THE WEIGHTS OF THE NEURAL NETWORK.
• INPUT LAYER: PROVIDE THE INPUT DATA TO THE INPUT LAYER.
• HIDDEN LAYERS: CALCULATE THE WEIGHTED SUM OF THE INPUTS AND WEIGHTS, AND PASS THIS THROUGH AN ACTIVATION
FUNCTION (LIKE RELU, SIGMOID, ETC.). THIS IS DONE FOR EACH NEURON IN THE HIDDEN LAYERS.
• OUTPUT LAYER: REPEAT THE PROCESS OF CALCULATING WEIGHTED SUMS AND APPLYING AN ACTIVATION FUNCTION TO
GET THE FINAL OUTPUT.
• ERROR CALCULATION: CALCULATE THE ERROR IN THE OUTPUT, WHICH IS THE DIFFERENCE BETWEEN THE PREDICTED OUTPUT
AND THE ACTUAL OUTPUT.
• BACKPROPAGATION (OPTIONAL): ALTHOUGH NOT A PART OF FEED FORWARD PROCESS, BACKPROPAGATION IS USED IN
TRAINING A NEURAL NETWORK WHERE THE ERROR IS PASSED BACK THROUGH THE NETWORK. THIS HELPS IN ADJUSTING THE
WEIGHTS WHICH MINIMIZES THE ERROR DURING PREDICTION.
• REPEAT STEPS 2-6: FOR EACH PIECE OF DATA IN OUR TRAINING SET, REPEAT STEPS 2-6. THE GOAL IS TO ADJUST THE
WEIGHTS IN SUCH A WAY THAT THE ERROR IN OUR PREDICTIONS IS MINIMIZED.
24.
SELF-ORGANIZING FEATURE MAP
•SOFMS ARE A TYPE OF ARTIFICIAL NEURAL NETWORK THAT CAN BE USED TO REDUCE THE
DIMENSIONALITY OF DATA AND TO CLUSTER DATA INTO GROUPS.
• SOFMS ARE UNSUPERVISED LEARNING MODELS, WHICH MEANS THAT THEY DO NOT REQUIRE LABELED
DATA TO TRAIN.
• SOFMS WORK BY MAPPING HIGH-DIMENSIONAL DATA INTO A TWO-DIMENSIONAL GRID OF NODES.
• THE MODEL LEARNS TO CLUSTER OR SELF ORGANIZE A HIGH-DIMENSIONAL DATA WITHOUT KNOWING
THE CLASS MEMBERSHIP OF THE INPUT DATA, AND HENCE THE NAME SELF-ORGANIZING NODES.
• THESE SELF-ORGANIZING NODES ARE ALSO CALLED AS FEATURE MAPS.
• THE MAPPING IS BASED ON THE RELATIVE STANCE OR SIMILARITY BETWEEN THE POINTS AND THE POINTS
THAT ARE NEAR TO EACH OTHER IN THE INPUT SPACE ARE MAPPED TO NEARBY OUTPUT MAP UNITS IN THE
SOFM.
25.
NETWORK ARCHITECTURE ANDOPERATIONS
• SOFMS ARE A TYPE OF ARTIFICIAL NEURAL NETWORK THAT CAN BE USED TO REDUCE THE DIMENSIONALITY OF
DATA AND TO CLUSTER DATA INTO GROUPS.
• THE NETWORK ARCHITECTURE CONSISTS OF ONLY TWO LAYERS: THE INPUT LAYER AND THE OUTPUT LAYER.
• THERE ARE NO HIDDEN LAYERS IN A SOFM NETWORK.
• THE NUMBER OF UNITS IN THE INPUT LAYER IS BASED ON THE LENGTH OF THE INPUT SAMPLES, WHICH IS A
VECTOR OF LENGTH 'N'.
• EACH CONNECTION FROM THE INPUT UNITS IN THE INPUT LAYER TO THE OUTPUT UNITS IN THE OUTPUT LAYER IS
ASSIGNED WITH RANDOM WEIGHTS.
• THERE IS ONE WEIGHT VECTOR OF LENGTH 'N' ASSOCIATED WITH EACH OUTPUT UNIT.
