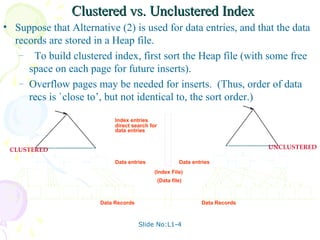
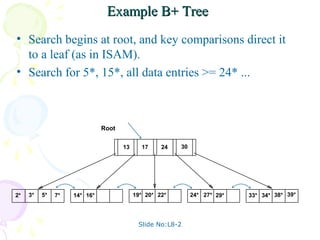
This document discusses database management systems and contains slides related to external data storage, file organization, indexing, and performance comparisons. Specifically, it provides information on different file organizations like heap files, sorted files, and indexed files. It also describes index structures like B+ trees and hash indexes. The slides provide comparisons of the cost of common operations like scans, searches, and updates between different file organization approaches.