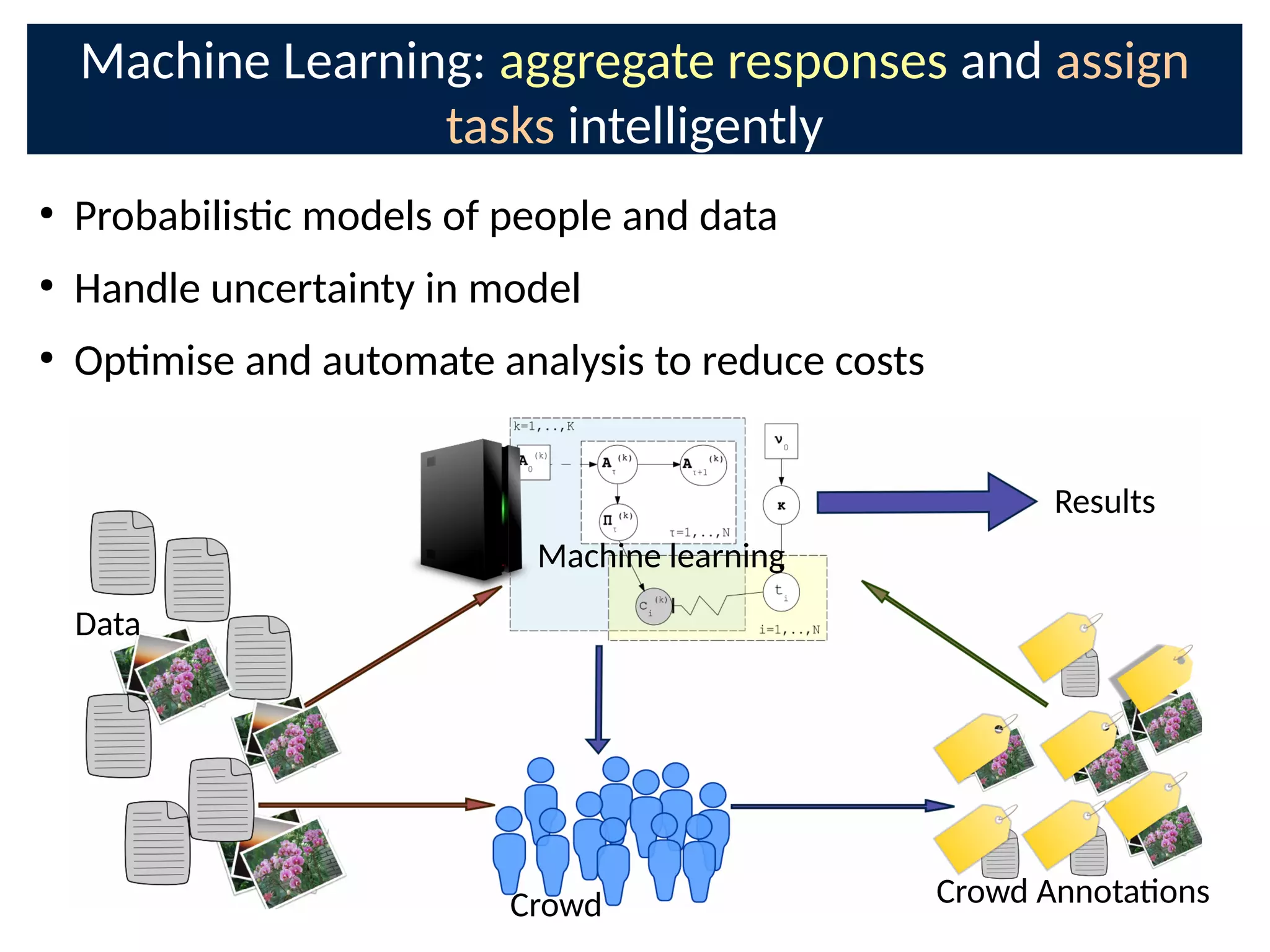
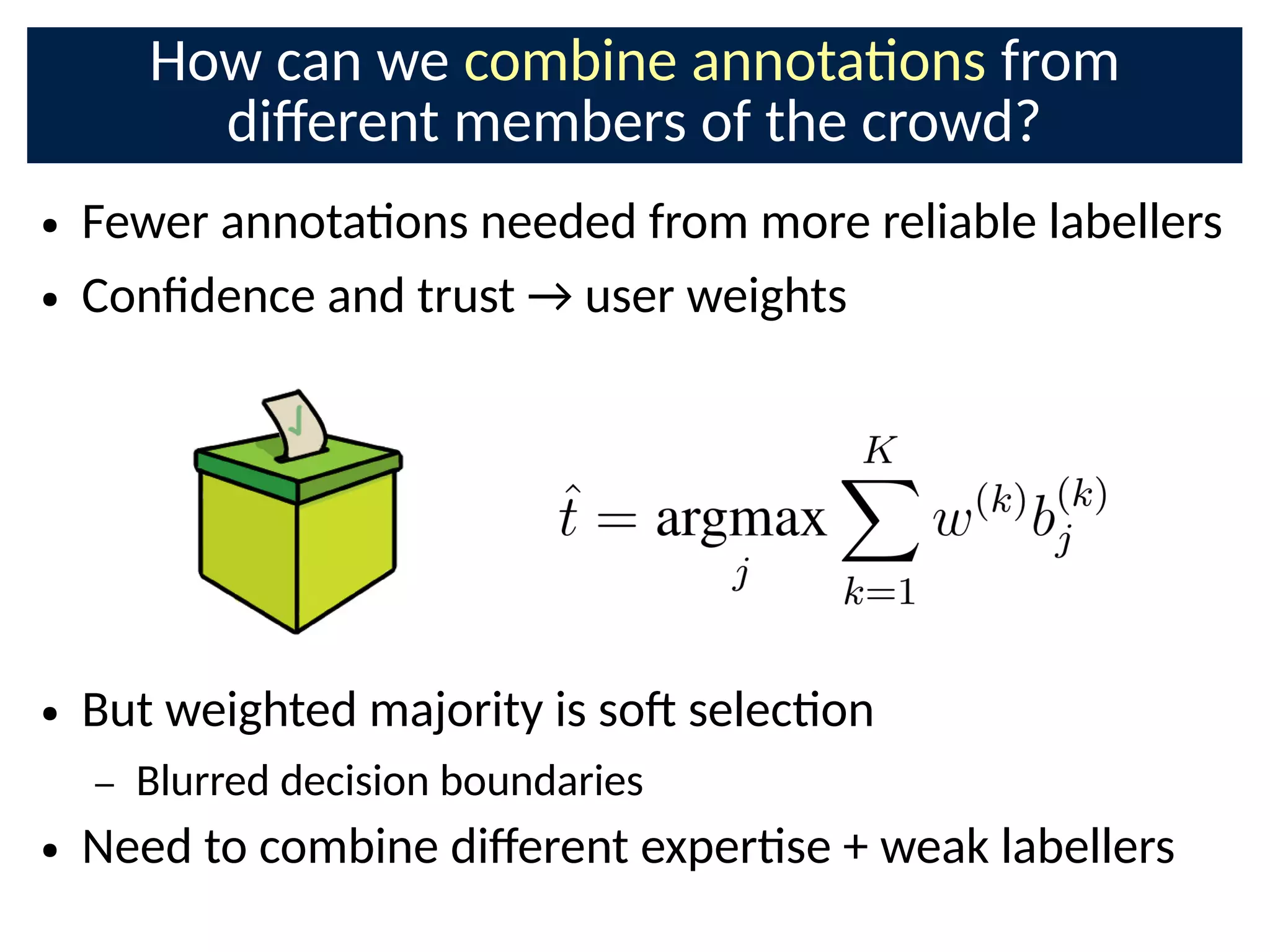
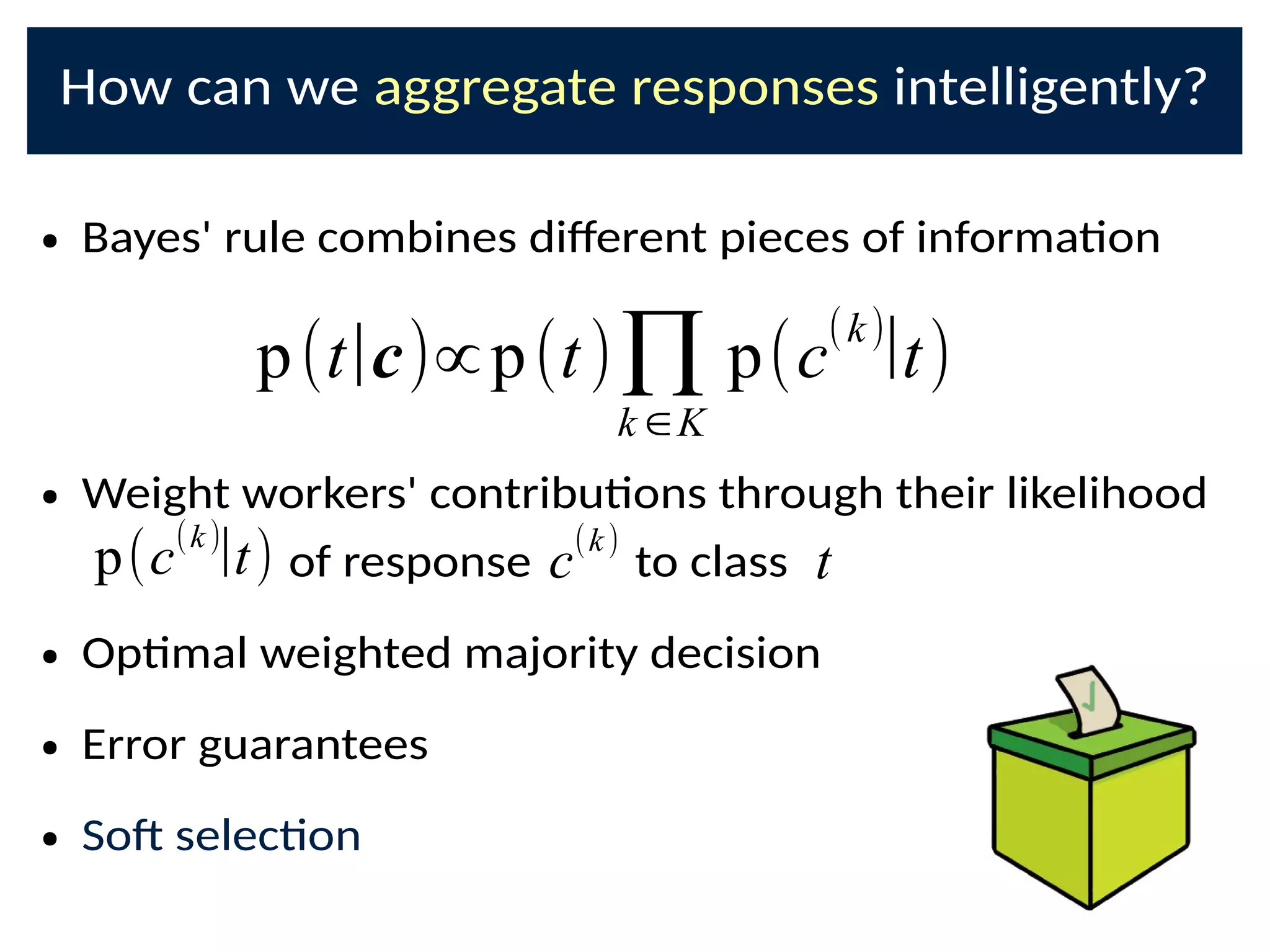
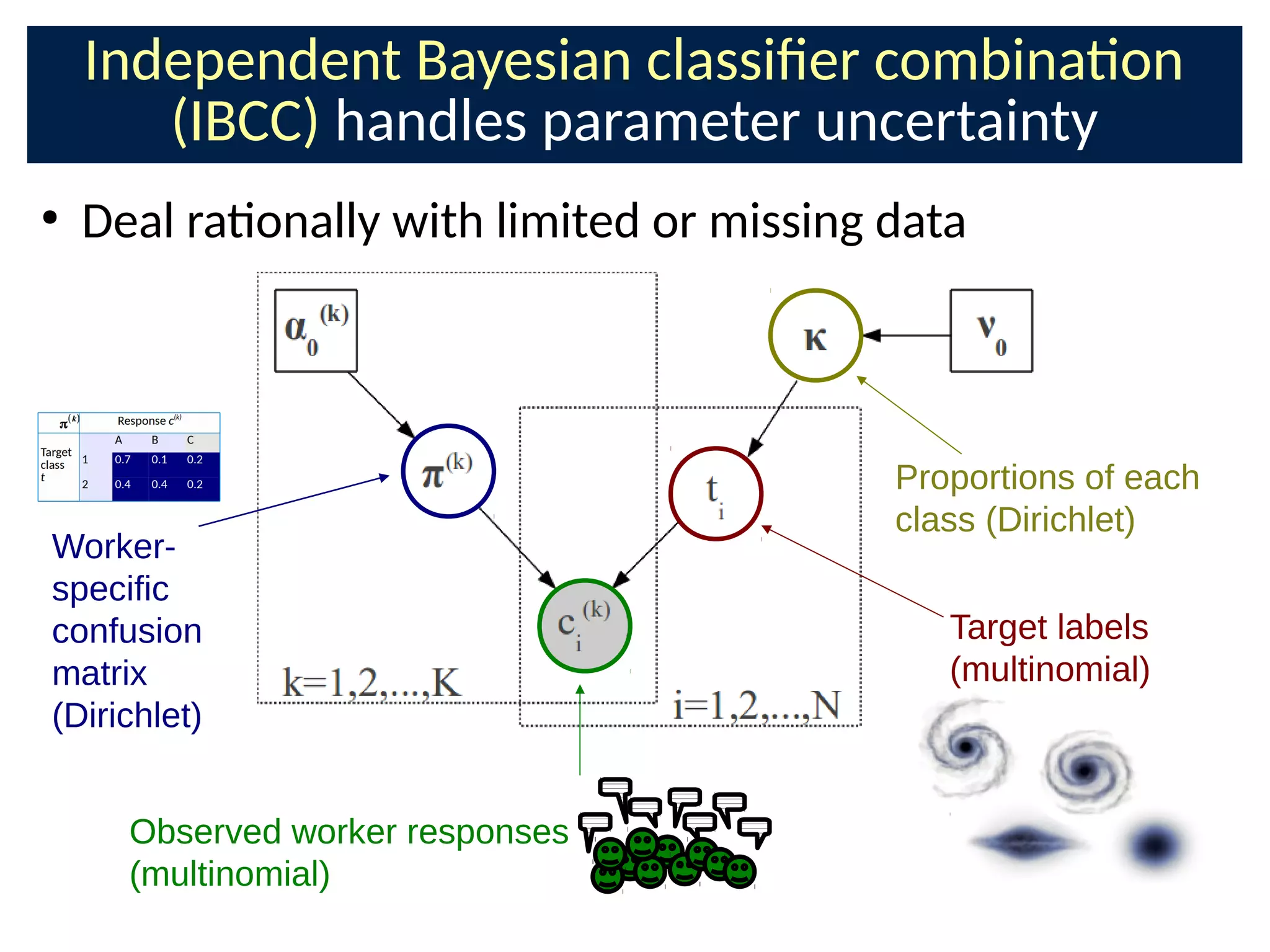
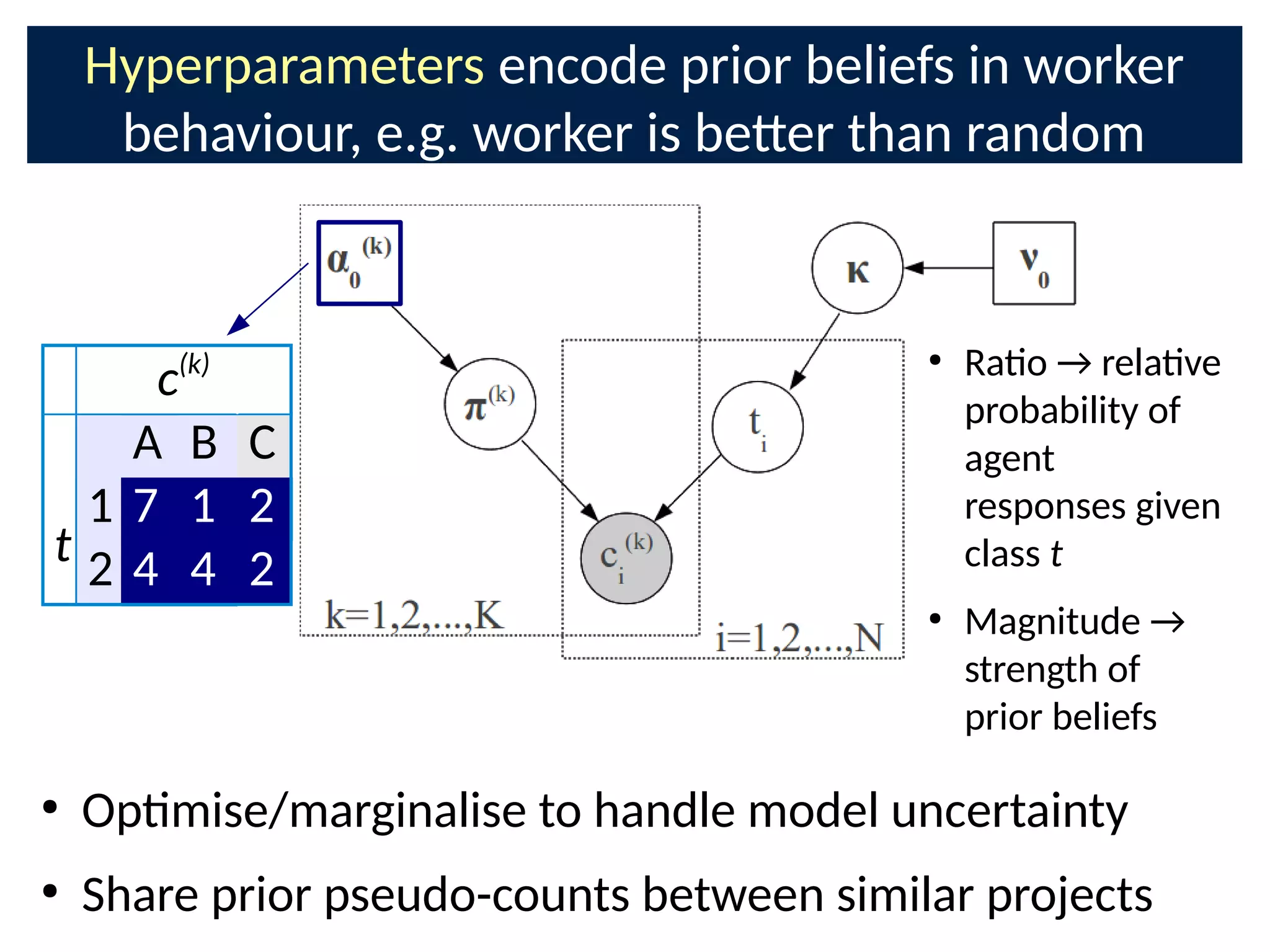
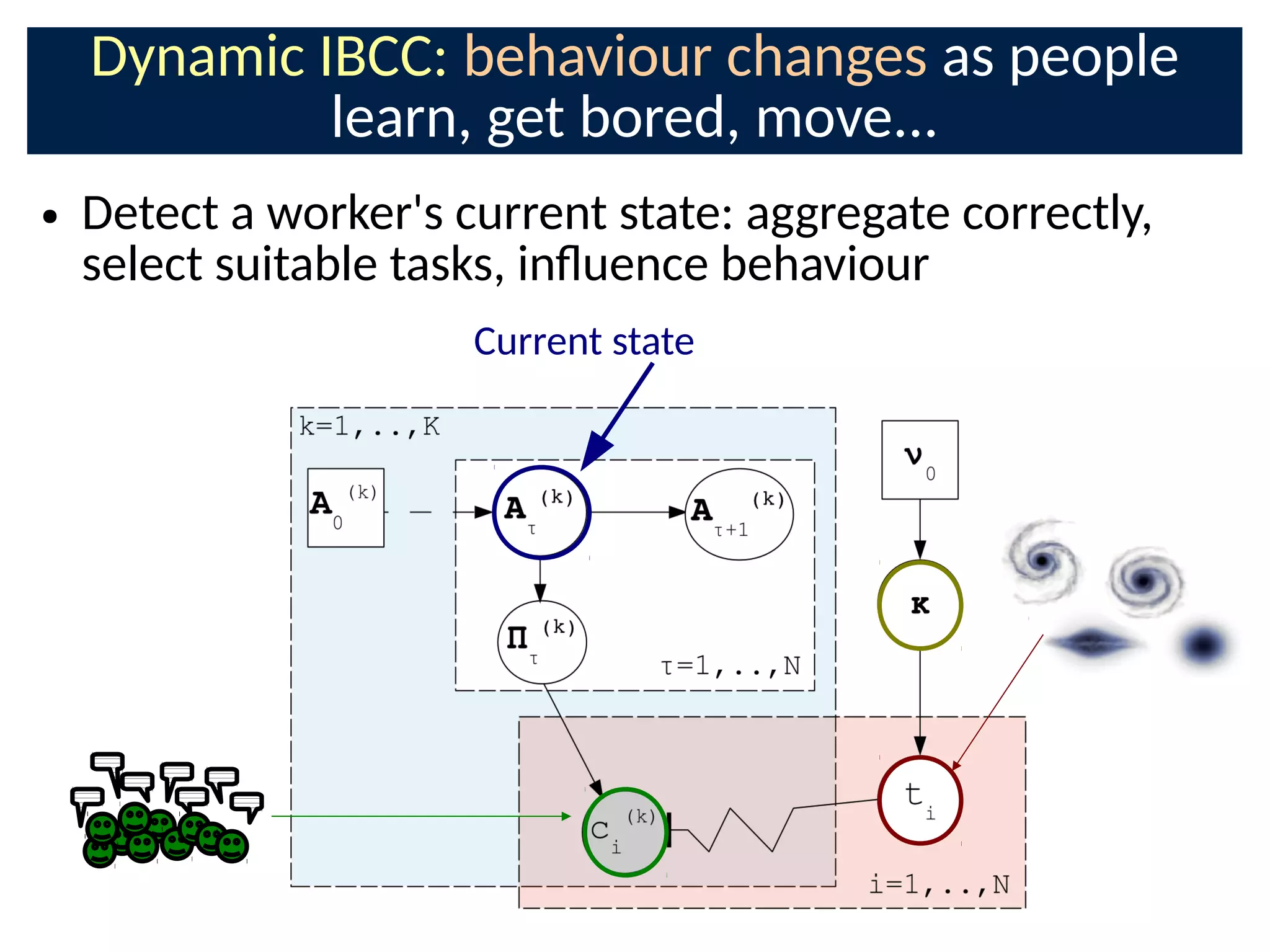
