Downloaded 36 times











![1. Read Tweets from CSV
/**
* Read CSV file {@code f} and put its contents into {@link #rows},
* {@link #texts}, and {@link #origTexts}.
* @param f
*/
public void readCsv(File f) {
try (final CSVReader csv = new CSVReader(new FileReader(f))) {
headerNames = csv.readNext(); // header
rows = csv.readAll();
texts = rows.stream().map(it -> Maps.immutableEntry(it[0], it[1]))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
origTexts = ImmutableMap.copyOf(texts);
} catch (Exception e) {
throw new RuntimeException("Cannot read " + f, e);
}
}](https://image.slidesharecdn.com/23214344-hendyirawan-twitterauthorpredictionfromtweetsusingbayesiannetwork-150511044025-lva1-app6891/75/Twitter-Author-Prediction-from-Tweets-using-Bayesian-Network-16-2048.jpg)


![4. Remove Punctuation Symbols
/**
* Remove punctuation symbols from texts.
*/
public void removePunctuation() {
texts = Maps.transformValues(texts, it -> it.replaceAll("[^a-zA-Z0-9]+", " "));
}](https://image.slidesharecdn.com/23214344-hendyirawan-twitterauthorpredictionfromtweetsusingbayesiannetwork-150511044025-lva1-app6891/75/Twitter-Author-Prediction-from-Tweets-using-Bayesian-Network-19-2048.jpg)
![5. Remove Numbers
/**
* Remove numbers from texts.
*/
public void removeNumbers() {
texts = Maps.transformValues(texts, it -> it.replaceAll("[0-9]+", ""));
}](https://image.slidesharecdn.com/23214344-hendyirawan-twitterauthorpredictionfromtweetsusingbayesiannetwork-150511044025-lva1-app6891/75/Twitter-Author-Prediction-from-Tweets-using-Bayesian-Network-20-2048.jpg)



![Train Bayesian Network: Java (1)
/**
* Creates a {@link SentimentAnalyzer} then analyzes the
file {@code f},
* with limiting words to {@code wordLimit} (based on top
word frequency),
* and additional stop words of {@code moreStopWords}
(base stop words
* are {@link SentimentAnalyzer#STOP_WORDS_ID}.
* @param f
* @param wordLimit
* @param moreStopWords
* @return
*/
protected SentimentAnalyzer analyze(File f, int wordLimit,
Set<String> moreStopWords) {
final SentimentAnalyzer sentimentAnalyzer = new
SentimentAnalyzer();
sentimentAnalyzer.readCsv(f);
sentimentAnalyzer.lowerCaseAll();
sentimentAnalyzer.removeLinks();
sentimentAnalyzer.removePunctuation();
sentimentAnalyzer.removeNumbers();
sentimentAnalyzer.canonicalizeWords();
sentimentAnalyzer.removeStopWords(moreStopWords.toArray(ne
w String[] {}));
log.info("Preprocessed text: {}",
sentimentAnalyzer.texts.entrySet().stream().limit(10)
.collect(Collectors.toMap(Map.Entry::getKey,
Map.Entry::getValue)));
sentimentAnalyzer.splitWords();
log.info("Words: {}",
sentimentAnalyzer.words.entrySet().stream().limit(10)
.collect(Collectors.toMap(Map.Entry::getKey,
Map.Entry::getValue)));
final ImmutableMultiset<String> wordMultiset =
Multisets.copyHighestCountFirst(HashMultiset.create(
sentimentAnalyzer.words.values().stream().flatMap(it
-> it.stream()).collect(Collectors.toList())) );
final Map<String, Integer> wordCounts = new
LinkedHashMap<>();
// only the N most used words
wordMultiset.elementSet().stream().limit(wordLimit).
