Download as ODP, PPTX












![Parallel Collections with Meta-class enhancer
ParallelEnhancer
def list = [1,2,3,4,5,6,7,8]
ParallelEnhancer.enhanceInstance(list)
println list.collectParallel{it * 2}](https://image.slidesharecdn.com/gpars-120713094710-phpapp01/85/GPars-Groovy-Parallel-Systems-13-320.jpg)
![Parallel Collections with Meta-class enhancer
ParallelEnhancer
def animals = ['dog','ant','cat','whale']
ParallelEnhancer.enhanceInstance(animals)
println(animals.anyParallel{it=='ant'} ? 'Found
an ant' : 'No ants found')
println(animals.everyParallel{it.contains("a")}
? 'All animals contain a' : 'Some animals can
live without a')](https://image.slidesharecdn.com/gpars-120713094710-phpapp01/85/GPars-Groovy-Parallel-Systems-14-320.jpg)
![Parallel Collections – Warning
Don't do this
def thumbnails = []
images.eachParallel{
thumbnails << it.thumbnail
}](https://image.slidesharecdn.com/gpars-120713094710-phpapp01/85/GPars-Groovy-Parallel-Systems-15-320.jpg)
















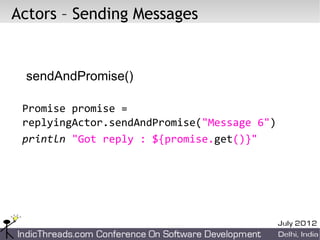



![Blocking Actors
def decryptor = blockingActor {
while (true) {
receive {message ->
if (message instanceof String)
reply message.reverse()
else stop()
}
}
}
def console = blockingActor {
decryptor.send 'lellarap si yvoorG'
println 'Decrypted message: ' + receive()
decryptor.send false
}
[decryptor, console]*.join()](https://image.slidesharecdn.com/gpars-120713094710-phpapp01/85/GPars-Groovy-Parallel-Systems-37-320.jpg)




















GPars is an open-source concurrency and parallelism library for Groovy and Java, aimed at enhancing data parallelism and resolving common concurrency issues like deadlocks and race conditions. The library provides high-level abstractions such as actors, agents, and dataflow for efficient parallel computing, with features like parallel collections and map-reduce capabilities. Additionally, it offers asynchronous invocation methods and various actor types, including stateless and stateful actors, to facilitate message passing and processing in concurrent applications.





























































