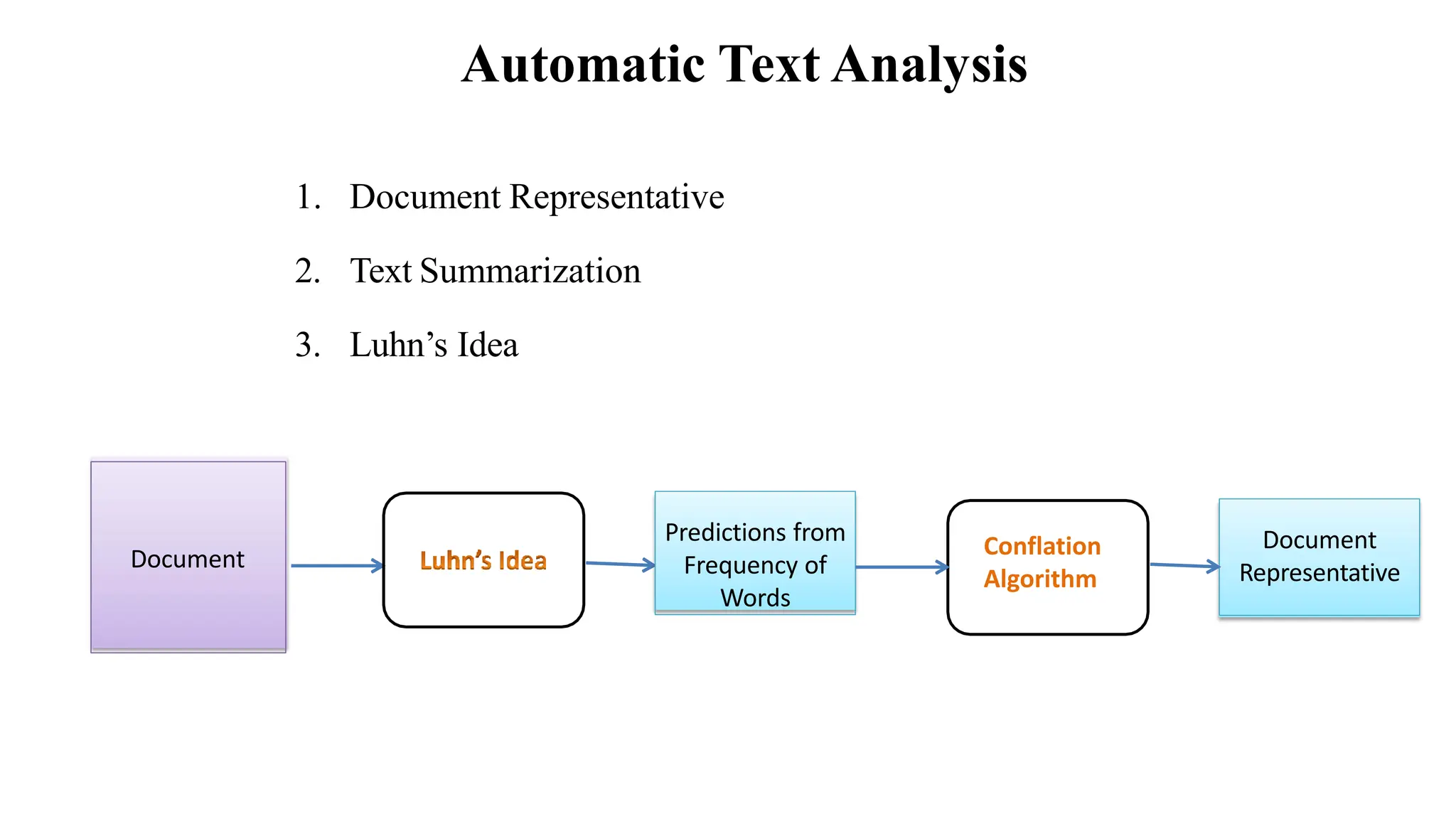
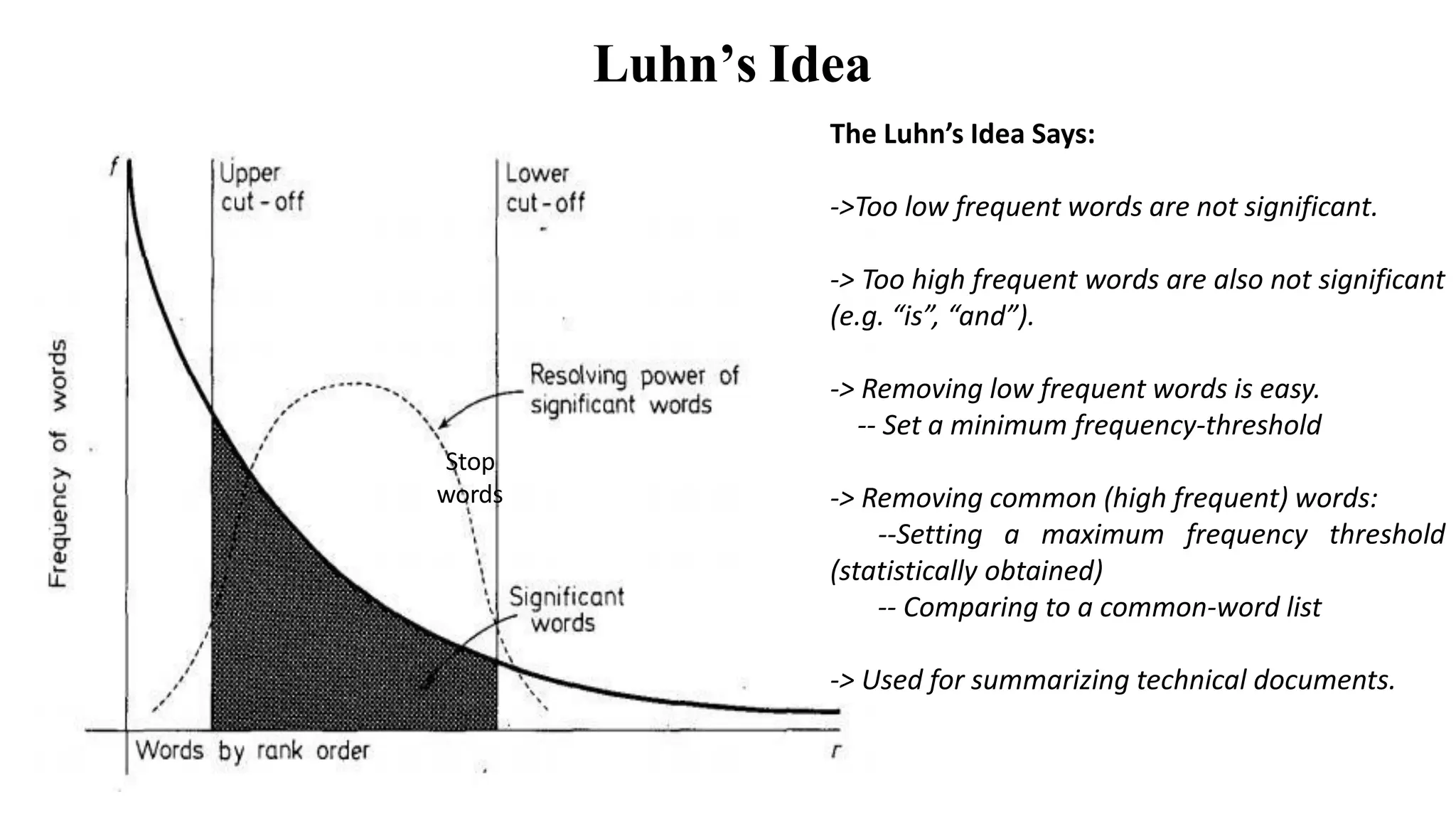
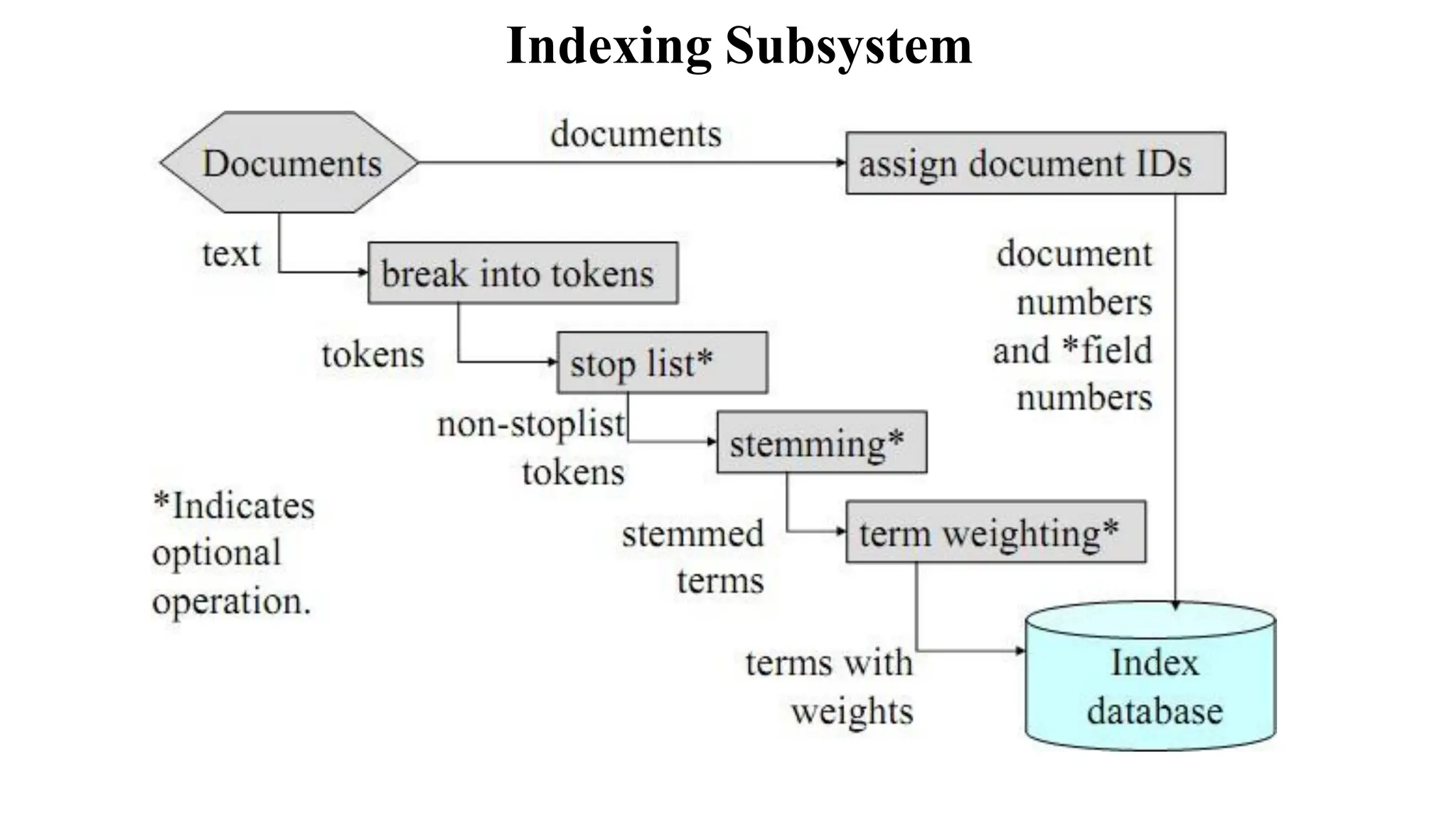