forEach( it -> wordCounts.put(it,
wordMultiset.count(it)) );
log.info("Word counts (orig): {}", wordCounts);
// Normalize the twitterUser "vector" to length
1.0
// Note that this "vector" is actually user-
specific, i.e. it's not a user-independent vector
long origSumSqrs = 0;
for (final Integer it : wordCounts.values()) {
origSumSqrs += it * it;
}
double origLength = Math.sqrt(origSumSqrs);
final Map<String, Double> normWordCounts =
Maps.transformValues(wordCounts, it -> it /
origLength);
log.info("Word counts (normalized): {}",
normWordCounts);
sentimentAnalyzer.normWordCounts =
normWordCounts;
return sentimentAnalyzer;
}](https://image.slidesharecdn.com/23214344-hendyirawan-twitterauthorpredictionfromtweetsusingbayesiannetwork-150511044025-lva1-app6891/75/Twitter-Author-Prediction-from-Tweets-using-Bayesian-Network-25-2048.jpg)

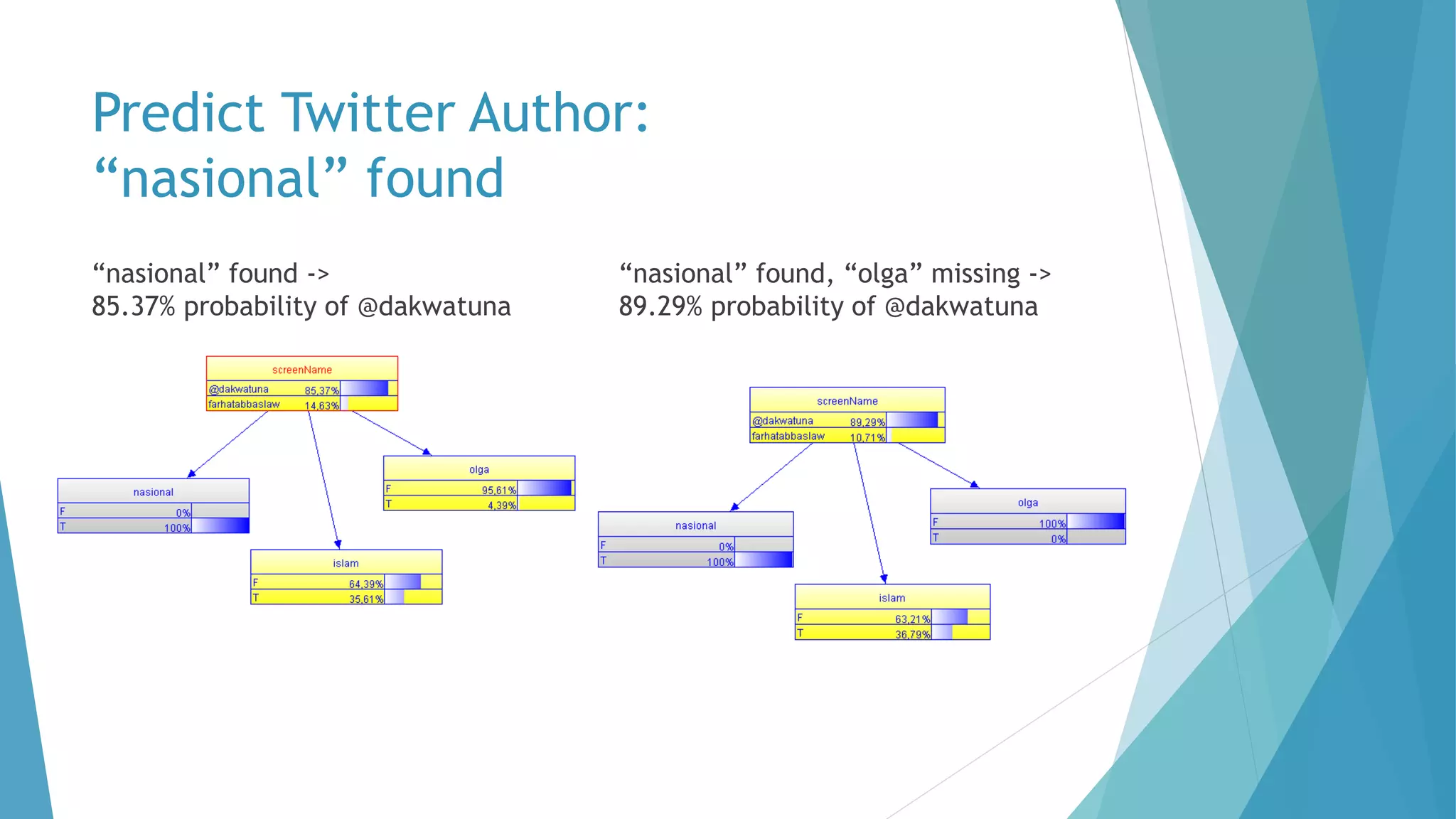
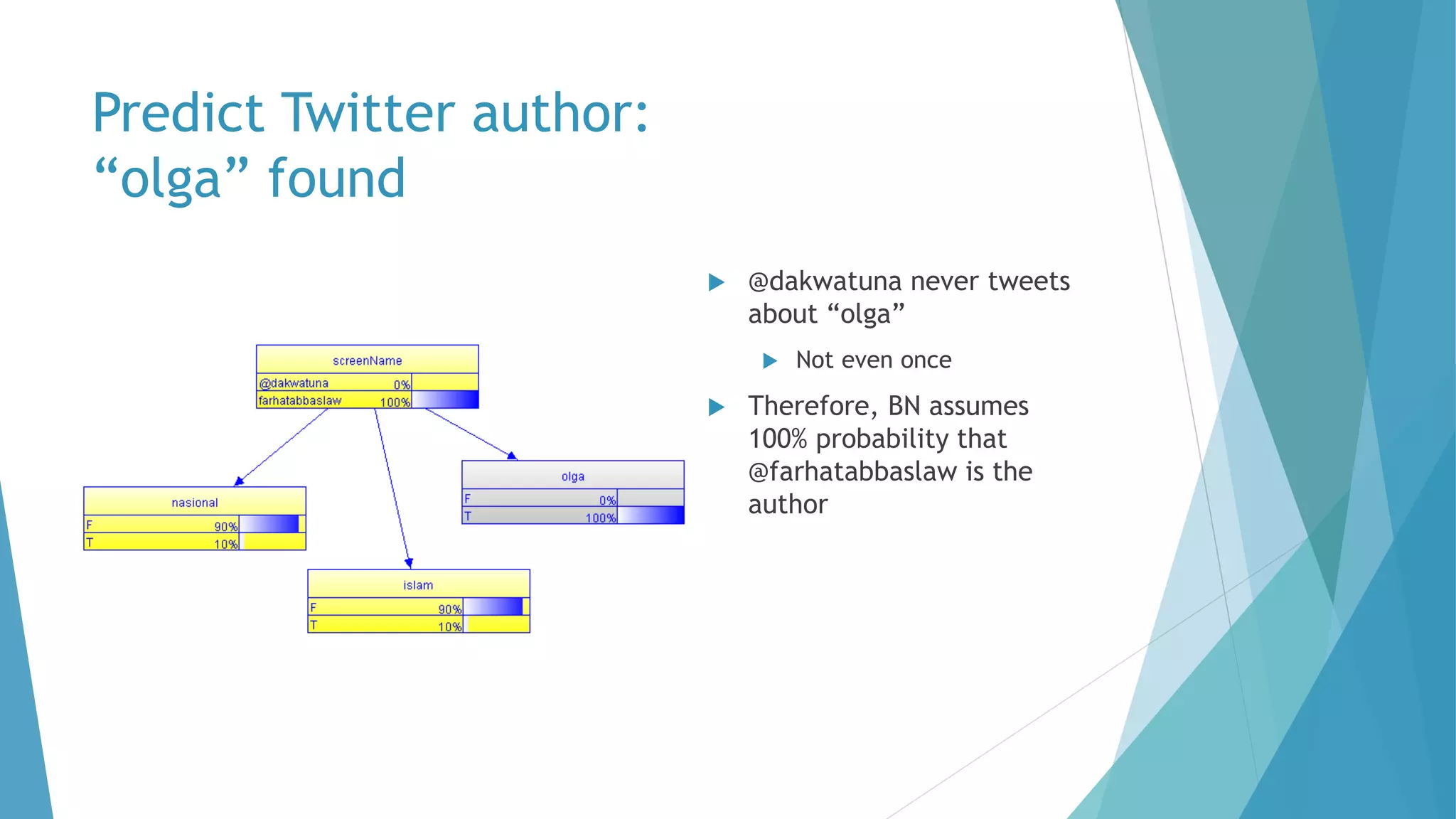