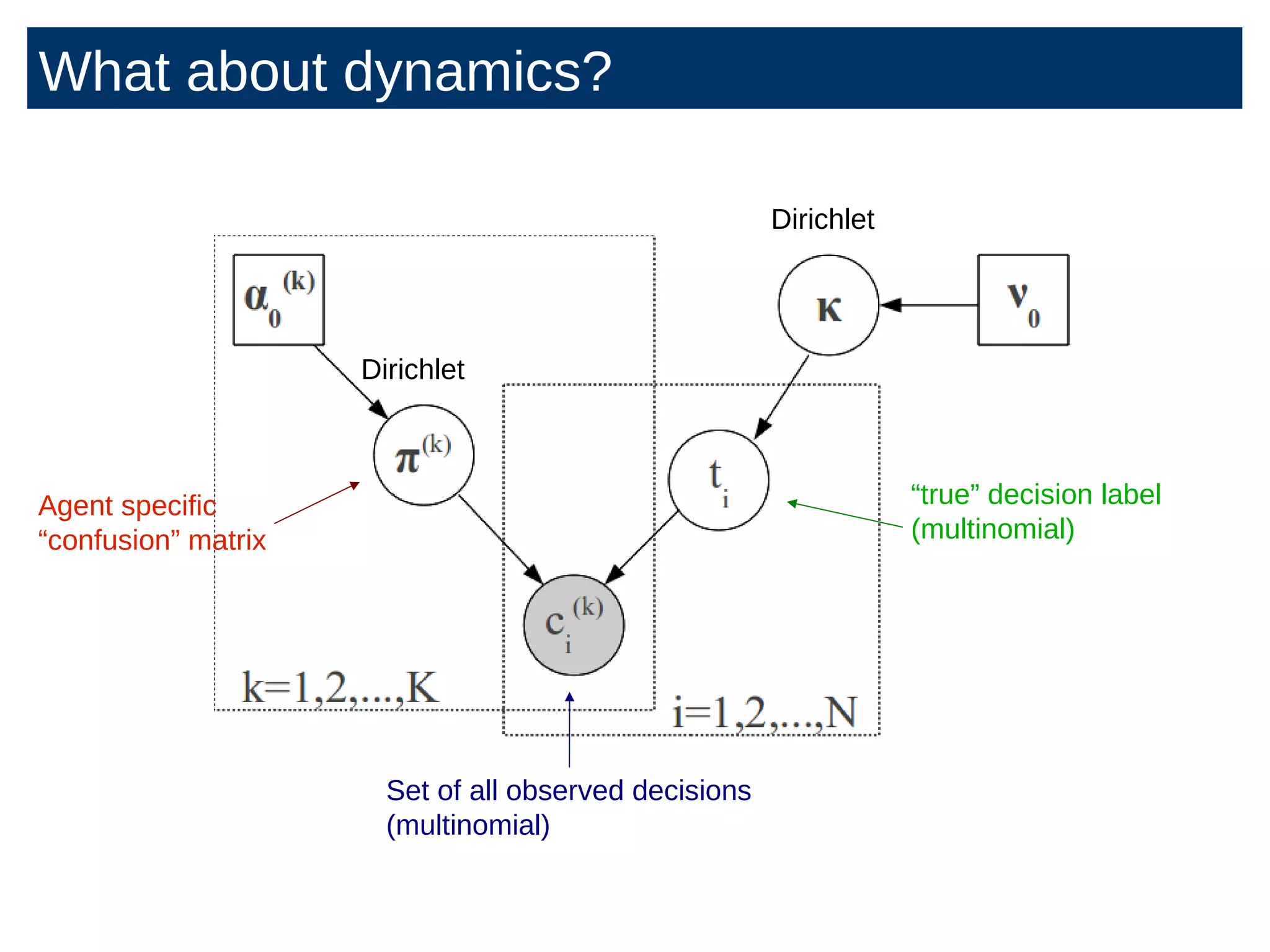
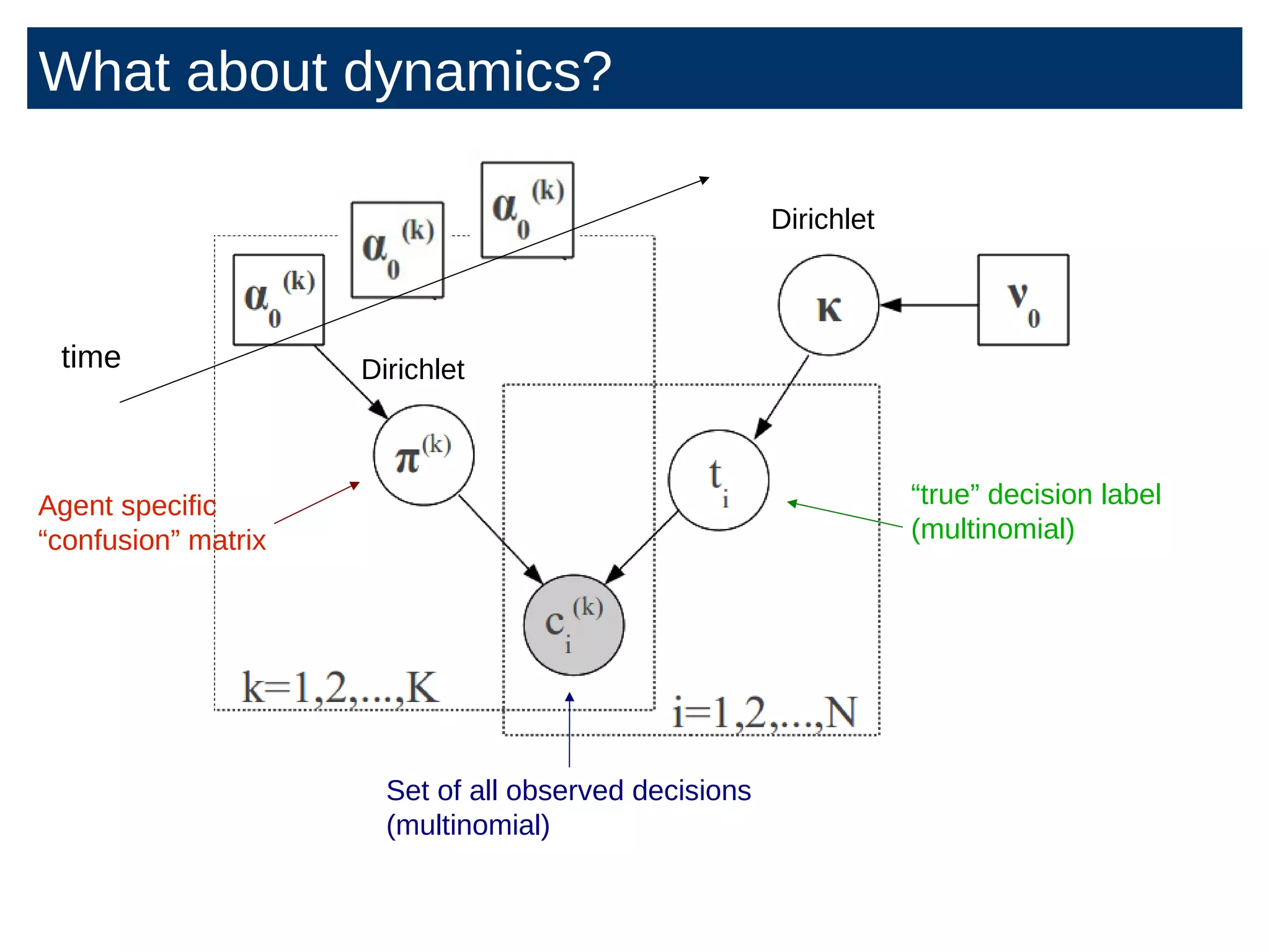
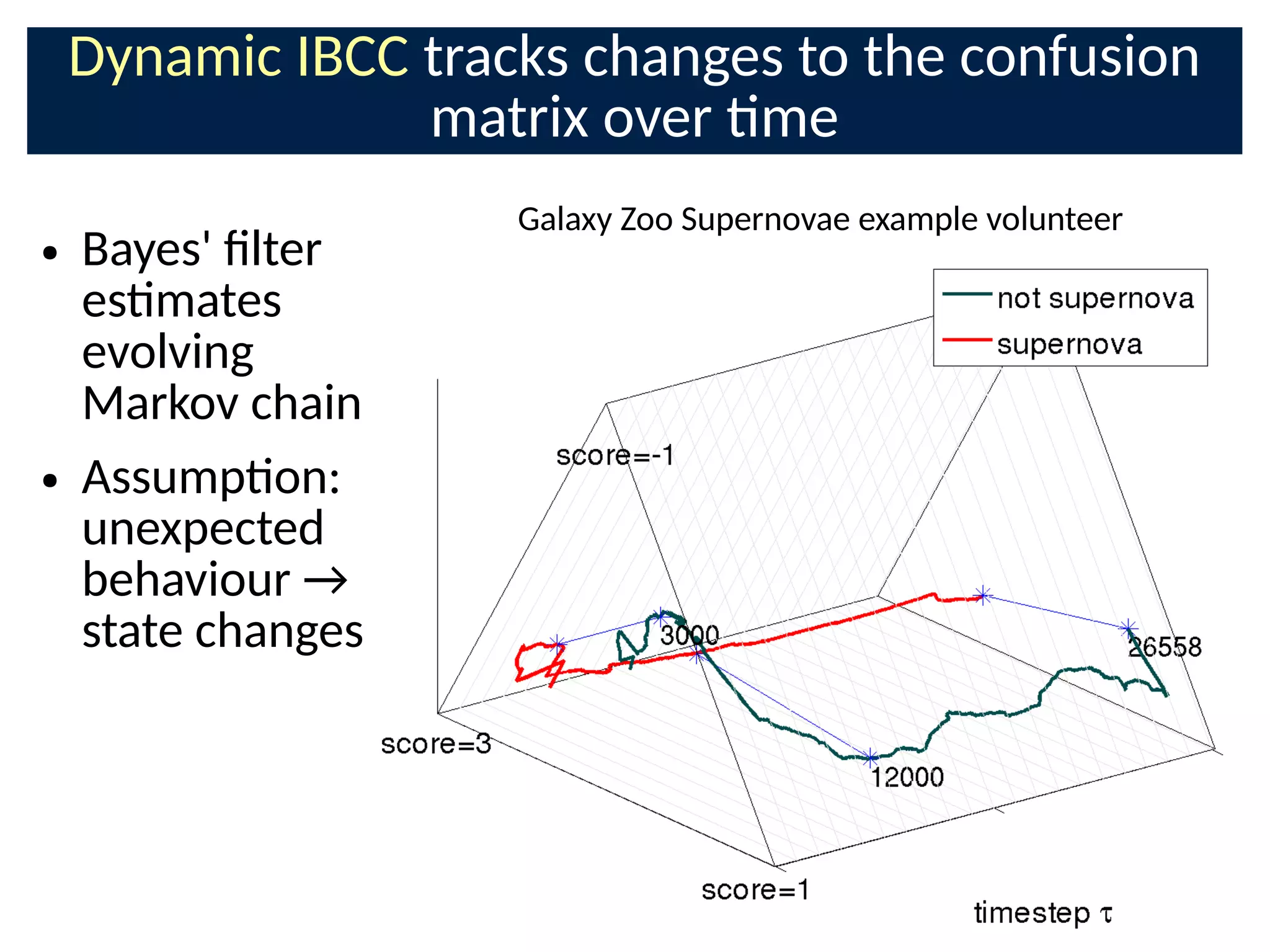
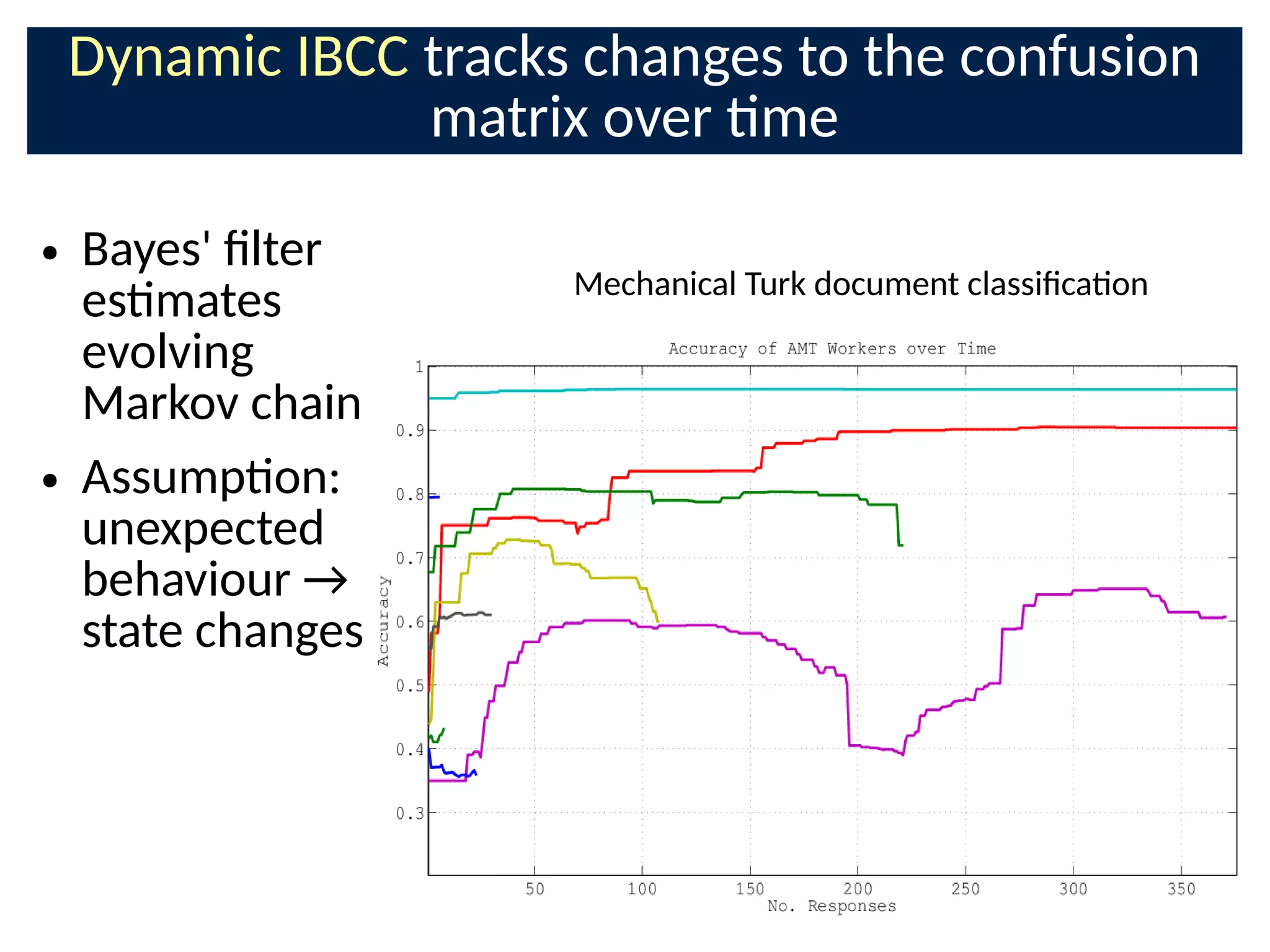
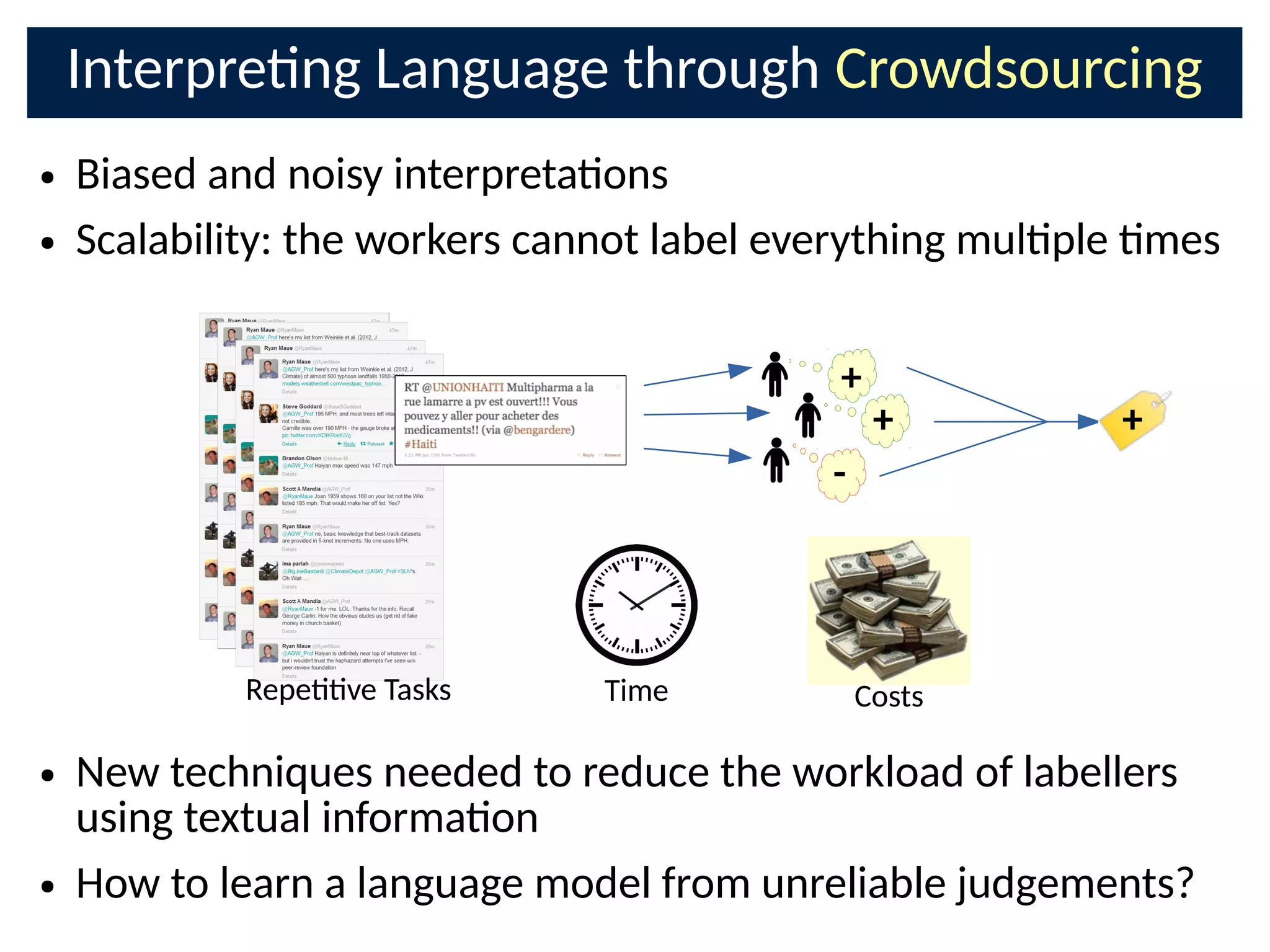
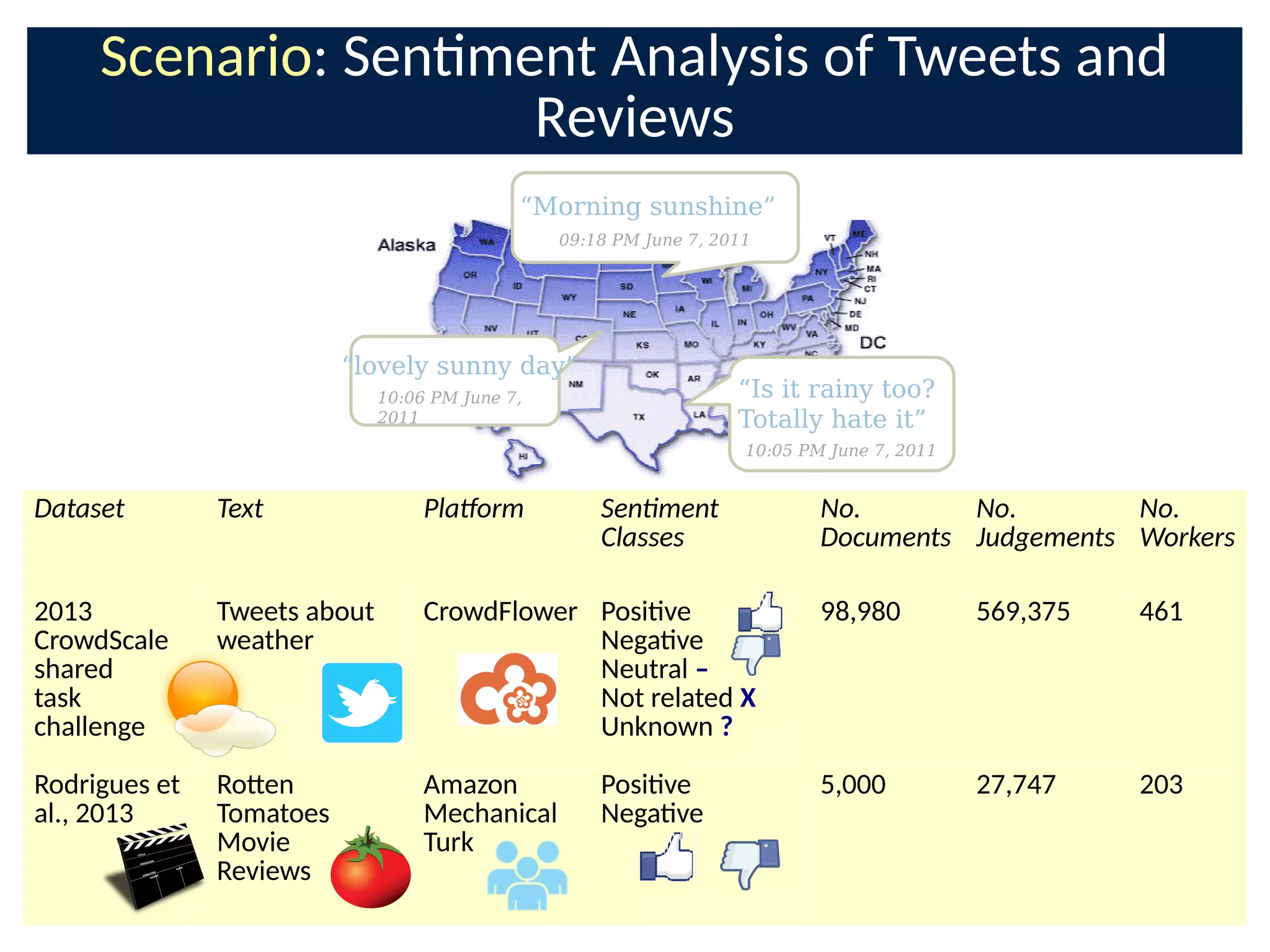
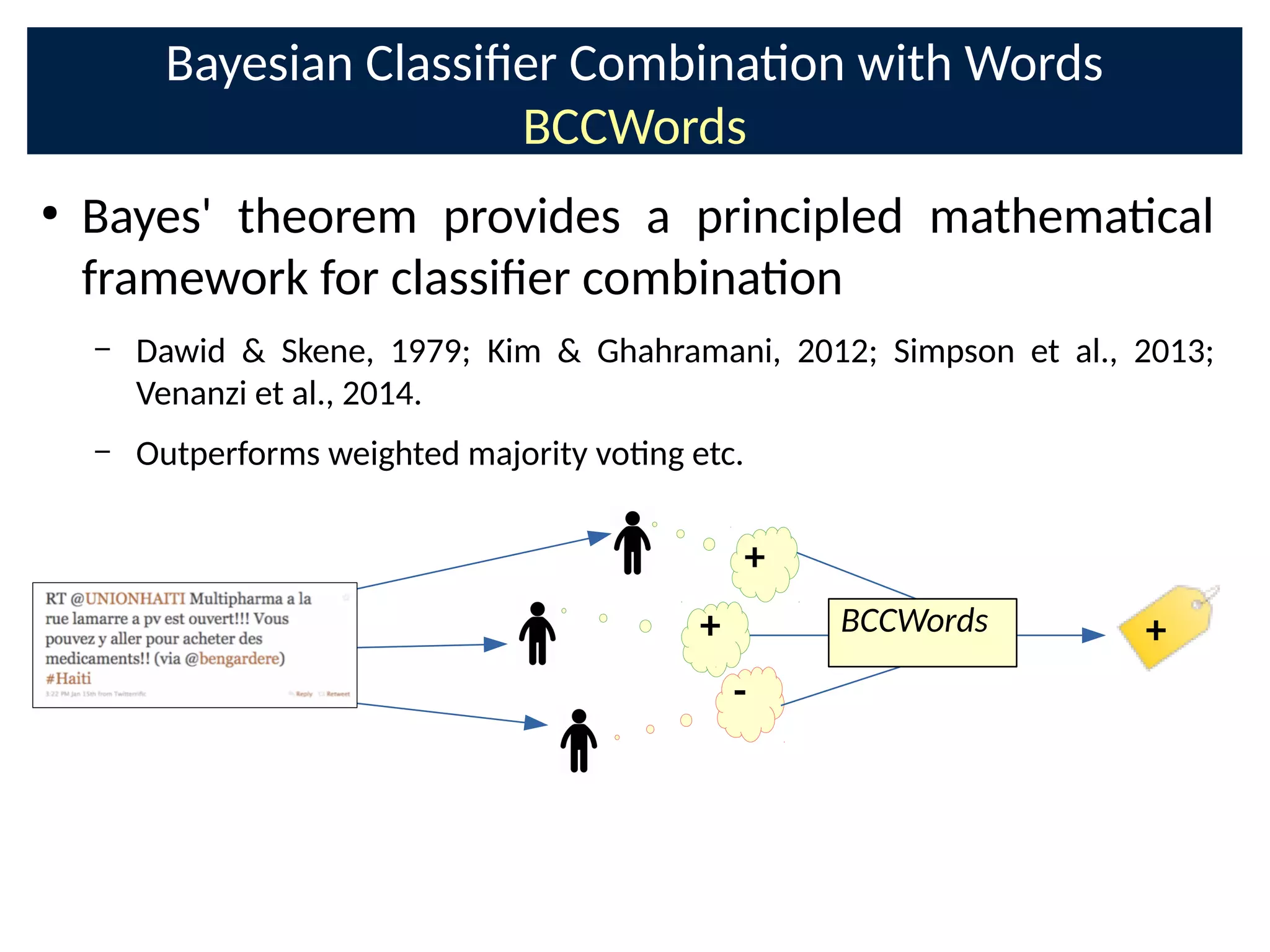