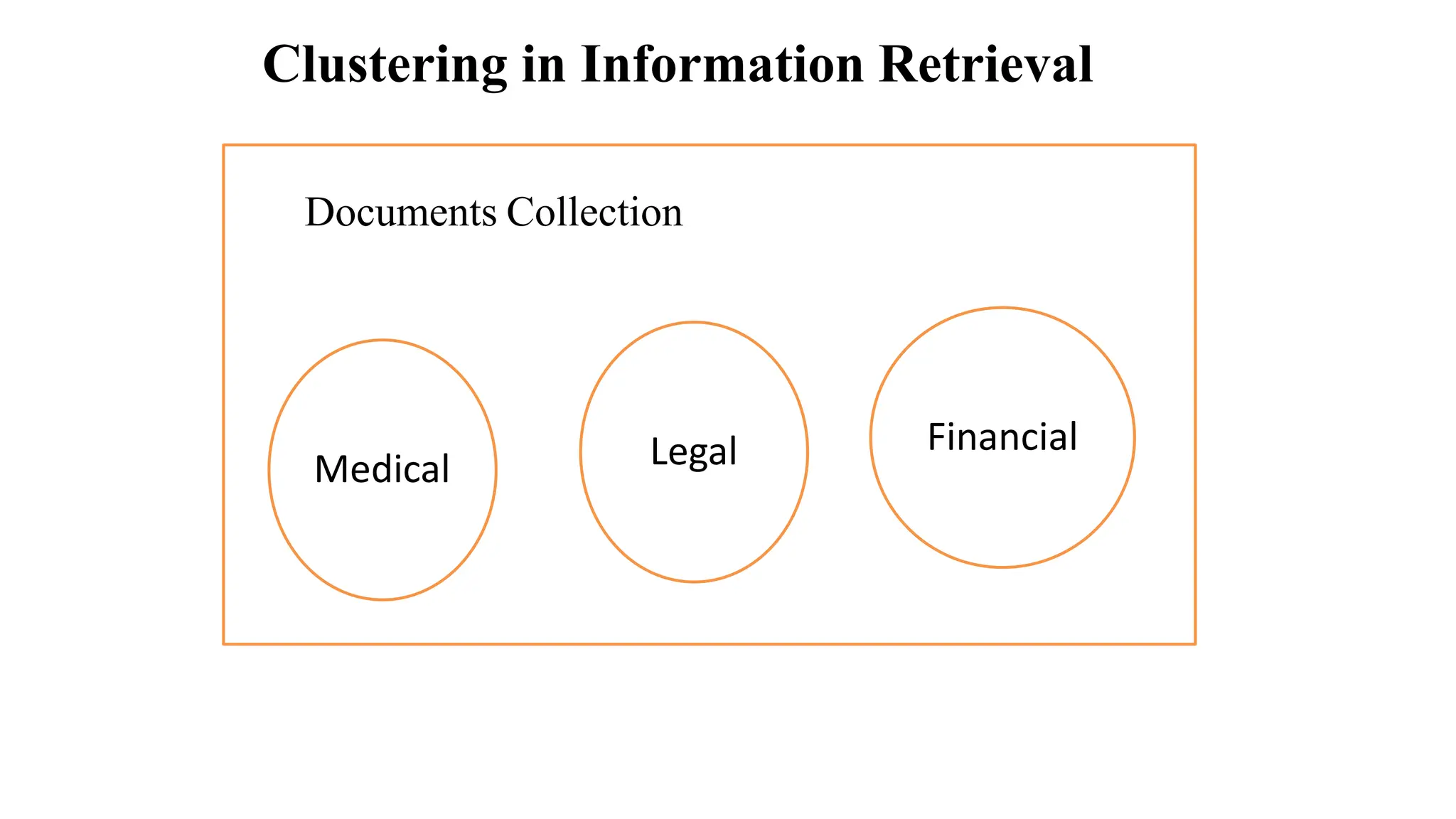
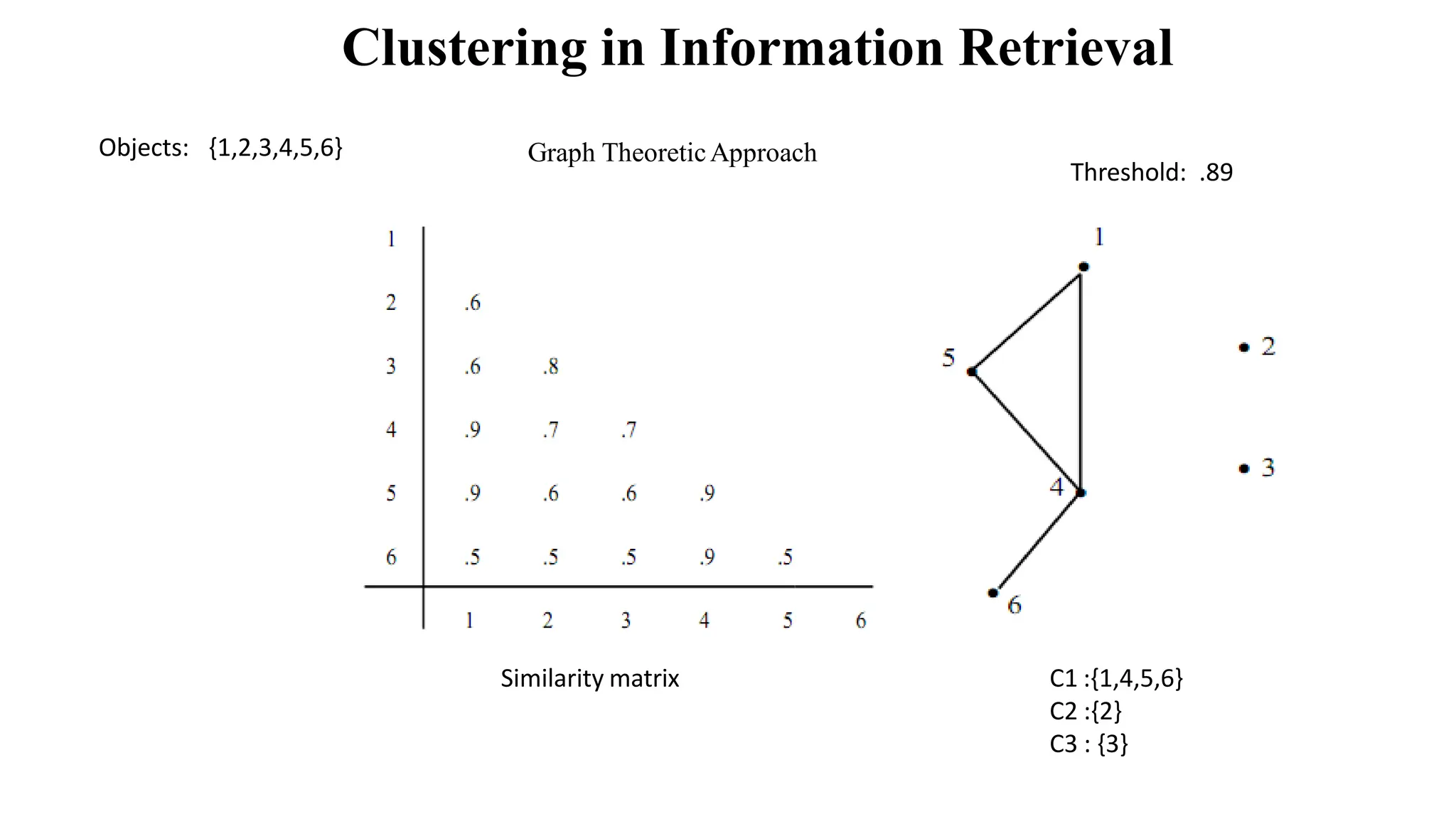
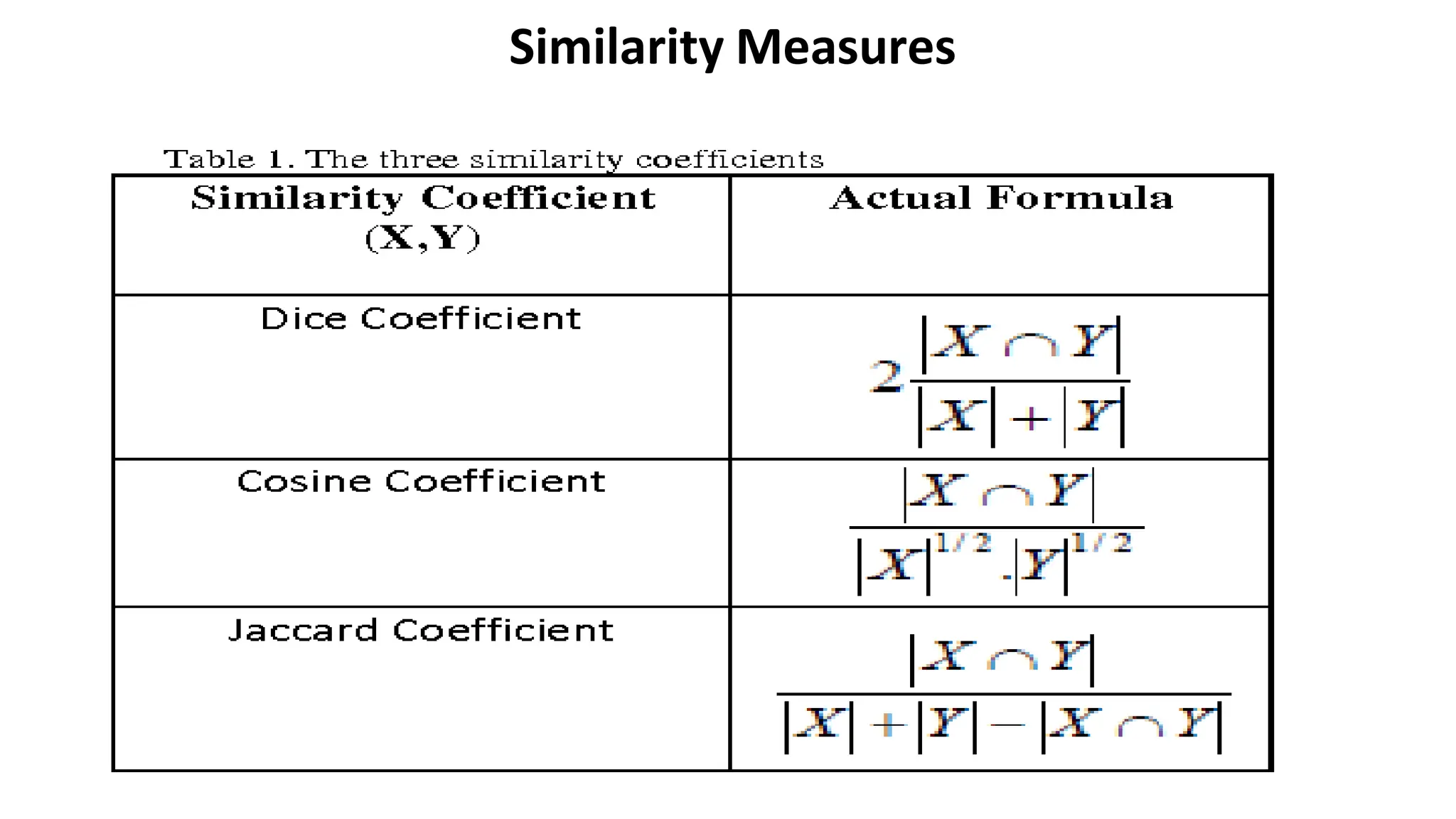
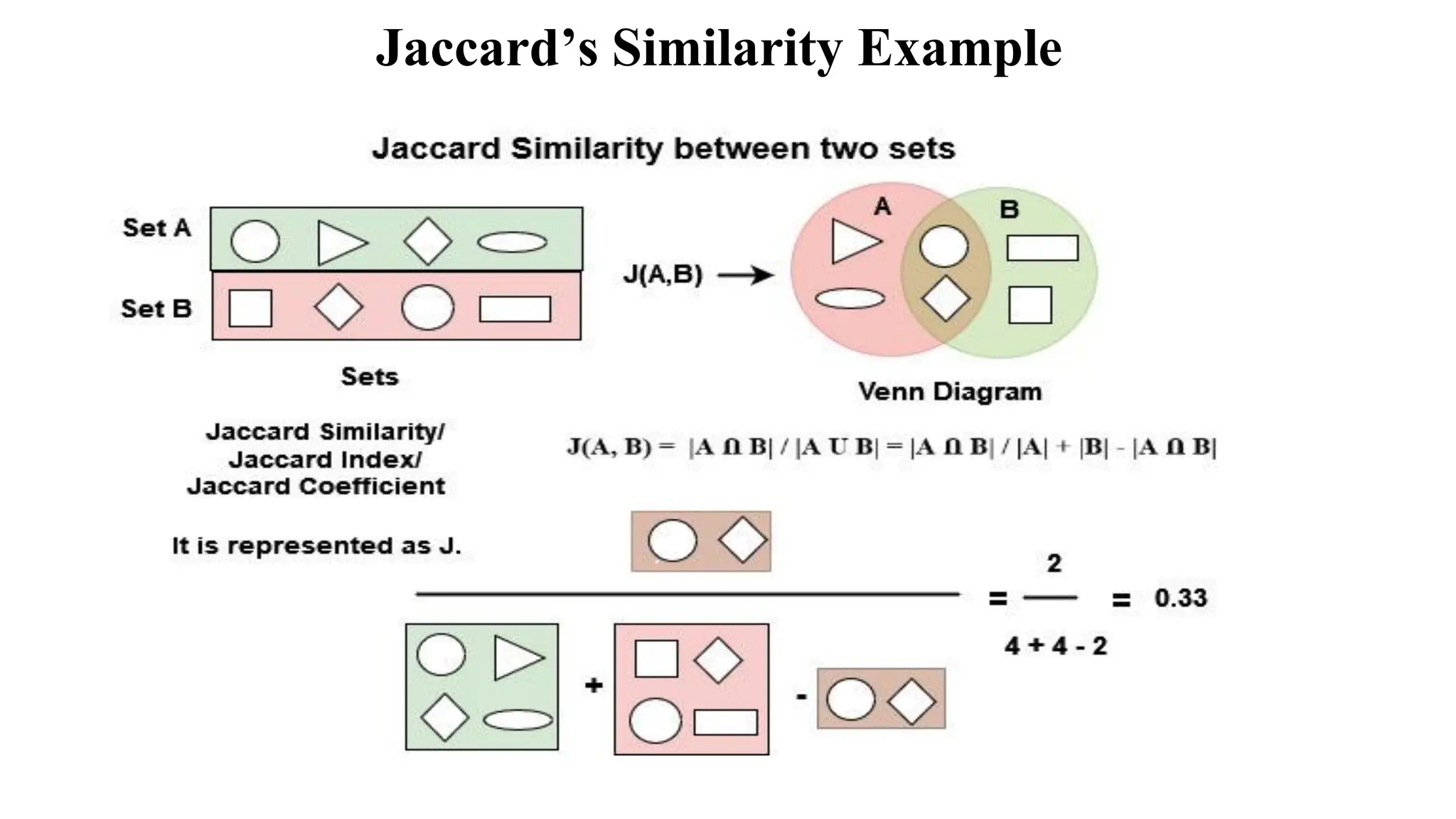
