Downloaded 58 times




![Pre-processing
Lower casing, stripping extra characters
”Realyyyyyyyyyy!!!!!”
Tokenisation (sentences, words)
>>>pktst = nltk.data.load('tokenizers/punkt/english.pickle')
>>>sentences = pktst.tokenize(tweet)
>>>words = nltk.word_tokenize(sent)
Handling Entities
>>> re.sub(r'(^| )@[^ ]+','',tweet).strip()
Removing stopwords
>>> stopwords = set([”a”, ”an”, ”the”, ”by”])
>>> ' '.join([w for w in words if w not in stopwords])](https://image.slidesharecdn.com/text-analysis-with-py-150701102157-lva1-app6891/75/Text-analysis-using-python-6-2048.jpg)

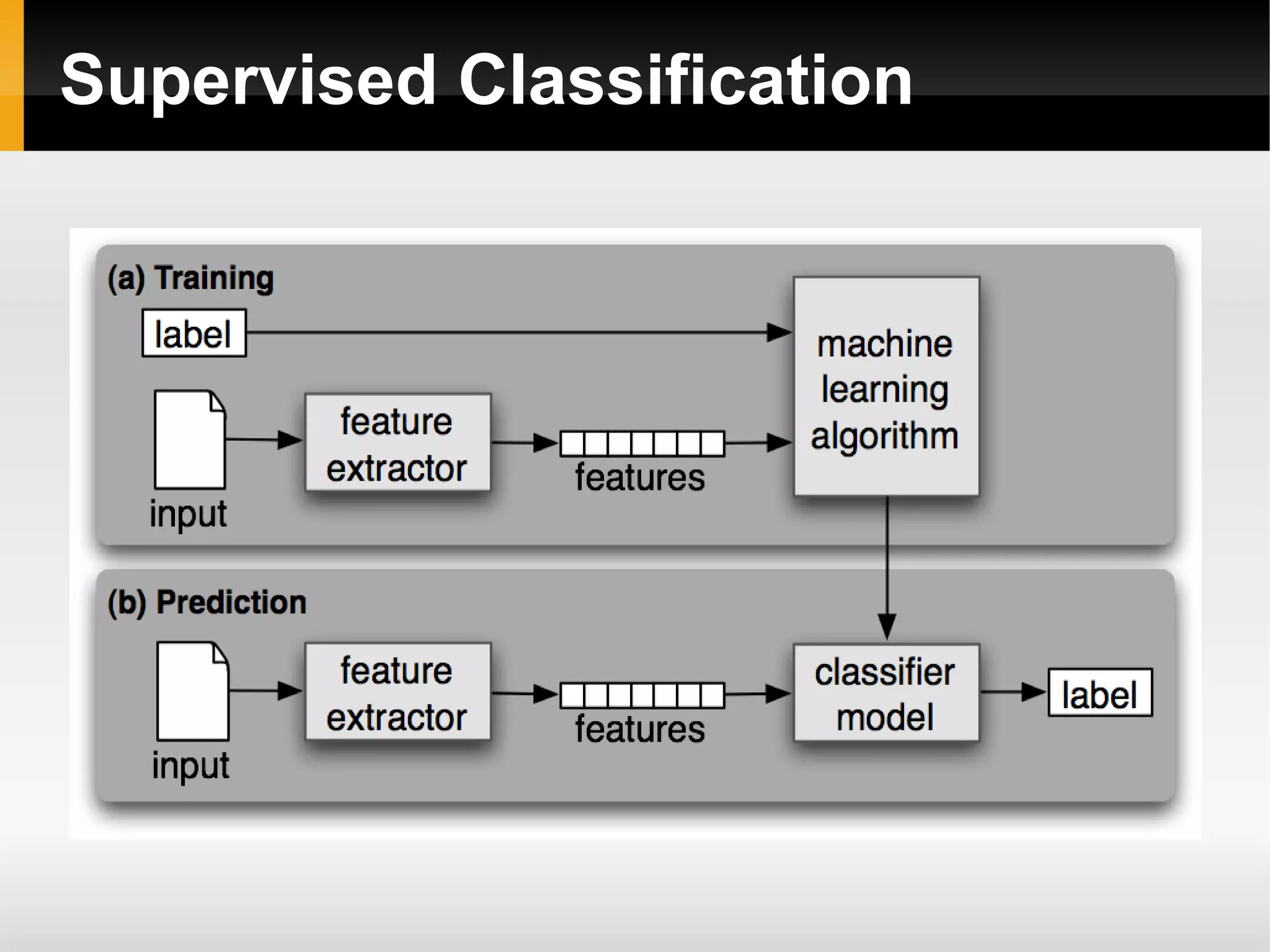


![Training
”Teach” the classifier how to classify, using
training data
>>> from nltk import NaiveBayesClassifier as nbc
>>> trg = generate_features(training_samples)
>>> random.shuffle(trg)
>>> train, test = trg[:int(0.9*len(trg)], trg[int(0.9*len(trg):]
>>> clf = nbc.train(train)
>>> nltk.classify.accuracy(clf, test)](https://image.slidesharecdn.com/text-analysis-with-py-150701102157-lva1-app6891/75/Text-analysis-using-python-11-2048.jpg)

![A Gender Classifier
def gender_features(word):
return {'last_letter': word[-1]}
names = ([(name, 'male') for name in names.words('male.txt')] +
[(name, 'female') for name in names.words('female.txt')])
featuresets = [(gender_features(n), g) for (n,g) in names]
train_set, test_set = featuresets[500:], featuresets[:500]
classifier = nltk.NaiveBayesClassifier.train(train_set)
nltk.classify.accuracy(classifier, test_set)](https://image.slidesharecdn.com/text-analysis-with-py-150701102157-lva1-app6891/75/Text-analysis-using-python-13-2048.jpg)












This document provides an overview of text analysis with Python. It discusses common text mining tasks like entity recognition, sentiment analysis, and categorization. It promotes Python for short, concise text processing using tools like NLTK, Scipy, NumPy, and Scikit-learn. Key pre-processing steps covered include lowercasing, tokenization, handling entities, and removing stopwords. Supervised classification techniques like Naive Bayes classifiers and maximum entropy models are explained. Examples presented include a gender classifier and a system for recognizing questions in tweets.


































