• OUTPUT UNITS HAVE INTRA-LAYER CONNECTIONS WITH NO WEIGHTS ASSIGNED BETWEEN THESE
CONNECTIONS, BUT THESE CONNECTIONS ARE USED FOR UPDATING THE WEIGHTS.
26.
NETWORK ARCHITECTURE ANDOPERATIONS
• THE NETWORK OPERATES IN TWO PHASES, THE TRAINING PHASE AND THE MAPPING PHASE.
• DURING THE TRAINING PHASE:
• THE INPUT LAYER IS FED WITH INPUT SAMPLES RANDOMLY FROM THE TRAINING DATA.
• THE UNITS OR NEURONS IN THE OUTPUT LAYER ARE INITIALLY ASSIGNED WITH SOME WEIGHTS.
• AS THE INPUT SAMPLE IS FED, EACH OUTPUT UNIT COMPUTES A SIMILARITY SCORE BY EUCLIDEAN
DISTANCE MEASURE AND COMPETE WITH EACH OTHER.
• THE OUTPUT UNIT, WHICH IS CLOSE TO THE INPUT SAMPLE BY SIMILAR LEARNING FACTOR IS CHOSEN AS
THE WINNING UNIT AND ITS CONNECTION WEIGHTS ARE ADJUSTED BY A LEARNING RATE.
• THUS, THE BEST MATCHING OUTPUT UNIT WHOSE WEIGHTS ARE ADJUSTED ARE MOVED CLOSE TO THE
INPUT SAMPLE AND A TOPOLOGICAL FEATURE MAP IS FORMED.
• THIS PROCESS IS REPEATED UNTIL THE MAP DOES NOT CHANGE.
• DURING THE MAPPING PHASE:
• THE TEST SAMPLES ARE JUST CLASSIFIED.
27.
SELF-ORGANIZING FEATURE MAPALGORITHM
• STEP 1: INITIALIZE THE WEIGHTS WIJ RANDOM VALUE MAY BE ASSUMED. INITIALIZE THE LEARNING RATE Α.
• STEP 2: CALCULATE SQUARED EUCLIDEAN DISTANCE
• D(J) = Σ (WIJ – XI)^2 WHERE I=1 TO N AND J=1 TO M
• STEP 3: FIND INDEX J, WHEN D(J) IS MINIMUM THAT WILL BE CONSIDERED AS WINNING INDEX.
• STEP 4: FOR EACH J WITHIN A SPECIFIC NEIGHBORHOOD OF J AND FOR ALL I, CALCULATE THE NEW
WEIGHT.
• WIJ(NEW)=WIJ(OLD) + Α[XI – WIJ(OLD)]
• STEP 5: UPDATE THE LEARNING RULE BY USING :
• Α(T+1) = 0.5 * T
• STEP 6: TEST THE STOPPING CONDITION.
28.
APPLICATIONS OF NEURALNETWORK
• RECOGNITION OF HANDWRITING: NEURAL NETWORKS CONVERT WRITTEN TEXT
INTO CHARACTERS THAT MACHINES CAN RECOGNIZE.
• STOCK EXCHANGE PREDICTION: THE STOCK EXCHANGE IS INFLUENCED BY
NUMEROUS FACTORS, MAKING IT DIFFICULT TO MONITOR AND COMPREHEND.
ON THE OTHER HAND, A NEURAL NETWORK CAN LOOK AT MANY OF THESE
FACTORS AND MAKE DAILY PRICE PREDICTIONS, WHICH WOULD BE HELPFUL TO
STOCKBROKERS.
• TRAVELING ISSUES OF SALES: IT’S ABOUT FIGURING OUT THE BEST WAY TO GET
FROM ONE CITY TO ANOTHER IN A GIVEN AREA. NEURAL NETWORKS CAN
ADDRESS THE ISSUE OF GENERATING MORE REVENUE AT LOWER COSTS.
• IMAGE COMPRESSION: IT HELPS US TO COMPRESS THE DATA TO STORE THE
ENCRYPTED FORM OF THE ACTUAL IMAGE.
29.
ADVANTAGES OF NEURALNETWORK
• CAN WORK WITH INCOMPLETE INFORMATION ONCE TRAINED.
• HAVE THE ABILITY TO FAULT TOLERANCE.
