Download to read offline





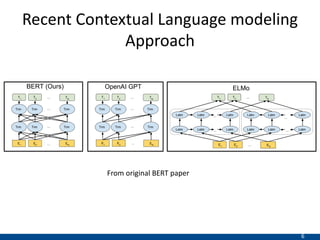
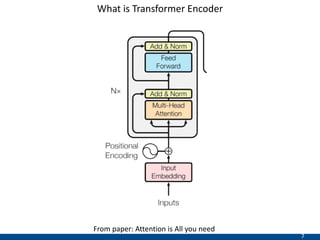
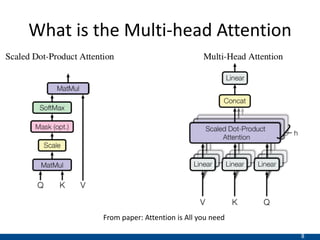
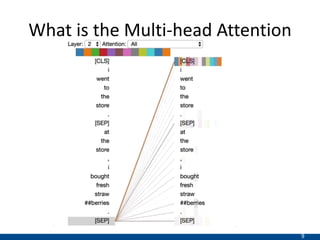

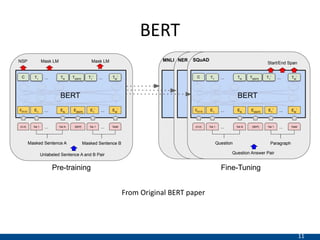









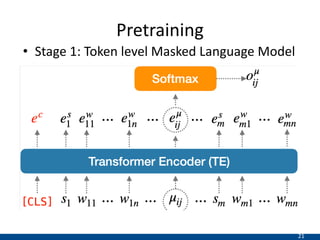
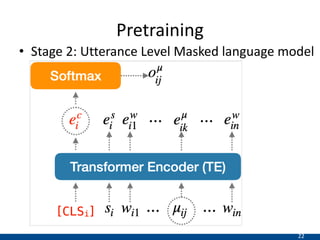

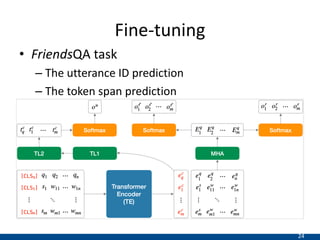





























The document presents an approach using transformers to learn hierarchical contexts in multiparty dialogue. It proposes new pre-training tasks to improve token-level and utterance-level embeddings for handling dialogue contexts. A multi-task learning approach is introduced to fine-tune the language model for a Friends question answering (FriendsQA) task using dialogue evidence, outperforming BERT and RoBERTa. However, the approach shows no improvement on other character mining tasks from Friends. Future work is needed to better represent speakers and inferences in dialogue.











































![[GAN by Hung-yi Lee]Part 3: The recent research of my group](https://cdn.slidesharecdn.com/ss_thumbnails/part3v2-180809095433-thumbnail.jpg?width=640&height=640&fit=bounds)











