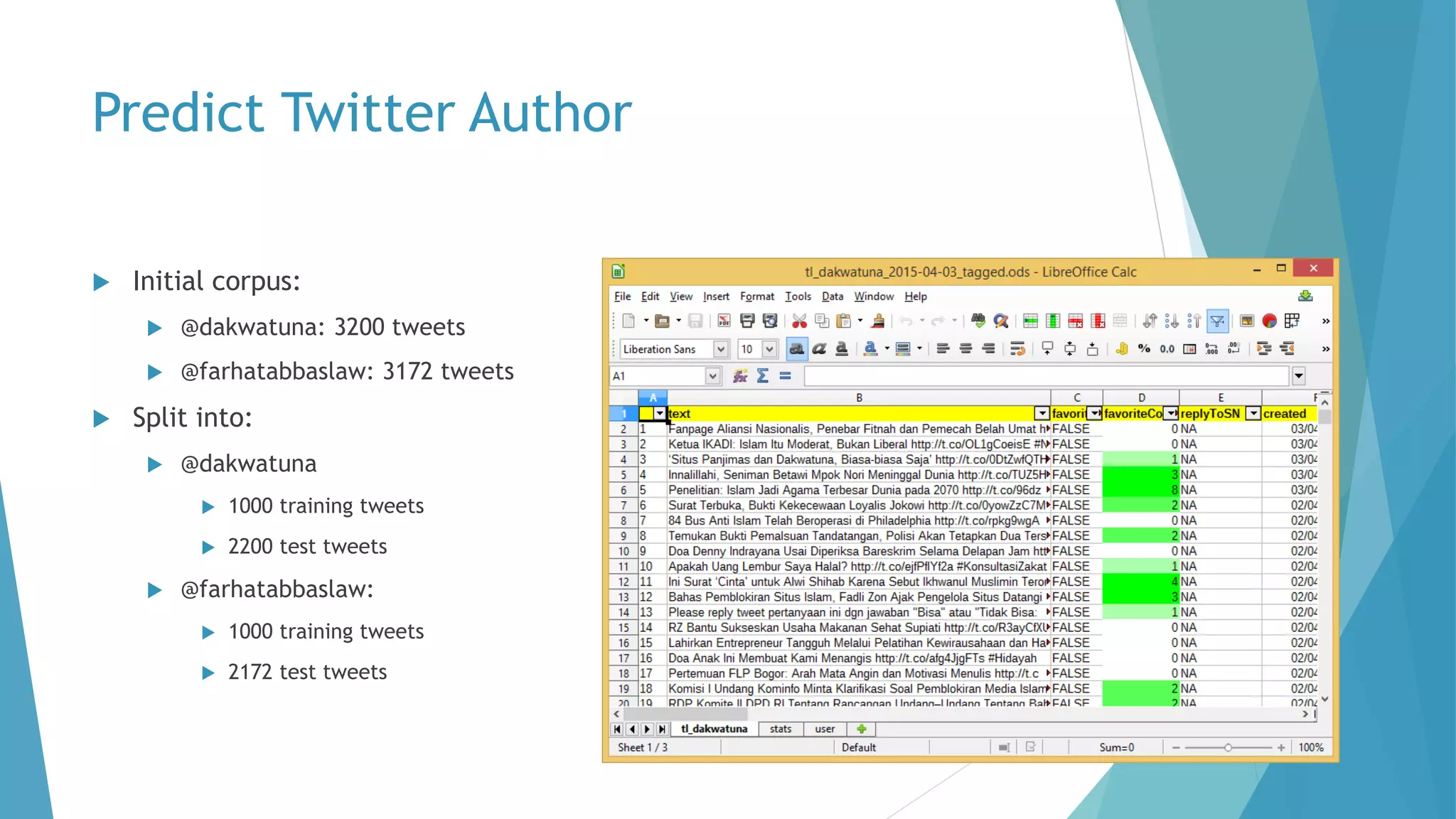




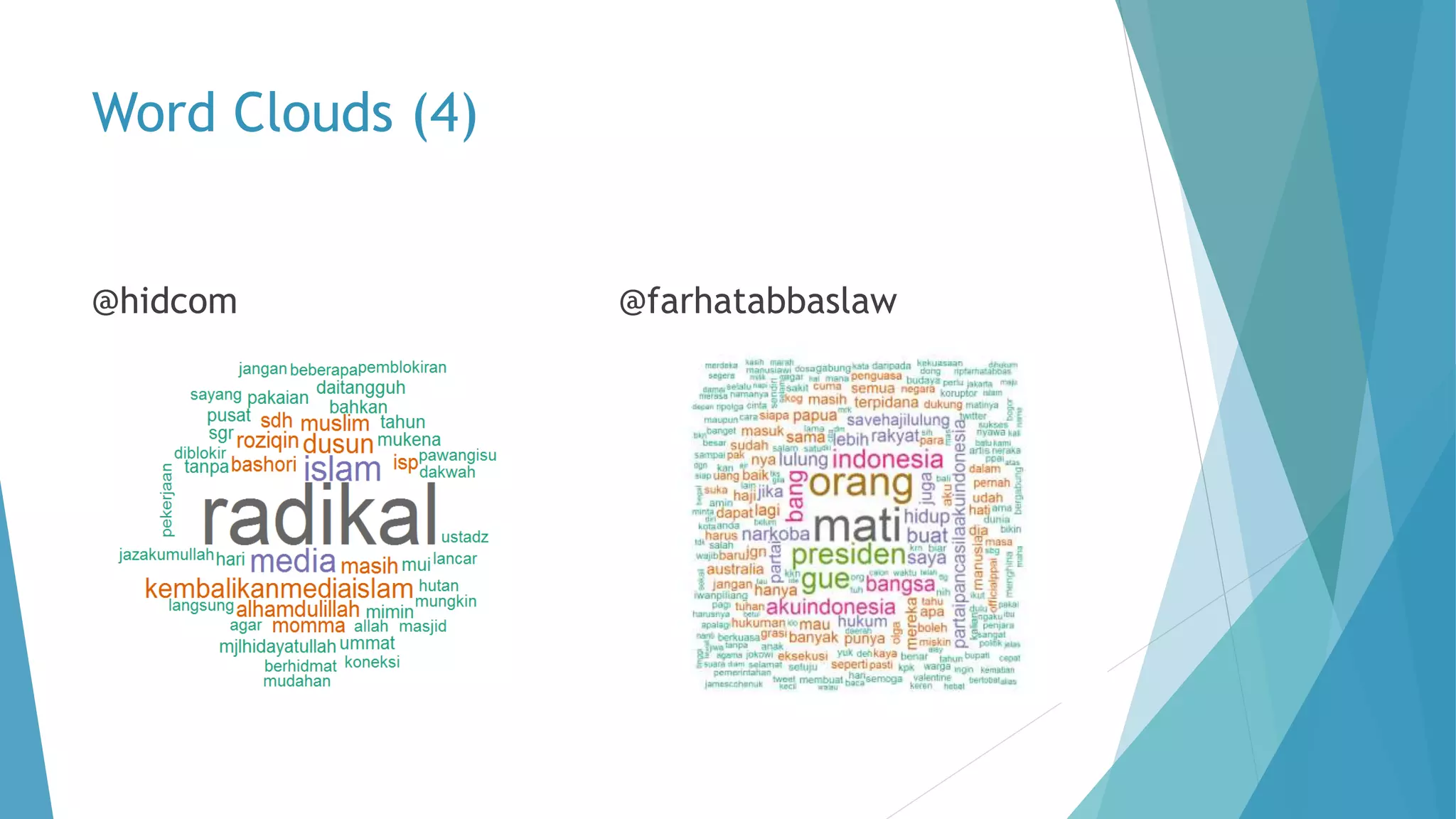
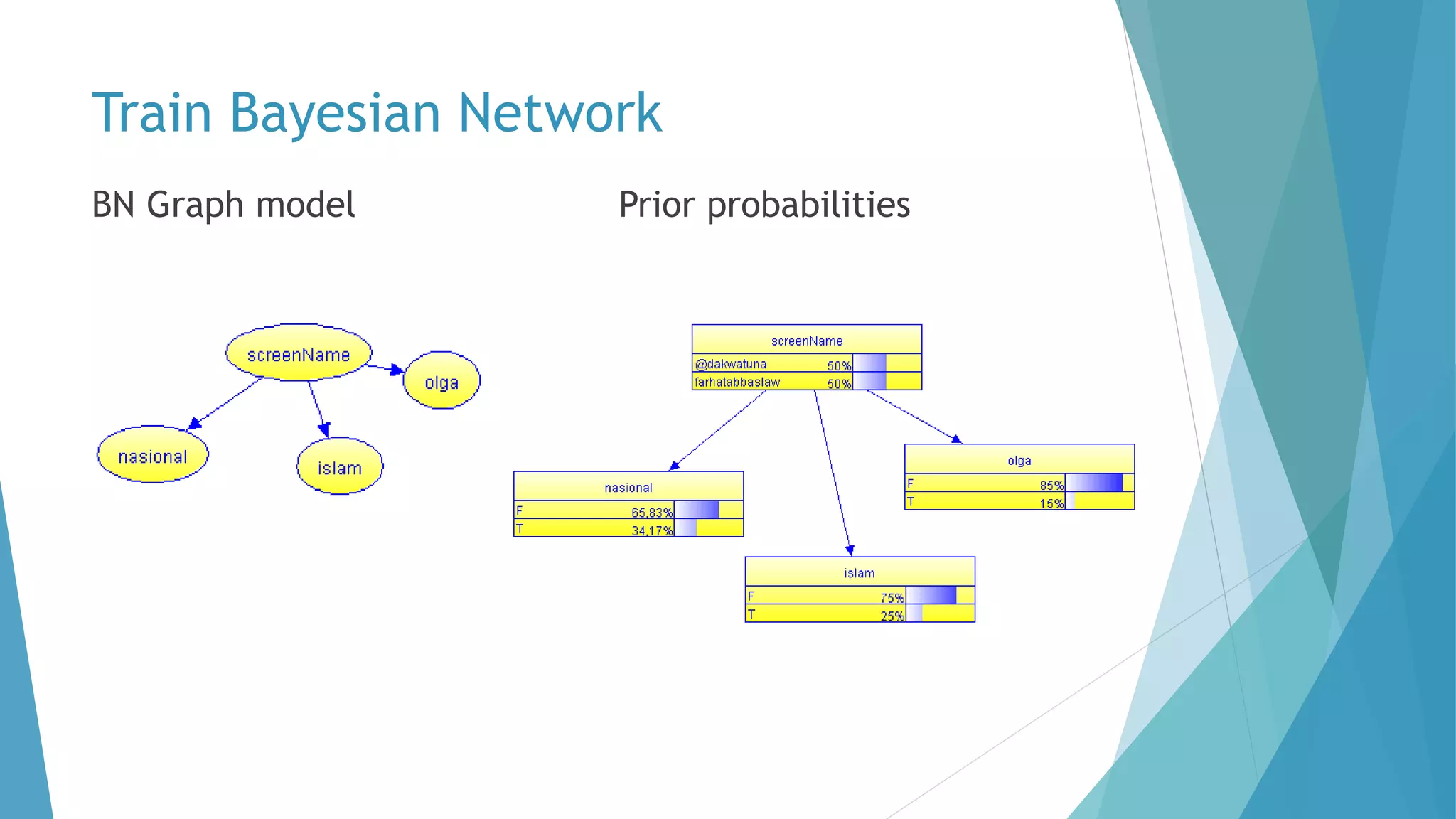
The document discusses a method for predicting Twitter authors based on their tweet content using a Bayesian network. It outlines the process of training the network using specific preprocessing techniques and the implementation details in R and Java, achieving high accuracy in author prediction. Initial results indicate that writing styles, topics, and word distributions are significant factors influencing prediction accuracy.































































































