Download as PDF, PPTX


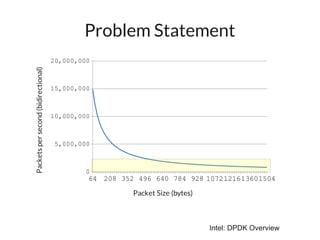
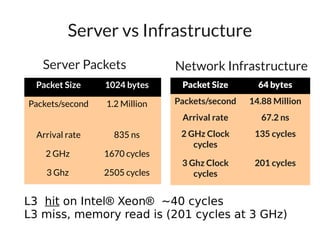
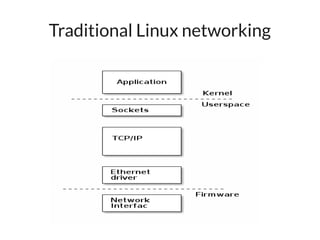
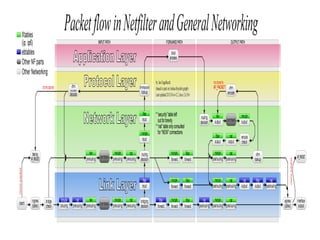
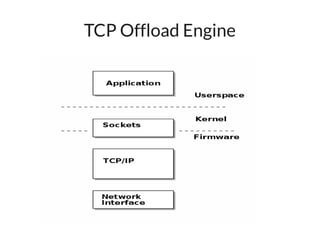


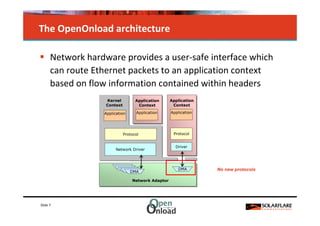
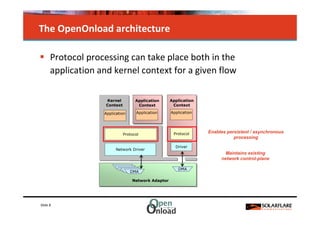
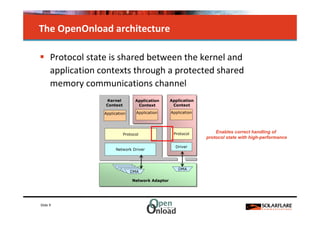

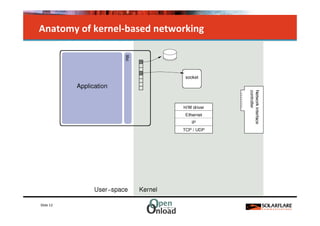
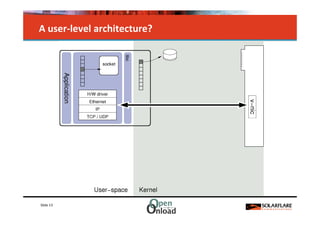
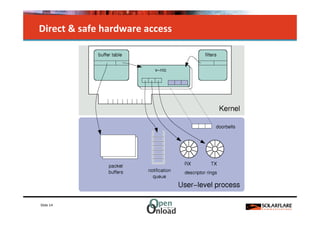


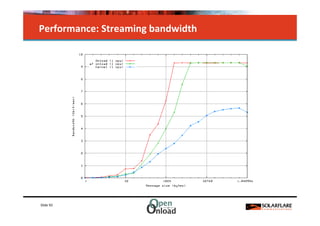


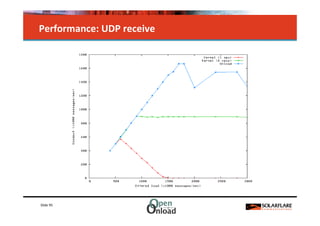


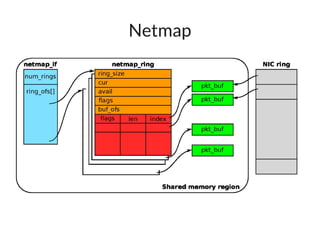



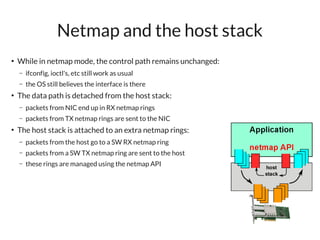
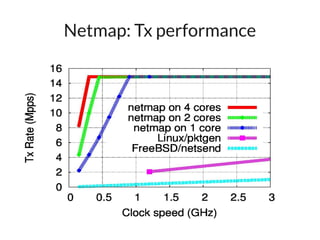
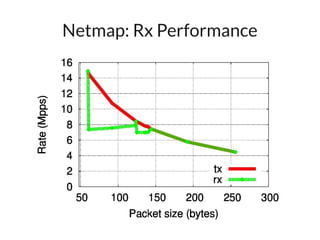

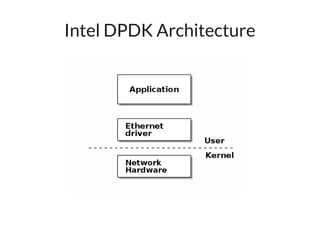

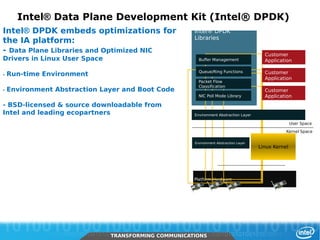

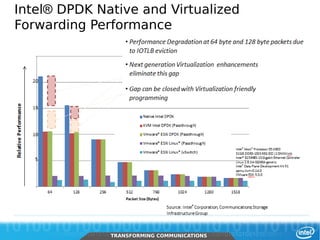
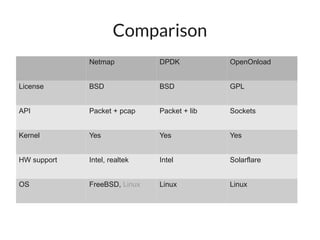





The document discusses networking in userspace, focusing on high-performance architectures like OpenOnload, Netmap, and DPDK, which enhance packet processing by enabling direct and efficient interaction with network hardware. It highlights performance metrics, scalability challenges, and the architectural differences between user-level and kernel-level networking. Additionally, it introduces various libraries and drivers associated with these architectures to optimize packet handling and throughput in different environments.



































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