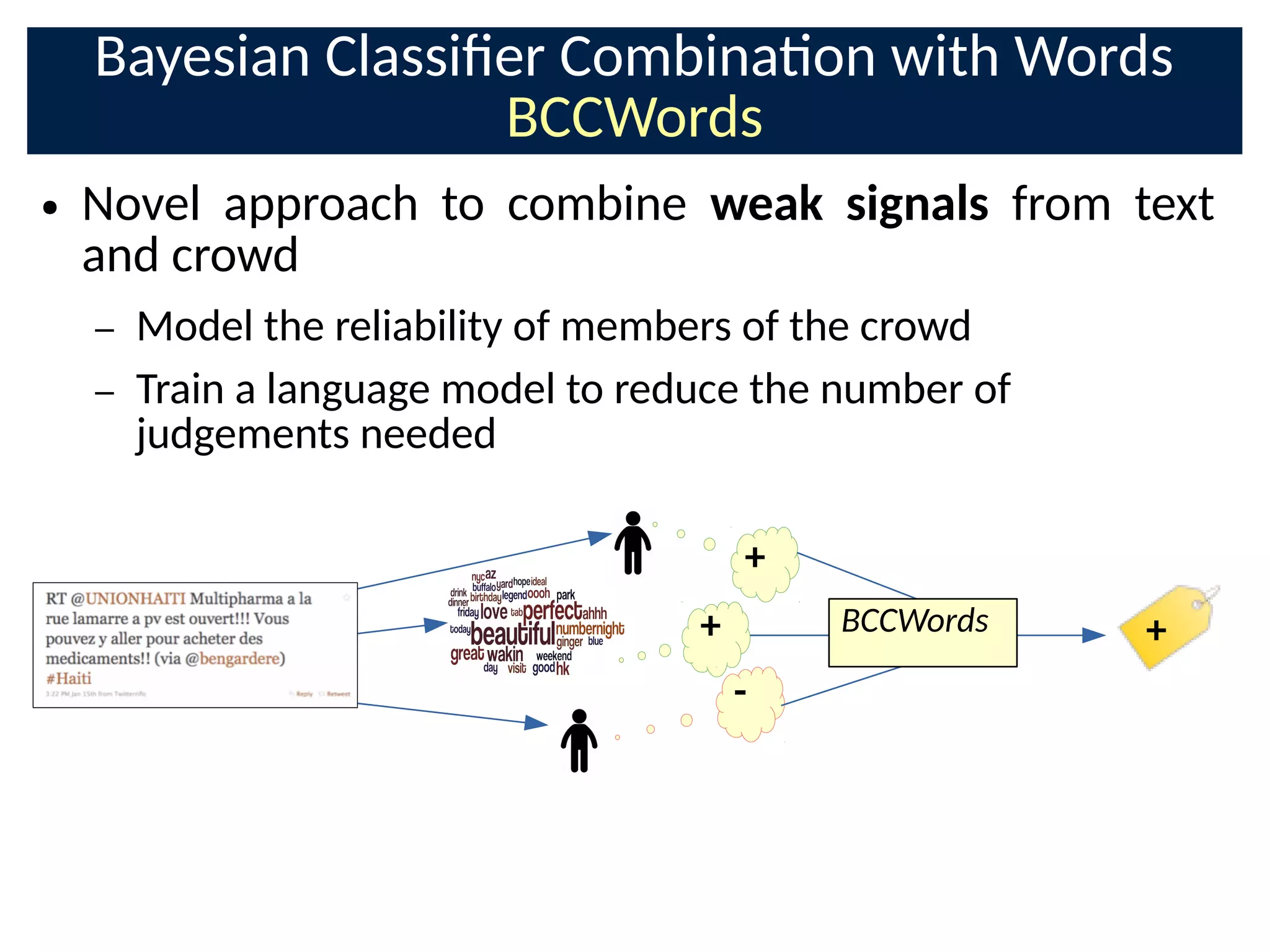
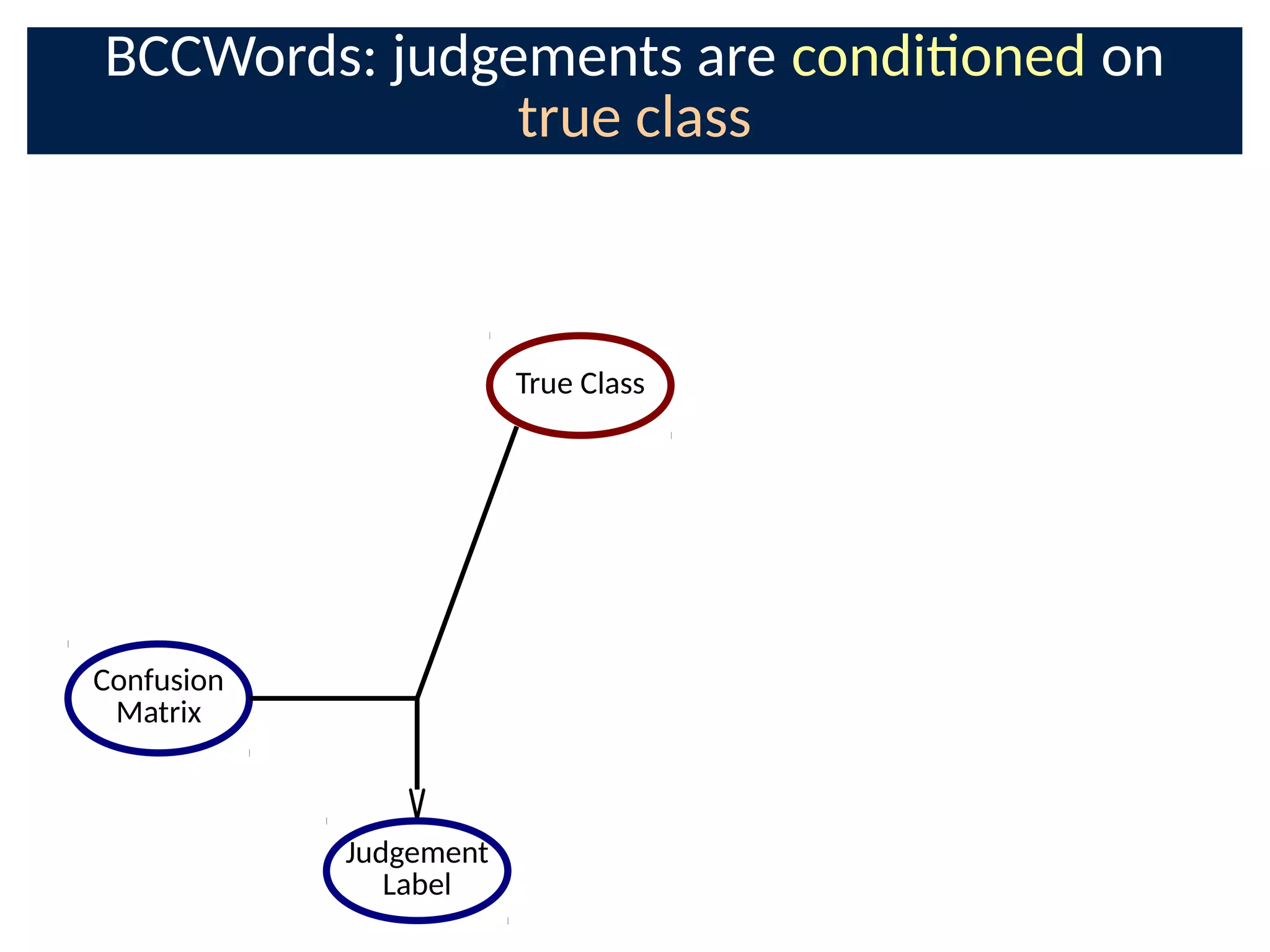
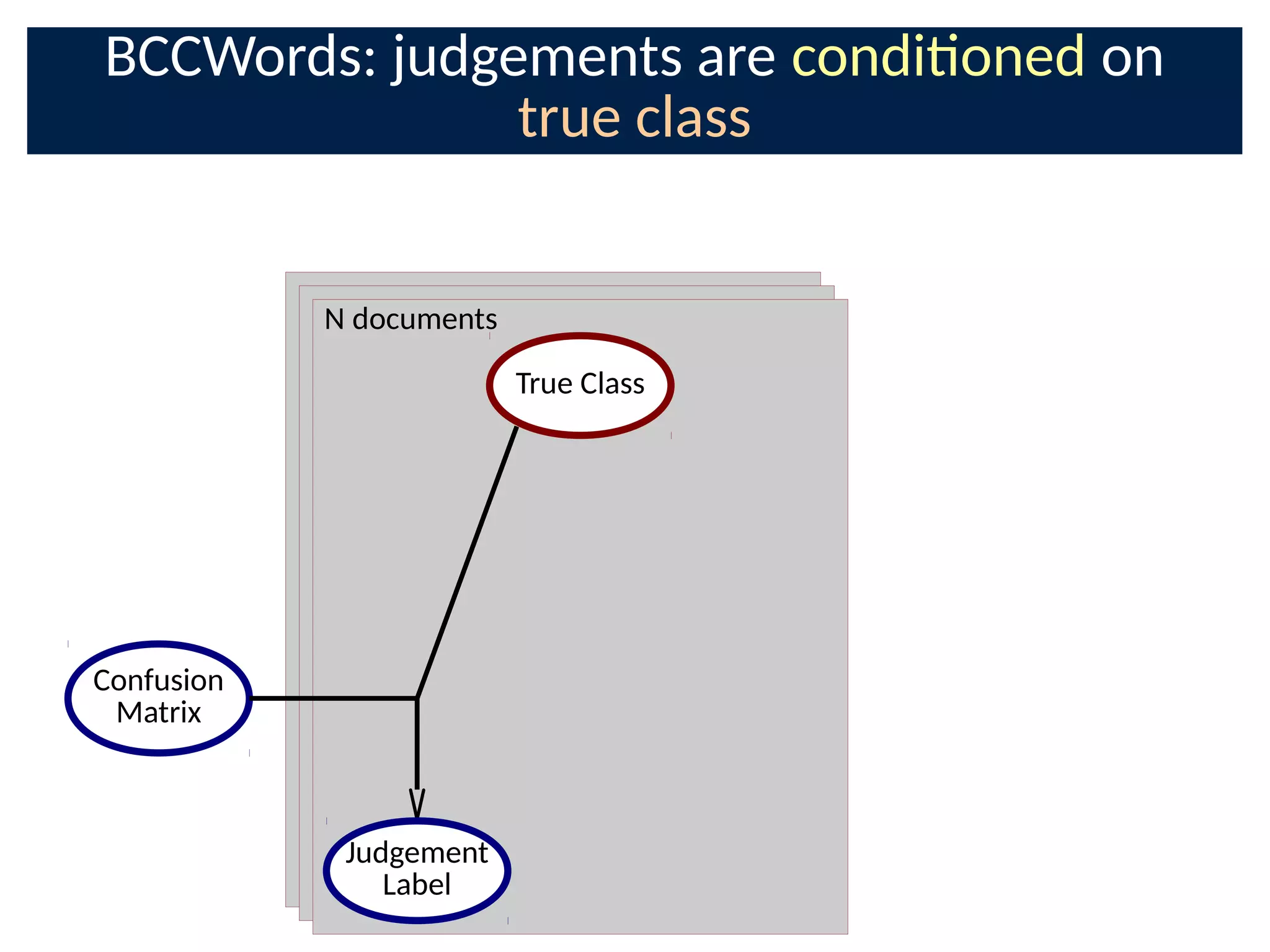
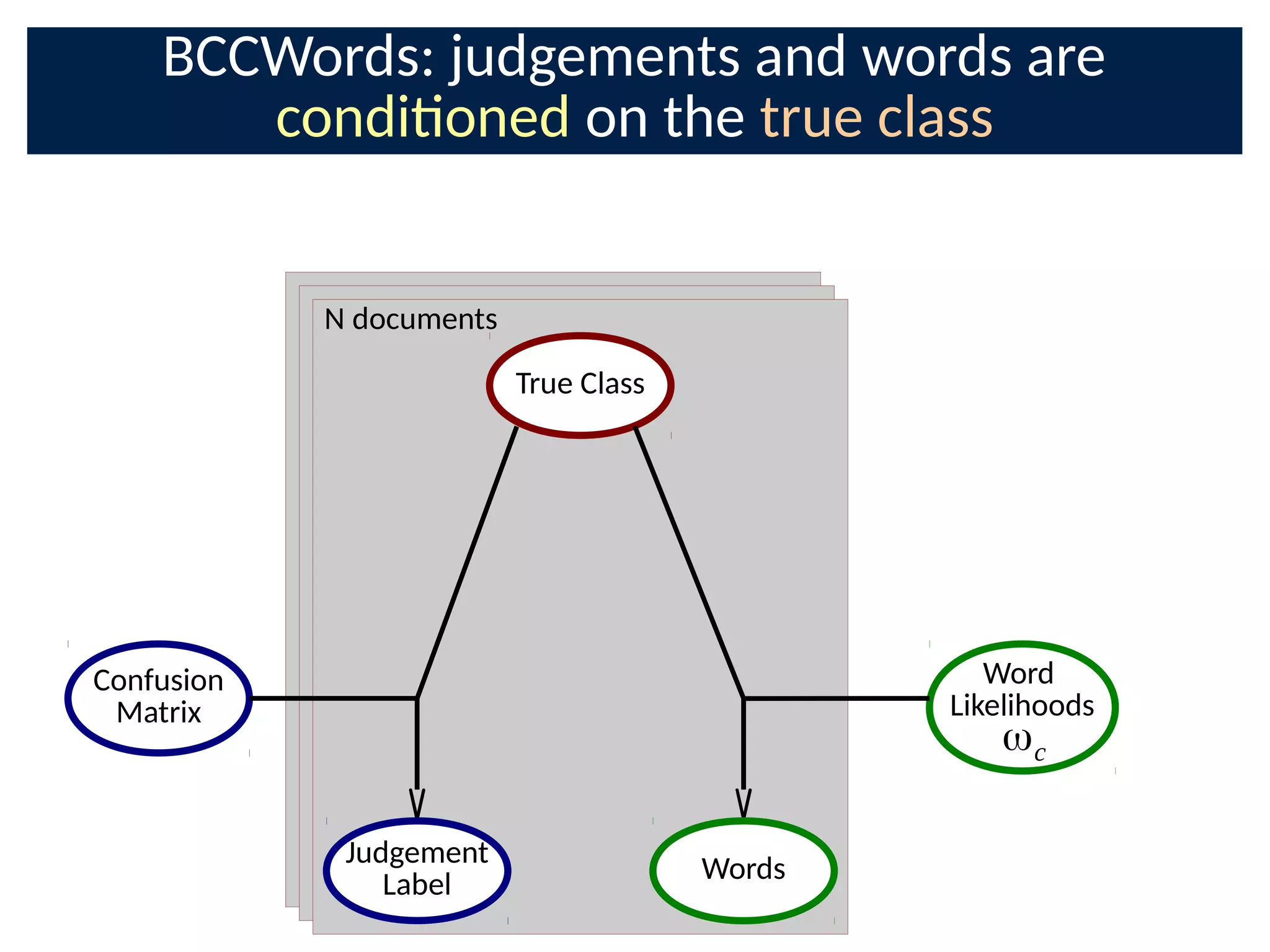
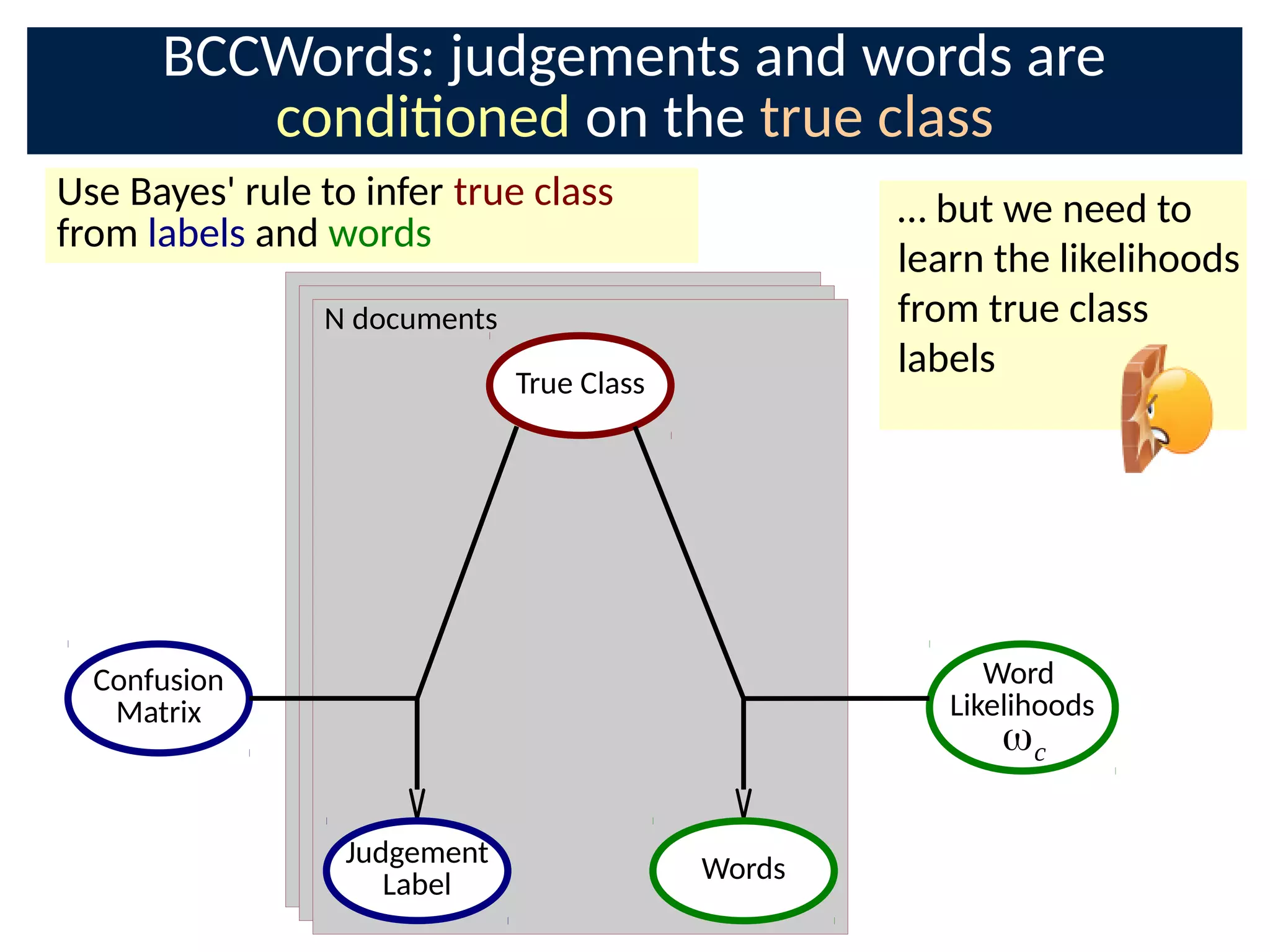
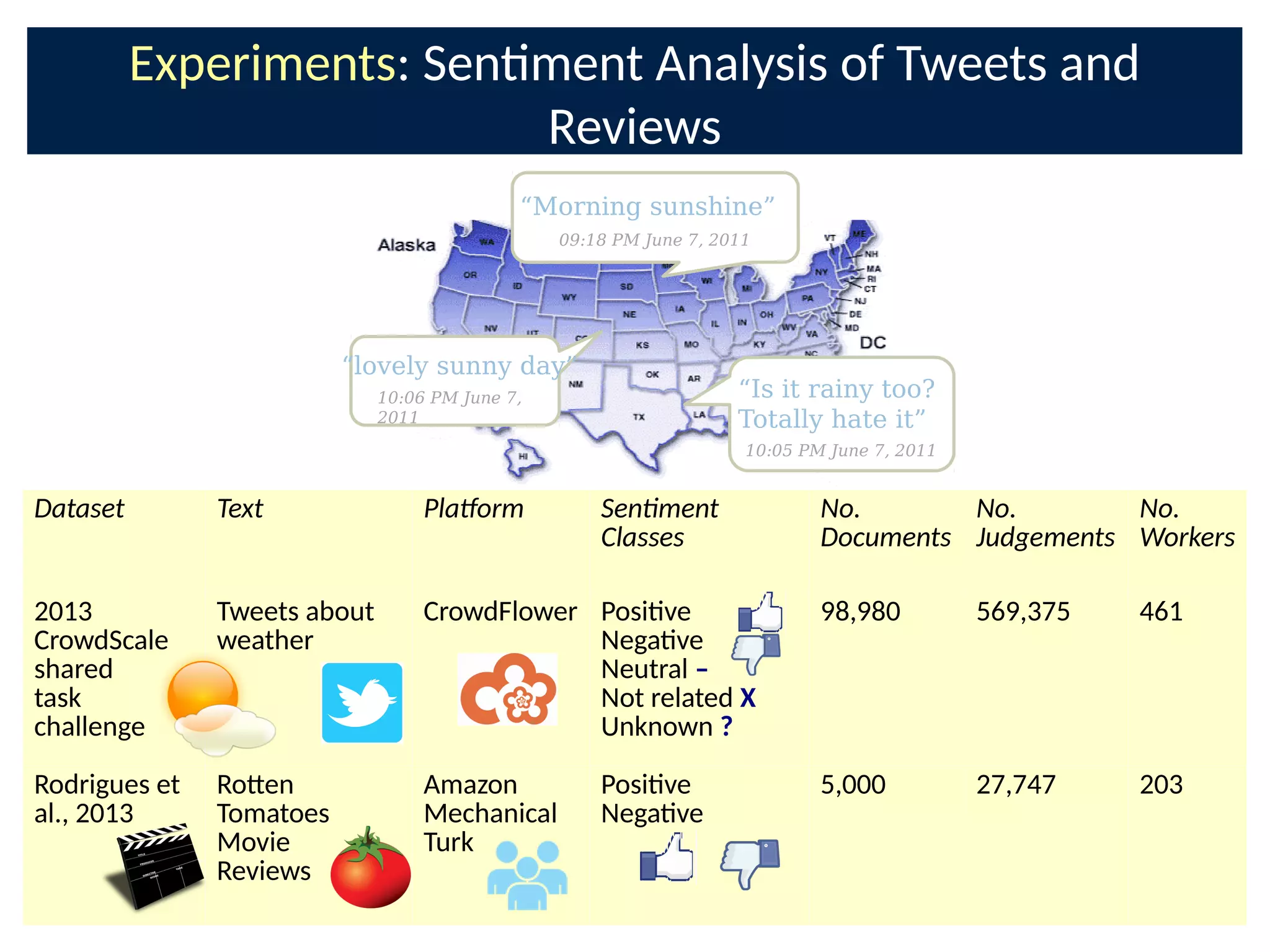