• HAVE A DISTRIBUTED MEMORY.
• PARALLEL PROCESSING.
• STORES INFORMATION ON AN ENTIRE NETWORK.
• THE ABILITY TO GENERALIZE, I.E., CAN INFER UNSEEN RELATIONSHIPS AFTER
LEARNING FROM SOME PRIOR RELATIONSHIPS.
30.
DISADVANTAGES OF ANN
•TRAINING REQUIREMENT: ANNS REQUIRE TRAINING TO OPERATE.
• HIGH PROCESSING TIME AND POWER: THEY NEED HIGH PROCESSING TIME AND COMPUTATIONAL POWER FOR LARGE
NEURAL NETWORKS.
• INTERPRETABILITY: ANNS ARE HARD TO EXPLAIN AND INTERPRET. THEY HAVE BEEN CRITICIZED FOR THEIR POOR
INTERPRETABILITY, AS IT IS DIFFICULT FOR HUMANS TO UNDERSTAND THE SYMBOLIC MEANING BEHIND THE LEARNED
WEIGHTS.
• DATA REQUIREMENT: THEY REQUIRE LARGE AMOUNTS OF DATA FOR TRAINING.
• DATA PREPARATION: THEY NEED CAREFUL DATA PREPARATION AND OPTIMIZATION FOR PRODUCTION.
• OVERFITTING: ANNS CAN BECOME TOO COMPLEX BECAUSE OF THEIR ARCHITECTURE AND THE HUGE DATASETS USED TO
TRAIN THEM. THEY CAN ALSO MEMORIZE THE TRAINING DATA, LEADING TO POOR GENERALIZATION OF NEW DATA.
• DEVELOPMENT TIME: THE DURATION OF THE DEVELOPMENT OF THE NETWORK CAN BE LONG AND UNKNOWN.
• NETWORK STRUCTURE: THERE IS NO ASSURANCE OF A PROPER NETWORK STRUCTURE
31.
CHALLENGES OF ARTIFICIALNEURAL NETWORKS
• TRAINING A NEURAL NETWORK IS THE MOST CHALLENGING PART OF USING
THIS TECHNIQUE. OVERFITTING OR UNDERFITTING ISSUES MAY ARISE IF
DATASETS USED FOR TRAINING ARE NOT CORRECT. IT IS ALSO HARD TO
GENERALIZE TO THE REAL-WORLD DATA WHEN TRAINED WITH SOME
SIMULATED DATA. MOREOVER, NEURAL NETWORK MODELS NORMALLY NEED
A LOT OF TRAINING DATA TO BE ROBUST AND ARE USABLE FOR A REAL-TIME
APPLICATION.
• FINDING THE WEIGHT AND BIAS PARAMETERS FOR NEURAL NETWORKS IS ALSO
HARD AND IT IS DIFFICULT TO CALCULATE AN OPTIMAL MODEL.
















![SELF-ORGANIZING FEATURE MAP ALGORITHM
• STEP 1: INITIALIZE THE WEIGHTS WIJ RANDOM VALUE MAY BE ASSUMED. INITIALIZE THE LEARNING RATE Α.
• STEP 2: CALCULATE SQUARED EUCLIDEAN DISTANCE
• D(J) = Σ (WIJ – XI)^2 WHERE I=1 TO N AND J=1 TO M
• STEP 3: FIND INDEX J, WHEN D(J) IS MINIMUM THAT WILL BE CONSIDERED AS WINNING INDEX.
• STEP 4: FOR EACH J WITHIN A SPECIFIC NEIGHBORHOOD OF J AND FOR ALL I, CALCULATE THE NEW
WEIGHT.
• WIJ(NEW)=WIJ(OLD) + Α[XI – WIJ(OLD)]
• STEP 5: UPDATE THE LEARNING RULE BY USING :
• Α(T+1) = 0.5 * T
• STEP 6: TEST THE STOPPING CONDITION.](https://image.slidesharecdn.com/neuralnetworks-250421045524-d3ab3feb/85/Neural-Networks-in-Artificial-intelligence-27-320.jpg)



















