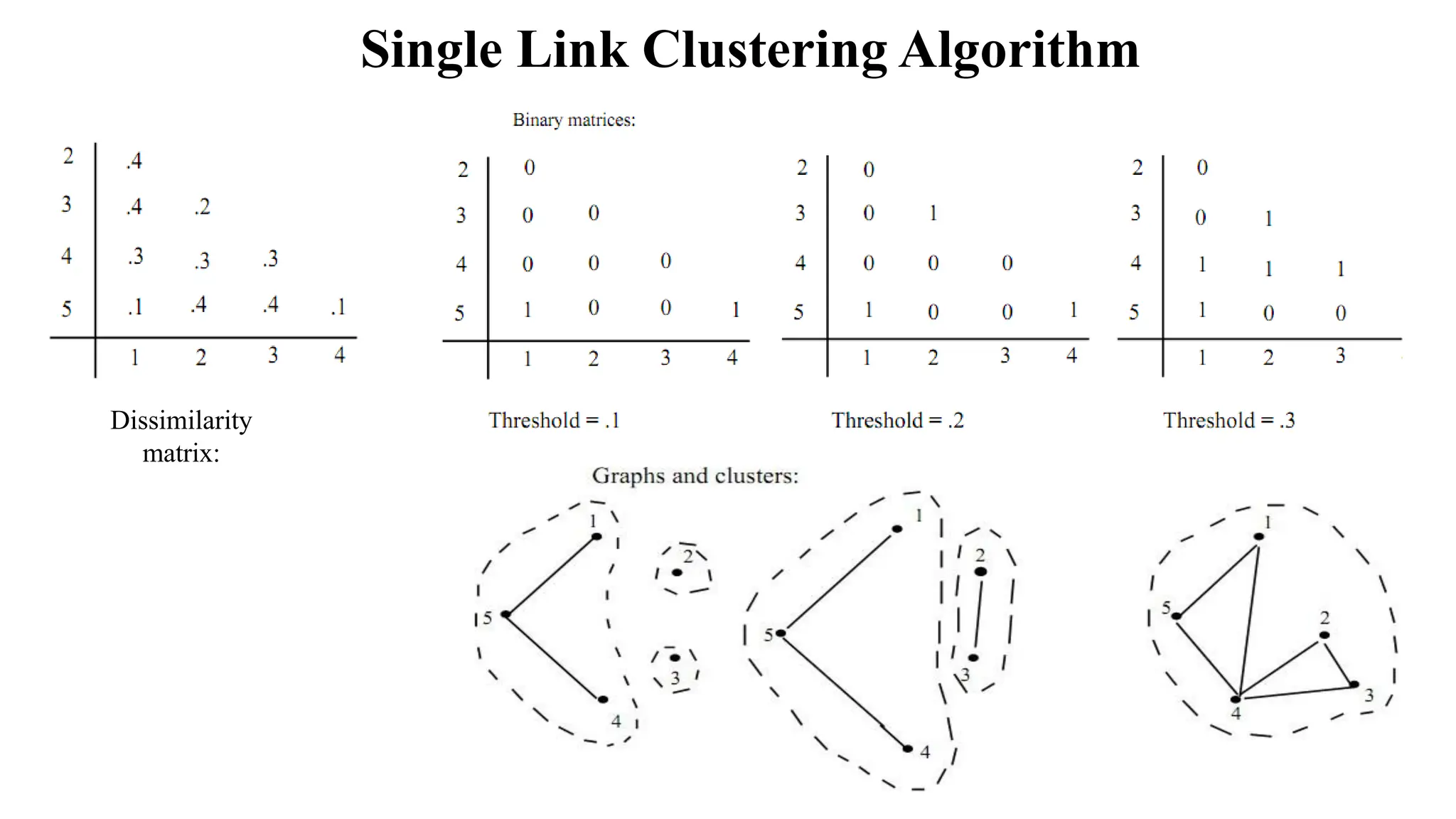
The document outlines the fundamentals of Information Retrieval (IR) including concepts, processes, and algorithms related to data and text mining. It distinguishes between data retrieval and information retrieval, detailing their operational differences, and presents various automatic text analysis techniques such as Luhn's ideas and clustering algorithms. Additionally, it covers evaluation criteria like recall and precision, along with frameworks for clustering in IR applications.











































![ICDIM 06 Web IR Tutorial [Compatibility Mode].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/icdim06webirtutorialcompatibilitymode-250307100423-5b1c7700-thumbnail.jpg?width=640&height=640&fit=bounds)




