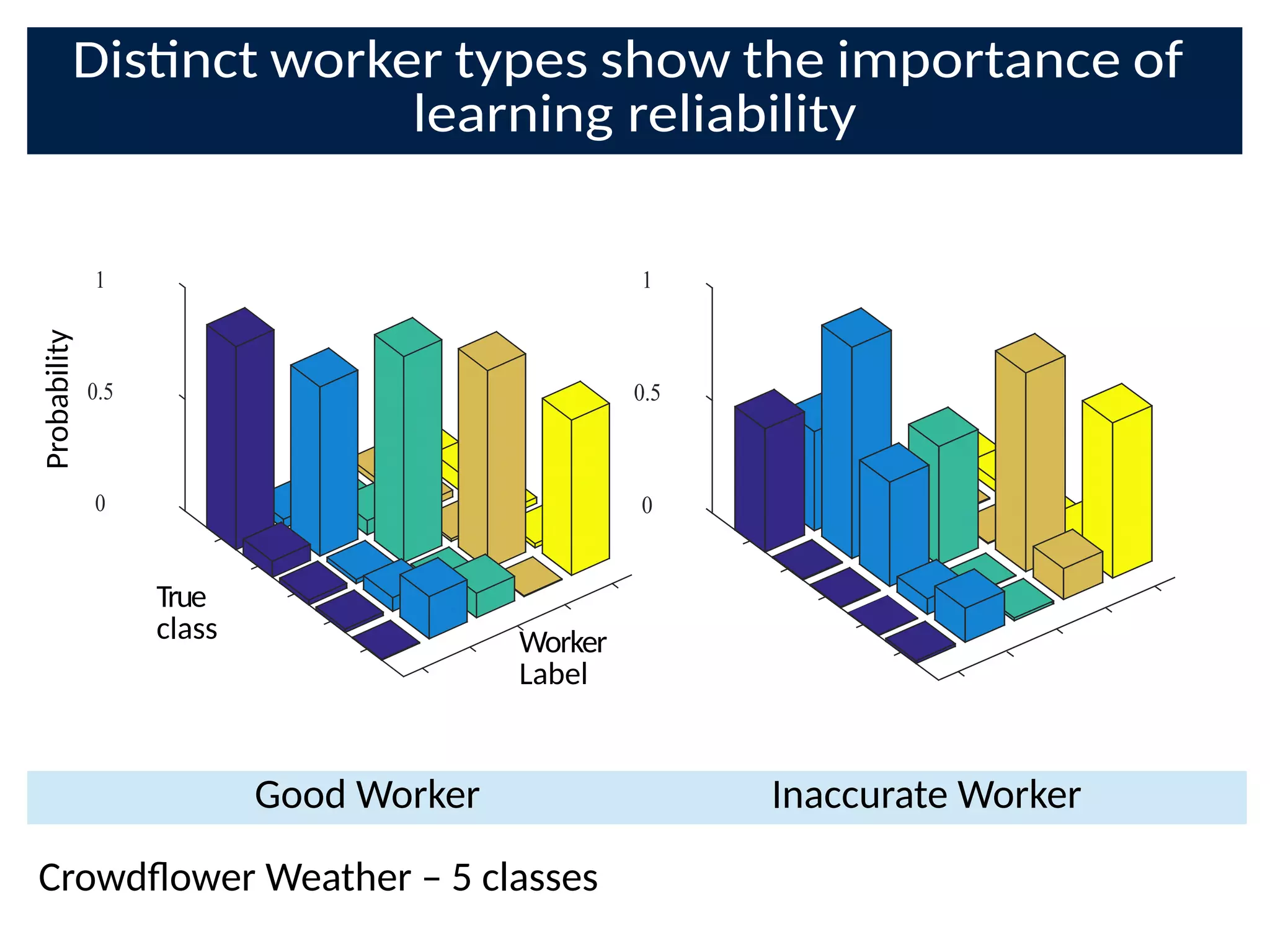
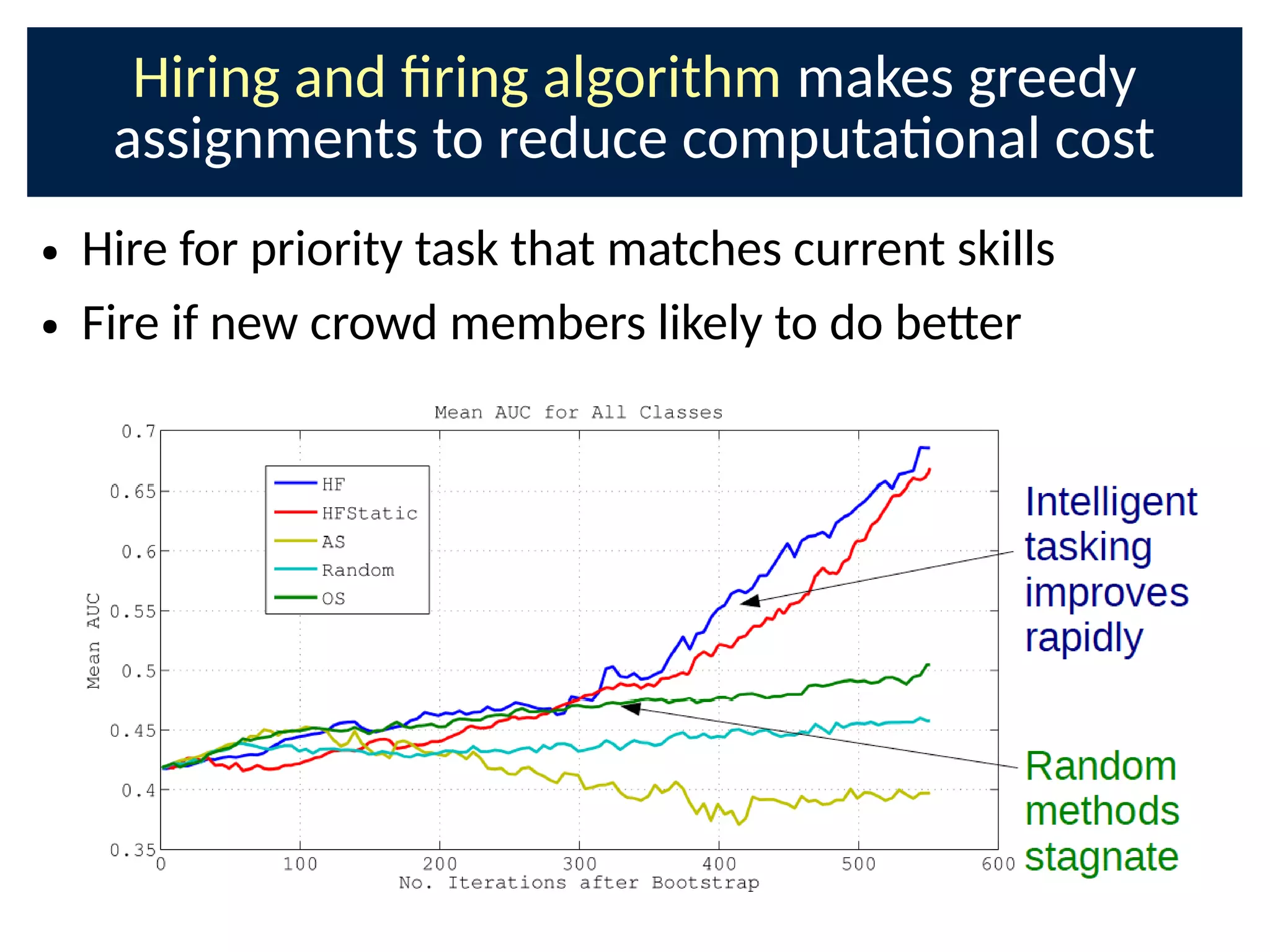
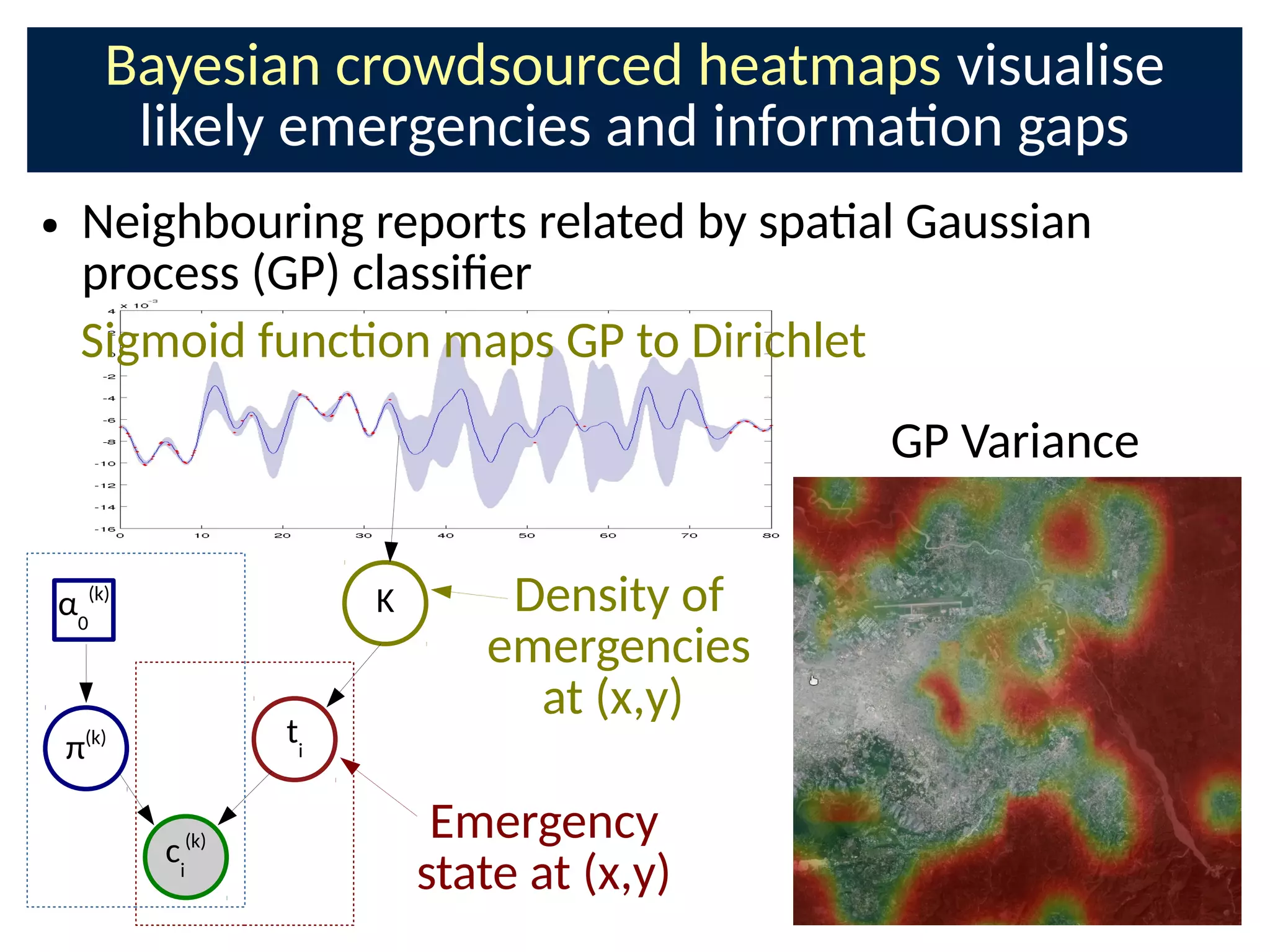
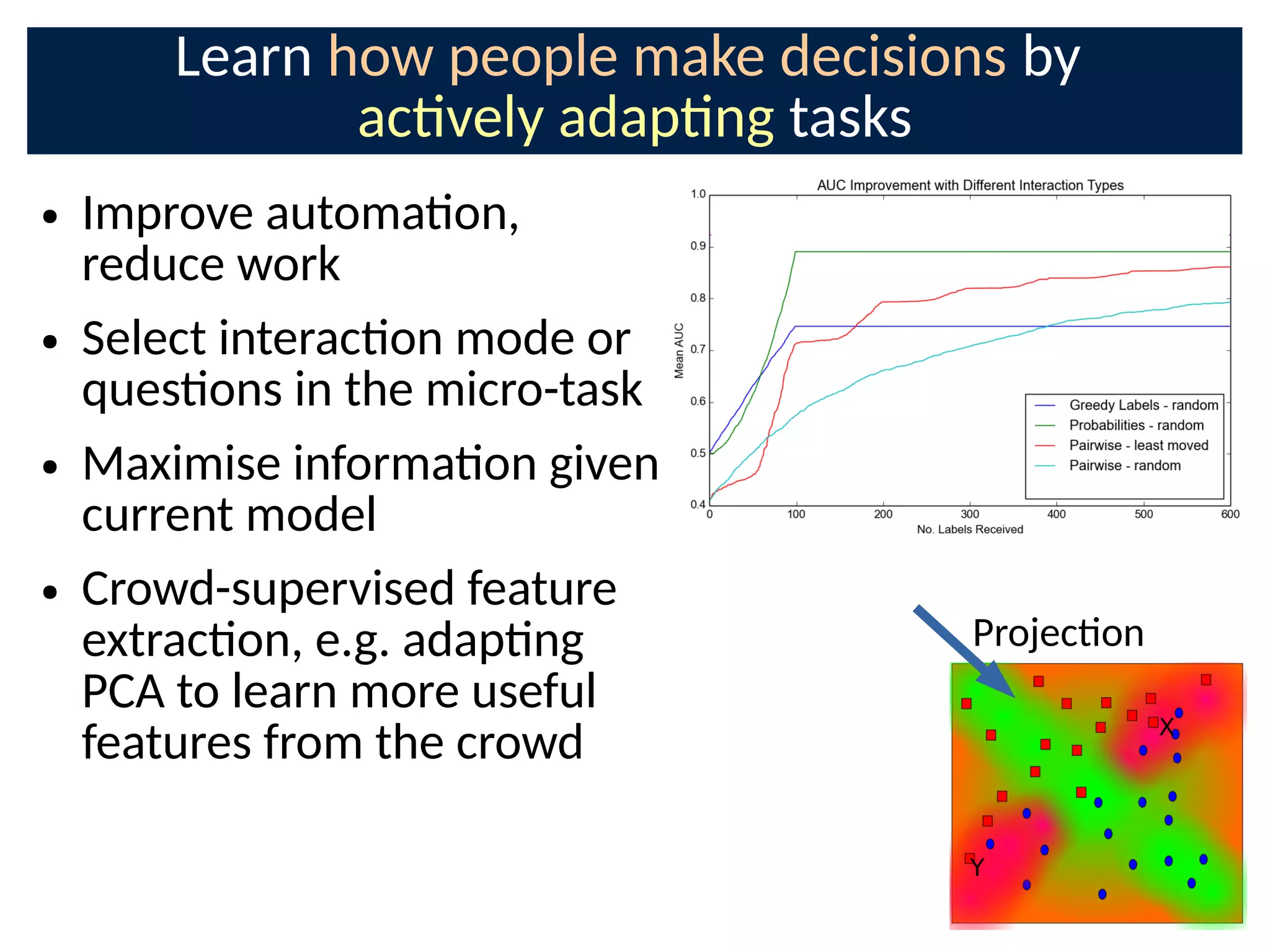
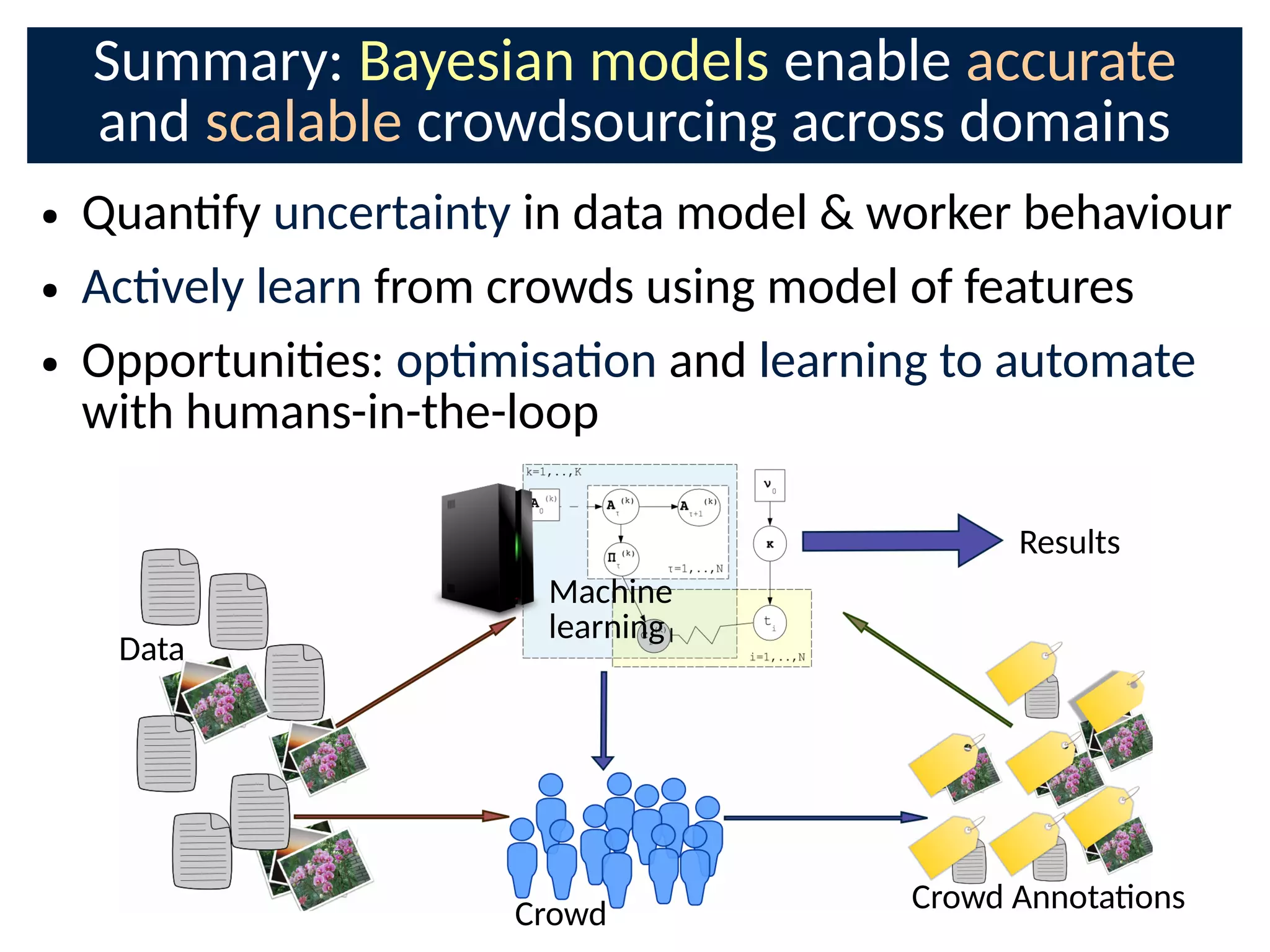
The document discusses the application of Bayesian methods to enhance citizen science and crowdsourcing through effective information fusion and handling of uncertainties. It emphasizes the importance of efficiently allocating volunteer efforts, learning worker reliability, and utilizing machine learning to aggregate responses and optimize task assignments. Various case studies and models are presented to illustrate the practical applications and benefits of these methodologies in managing large datasets and improving decision-making in collaborative settings.


















