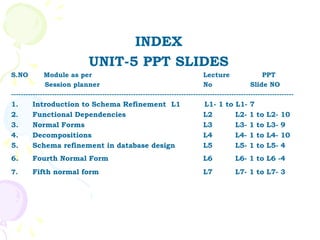
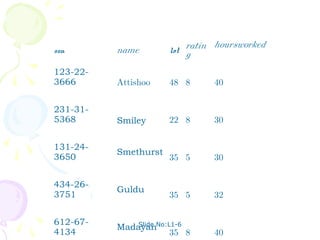
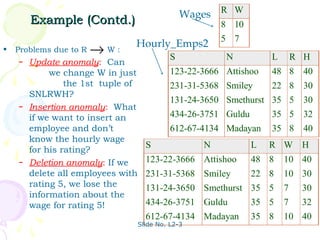
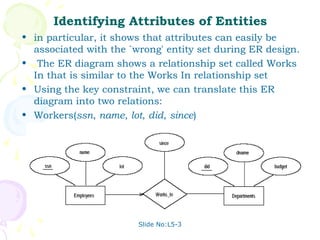
The document discusses database management systems and schema refinement. It provides examples of functional dependencies that can be identified from relationships between attributes in relations. Functional dependencies can be used to recognize redundancy and suggest decomposing relations to eliminate problems like update, insertion, and deletion anomalies. Reasoning about functional dependencies using Armstrong's axioms can help infer additional dependencies implied by a set of dependencies.