![Community detecon over E[π] matrices:
behaviour types among Zooniverse users
Sensible Extreme Random Opmist Pessimist
● vbIBCC provides insights into crowd behaviour using
Bayesian community analysis
● Design training to inOuence these types
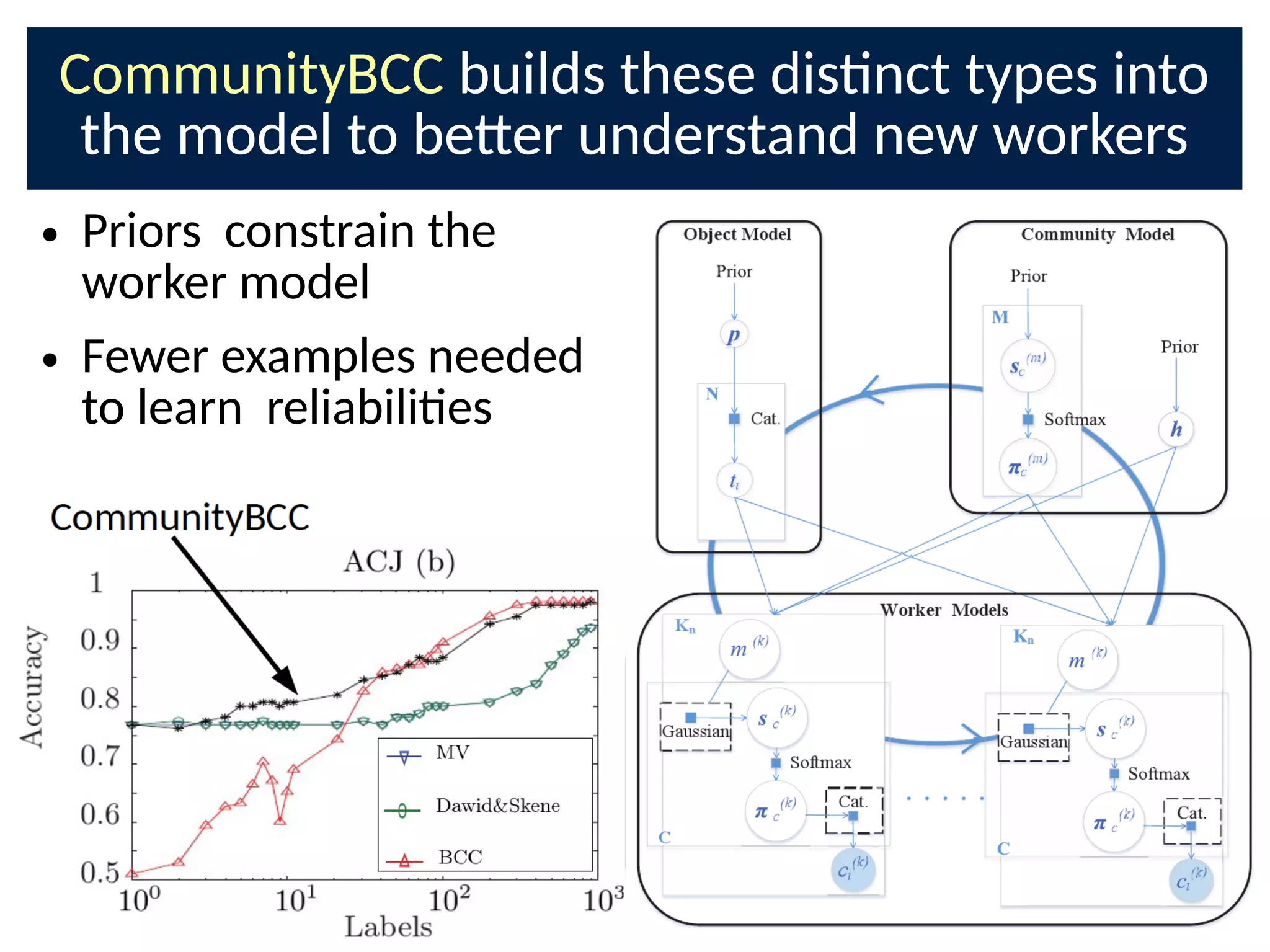
● CommunityBCC builds these types into the model to
be-er predict new workers](https://image.slidesharecdn.com/bayesnetsati2017cuts-170126093028/75/Professor-Steve-Roberts-The-Bayesian-Crowd-scalable-informati-on-combinati-on-for-Citi-zen-Science-and-Crowdsourcing-31-2048.jpg)

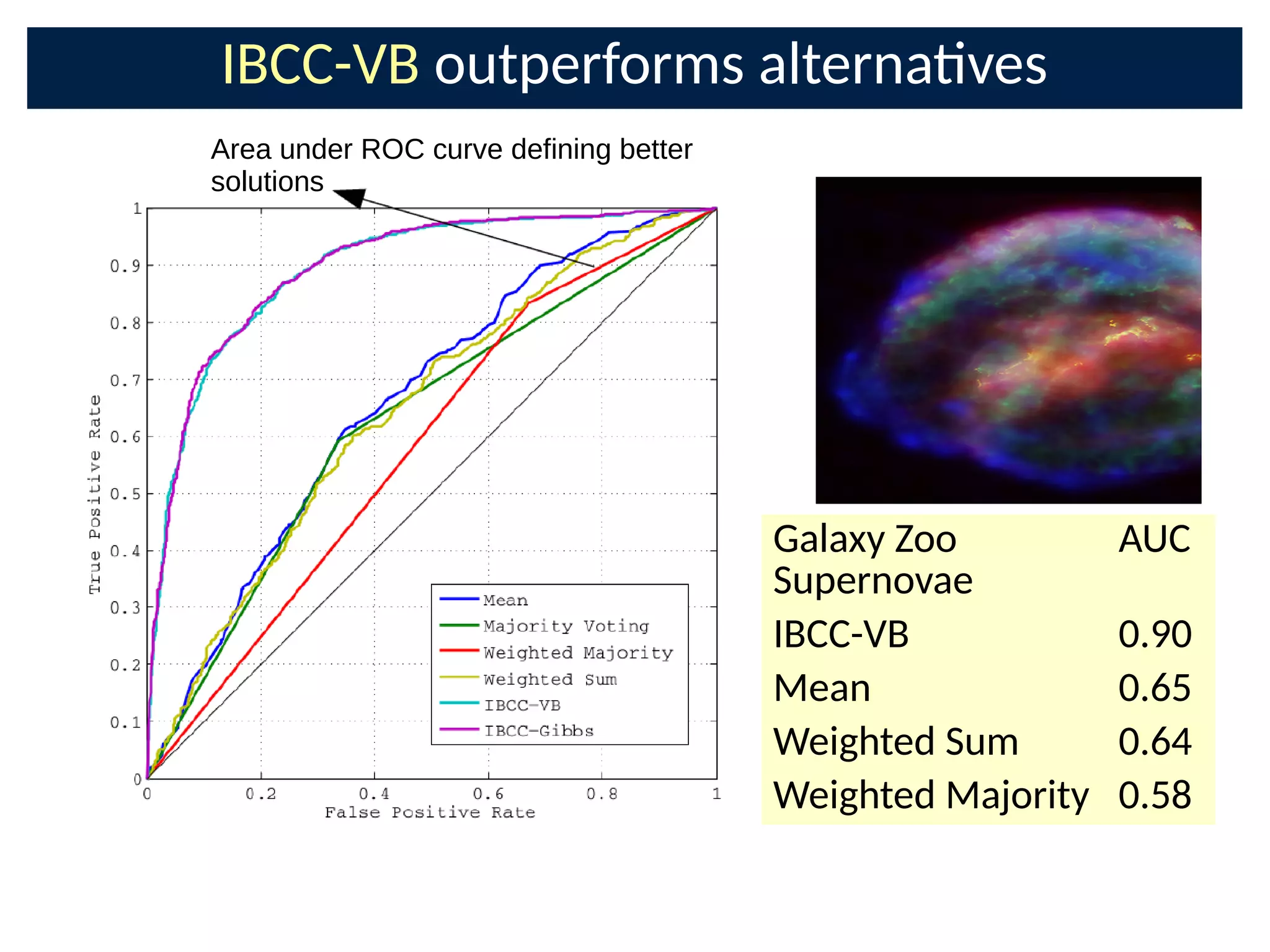
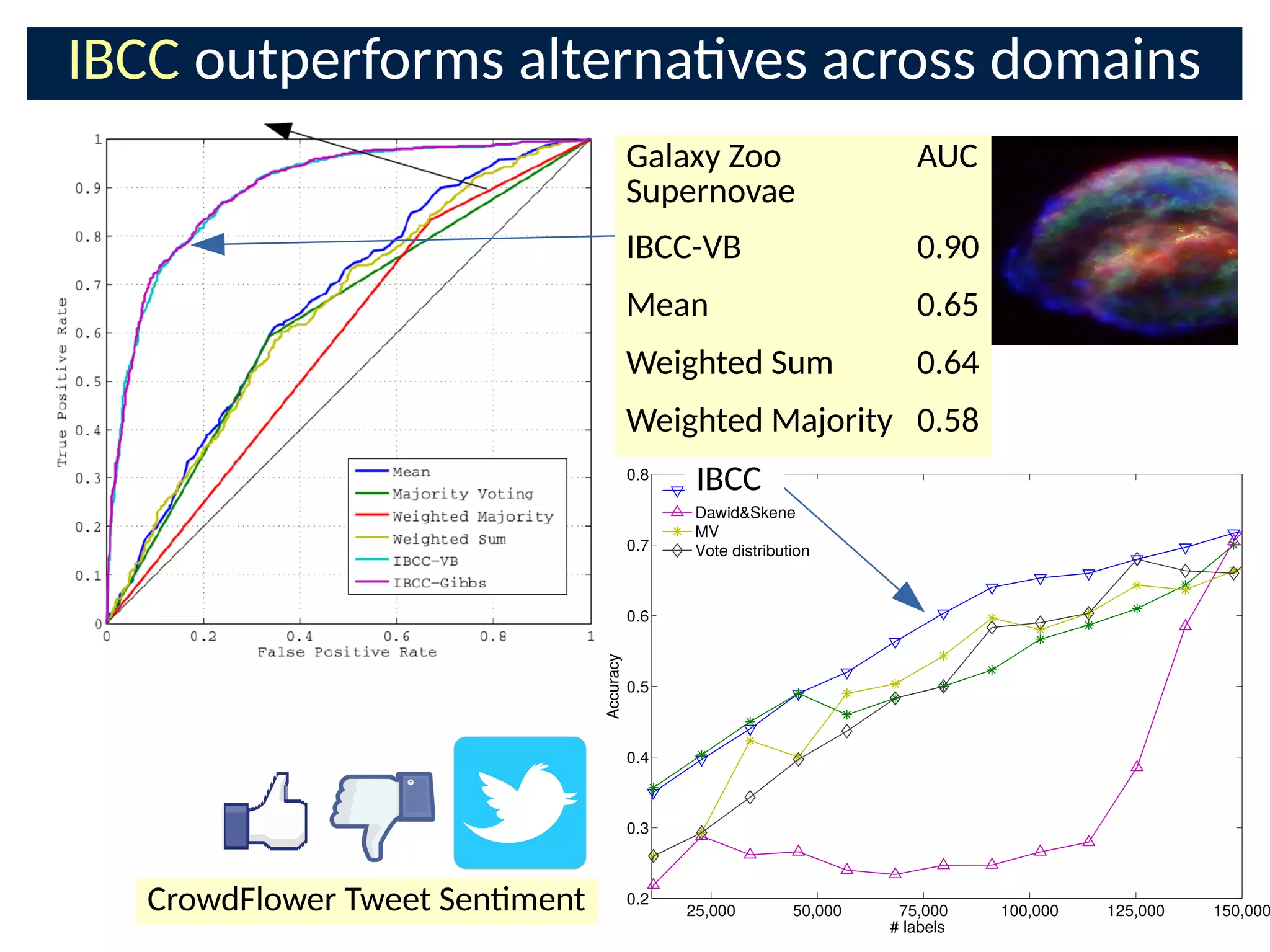
![Combining the crowd with features:
TREC Crowdsourcing Challenge
● IBCC + 2000 LDA features acng
as addional classiCers [11]
● Classify unlabelled documents
● Results:
– 0.81 AUC with only 16%
documents labelled at all
– 0.77 for next-best approach
– 1st place required mulple
labellings of all documents](https://image.slidesharecdn.com/bayesnetsati2017cuts-170126093028/75/Professor-Steve-Roberts-The-Bayesian-Crowd-scalable-informati-on-combinati-on-for-Citi-zen-Science-and-Crowdsourcing-39-2048.jpg)







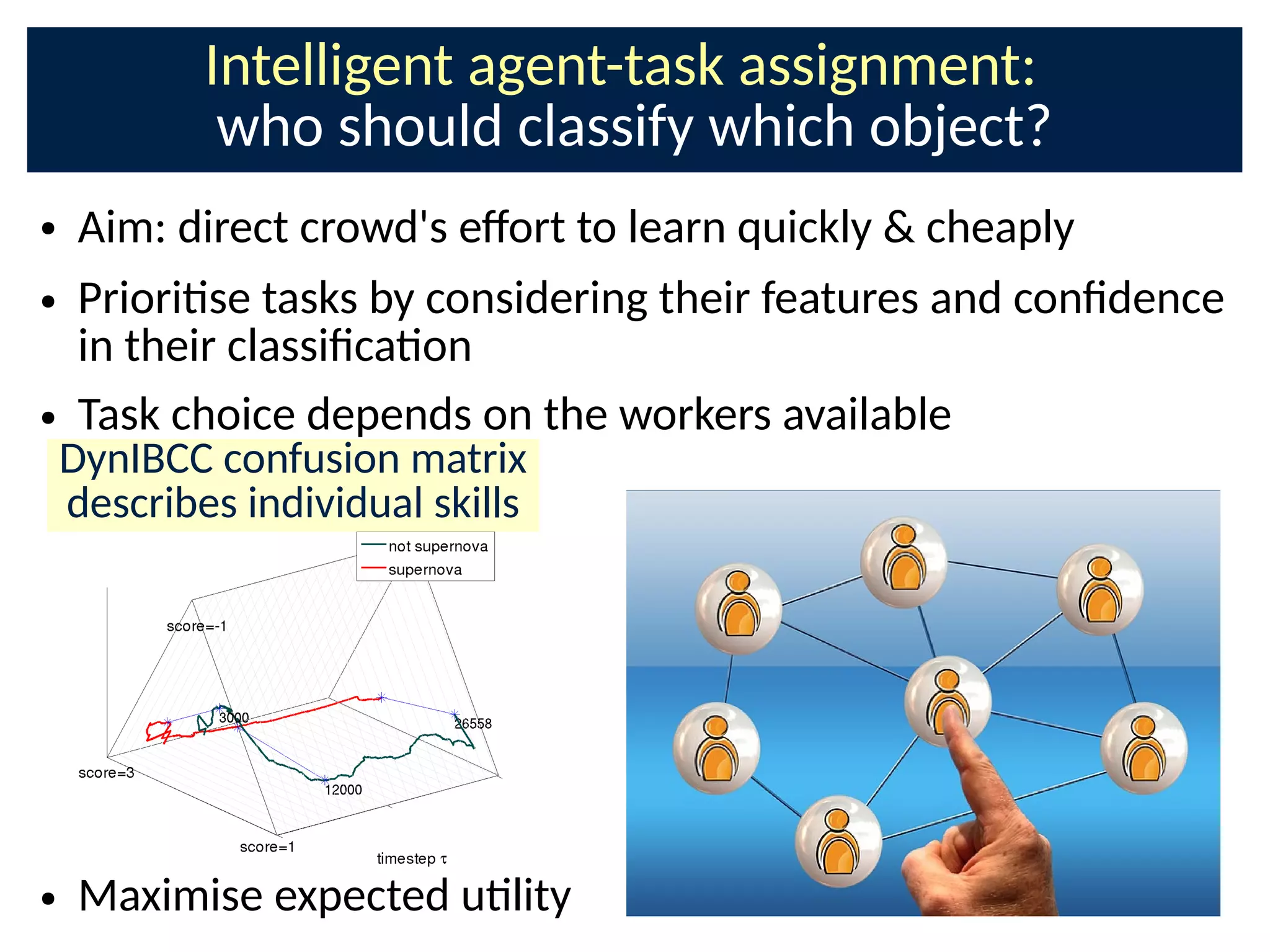
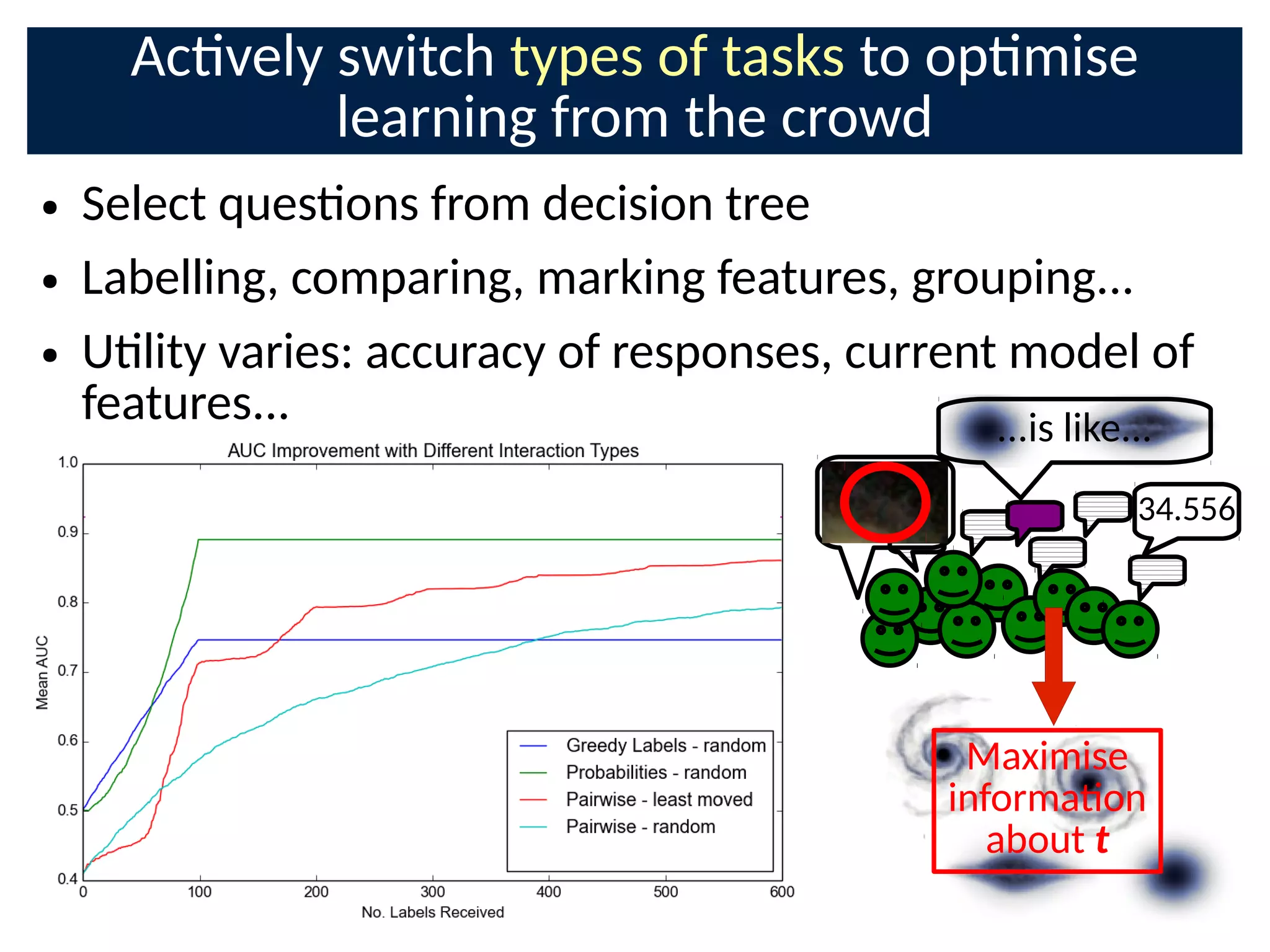
![Ulity of response: informaon gain about
targets when DynIBCC is updated
● Naturally balances exploraon exploitaon
● Explore an agent's behaviour from silver tasks
– Objects already labelled conCdently by crowd
– Increases ulity of past responses
● Exploit an agent's skills to learn uncertain targets t
E[U τ (k ,i)]=E[ I (t ; ci
(k)
∣Dτ )]
Index of target object
Worker ID
Crowdsourced data
collected so far
Time index](https://image.slidesharecdn.com/bayesnetsati2017cuts-170126093028/75/Professor-Steve-Roberts-The-Bayesian-Crowd-scalable-informati-on-combinati-on-for-Citi-zen-Science-and-Crowdsourcing-61-2048.jpg)
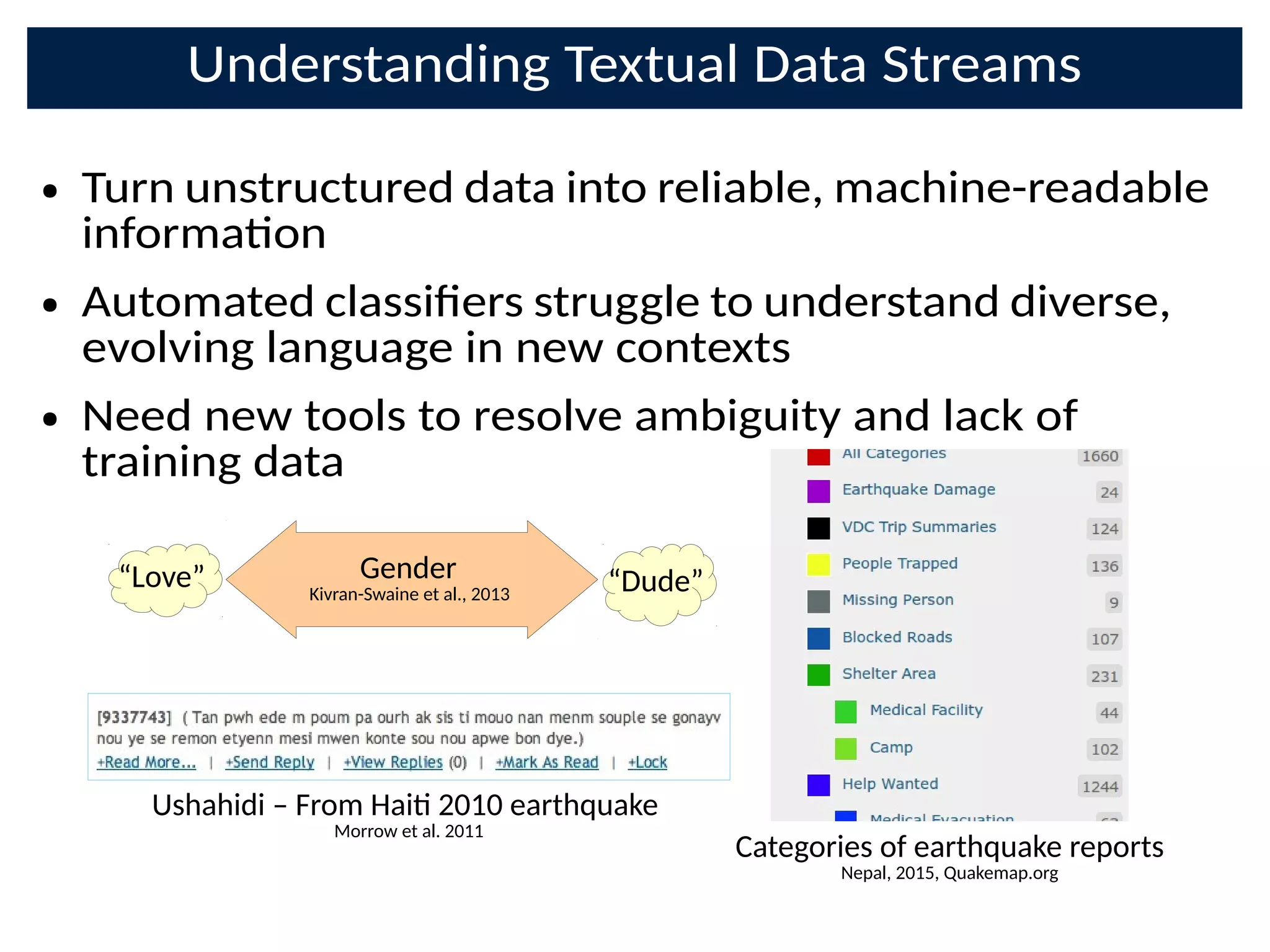
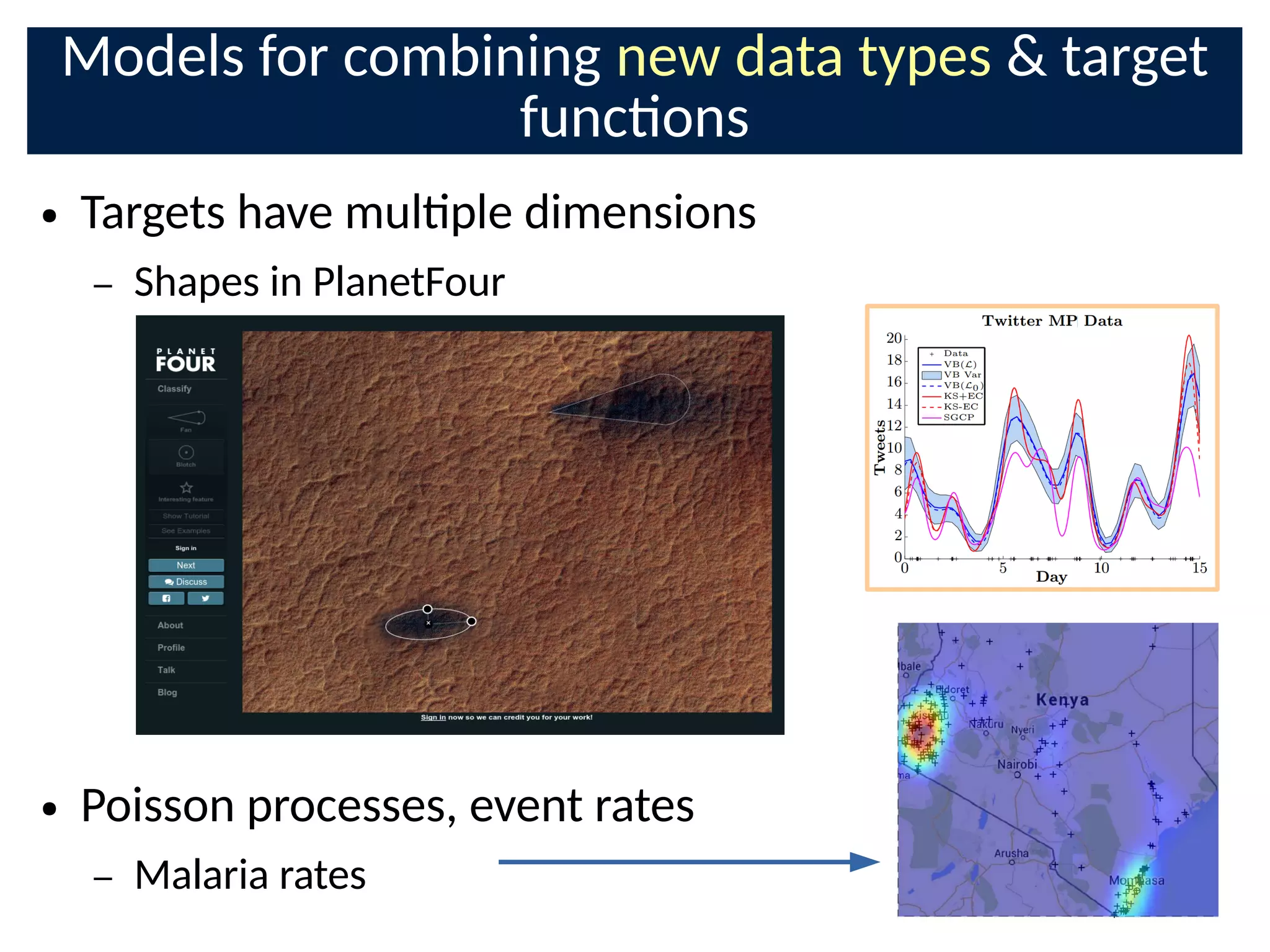
![Loose crowds on the web in organisaons:
Disaster Response
● Extracng key informaon from noisy background
– Text: Twi-er, Ushahidi 15000 messages in a few weeks [8]
– Images: Satellite, Social Media
– Team communicaons, other agencies
● Locaons of emergencies:
– connuous target funcon](https://image.slidesharecdn.com/bayesnetsati2017cuts-170126093028/75/Professor-Steve-Roberts-The-Bayesian-Crowd-scalable-informati-on-combinati-on-for-Citi-zen-Science-and-Crowdsourcing-63-2048.jpg)





![References
[1] Dawid, A. P., Skene, A. M. (1979). Maximum likelihood esmaon of observer error-rates using the EM algorithm. Applied stascs, 20-28.
[2] Kim, H. C., Ghahramani, Z. (2012). Bayesian classiCer combinaon. In Internaonal conference on arCcial intelligence and stascs (pp. 619-
627).
[3] E. Simpson, S. Roberts, I. Psorakis, A. Smith and C. Linto- (2011). Bayesian Combinaon of Mulple, Imperfect ClassiCers. Proceedings of NIPS
2011 workshop
[4] Simpson, E., Roberts, S., Psorakis, I., Smith, A. (2013). Dynamic bayesian combinaon of mulple imperfect classiCers. In Decision Making and
Imperfecon (pp. 1-35). Springer.
[5] Psorakis, I., Roberts, S., Ebden, M., Sheldon, B. (2011). Overlapping Community Detecon using Bayesian Nonnegave Matrix Factorizaon.
Physical Review E, 83.
[6] Venanzi, M., Guiver, J., Kazai, G., Kohli, P., Shokouhi, M. (2014). Community-based bayesian aggregaon models for crowdsourcing. In
Proceedings of the 23rd internaonal conference on World wide web (pp. 155-164). Internaonal World Wide Web Conferences Steering
Commi-ee.
[7] E. Simpson, S. Roberts (2015 – to appear). Bayesian Methods for Intelligent Task Assignment in Crowdsourcing Systems, Scalable Decision
Making: Uncertainty, Imperfecon, Deliberaon; Studies in Computaonal Intelligence, Springer
[8] N. Morrow, N. Mock, A. Papendieck, and N. Kocmich (2011). Independent Evaluaon of the Ushahidi Hai Project. Development Informaon
Systems., 8:2011.
[9] MacKay, David J. C. (1992). Informaon-based objecve funcons for acve data selecon. Neural computaon, 4(4):590–604.
[10]Chen, X., Benne-, P. N., Collins-Thompson, K., and Horvitz, E. (2013). Pairwise ranking aggregaon in a crowdsourced se`ng. In Proceedings of
the sixth ACM internaonal conference on Web search and data mining. ACM
[11]E. Simpson, S. Reece, A. Penta, G. Ramchurn, and S. Roberts (2012). Using a Bayesian Model to Combine LDA Features with Crowdsourced
Responses. In The Twenty-First Text REtrieval Conference (TREC 2012), Crowdsourcing Track, NIST.
[12]S. Nitzan, J. Paroush (1982). Opmal decision rules in uncertain dichotomous choice situaons. Internaonal Economic Review, 23(2):289–297,
1982.
[13]D. Berend, A. Kontorovich (2014). Consistency of Weighted Majority Votes. NIPS
[14]Y. Zhang, X. Chen, D. Zhou, M. Jordan (2014). Spectral methods meet EM: a Provable Opmal Algorithm for Crowdsourcing.](https://image.slidesharecdn.com/bayesnetsati2017cuts-170126093028/75/Professor-Steve-Roberts-The-Bayesian-Crowd-scalable-informati-on-combinati-on-for-Citi-zen-Science-and-Crowdsourcing-74-2048.jpg)

![[PR12] understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/pr12understandingdeeplearningrequiresrethinkinggeneralization-180121135850-thumbnail.jpg?width=640&height=640&fit=bounds)






![[PR12] intro. to gans jaejun yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12intro-170416162251-thumbnail.jpg?width=640&height=640&fit=bounds)








![[GAN by Hung-yi Lee]Part 2: The application of GAN to speech and text processing](https://cdn.slidesharecdn.com/ss_thumbnails/part2v2-180809095331-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] Spectral Normalization for Generative Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/pr12spectralnormalizationforgans-180513142600-thumbnail.jpg?width=640&height=640&fit=bounds)

















































