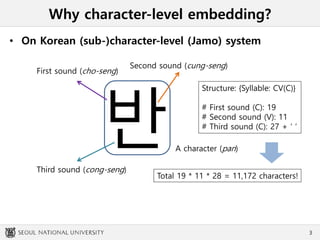
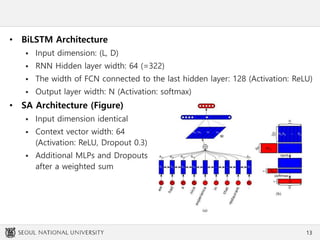
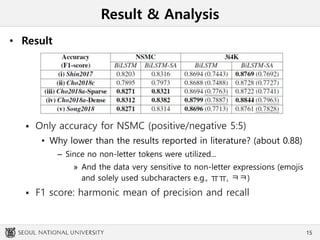
This document summarizes an experiment comparing different character-level embedding approaches for Korean sentence classification tasks. Dense character-level embeddings using pre-trained fastText vectors outperformed sparse one-hot encodings. Character-level embeddings preserved local semantics around character boundaries better than Jamo-level encodings, which performed best with self-attention. While Jamo-level features may be useful for syntax-semantic tasks, character-level approaches had better performance and computation efficiency. These findings provide insights for character-rich languages beyond Korean.



















![Reference (order of appearance)
• Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification.
In Advances in neural information processing systems, pages 649–657.
• Haebin Shin, Min-Gwan Seo, and Hyeongjin Byeon. 2017. Korean alphabet level convolution neural network for
text classification. In Proceedings of Korea Computer Congress 2017 [in Korean], pages 587–589.
• Yong Woo Cho, Gyu Su Han, and Hyuk Jun Lee. 2018c. Character level bi-directional lstm-cnn model for movie
rating prediction. In Proceedings of Korea Computer Congress 2018 [in Korean], pages 1009–1011.
• Won Ik Cho, Sung Jun Cheon, Woo Hyun Kang, Ji Won Kim, and Nam Soo Kim. 2018a. Real-time automatic
word segmentation for user-generated text. arXiv preprint arXiv:1810.13113.
• Won Ik Cho, Hyeon Seung Lee, Ji Won Yoon, Seok Min Kim, and Nam Soo Kim. 2018b. Speech intention
understanding in a head-final language: A disambiguation utilizing intonation-dependency. arXiv preprint
arXiv:1811.04231.
• Mike Schuster and Kuldip K Paliwal. 1997. Bidirectional recurrent neural networks. IEEE Transactions on Signal
Processing, 45(11):2673–2681.
• Zhouhan Lin,Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio.
2017. A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130.
• Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2016. Enriching word vectors with
subword information. arXiv preprint arXiv:1607.04606.
• Francois Chollet et al. 2015. Keras. https://github.com/fchollet/keras.
• Viet Nguyen, Julian Brooke, and Timothy Baldwin. 2017. Sub-character neural language modelling in japanese.
In Proceedings of the First Workshop on Subword and Character Level Models in NLP, pages 148–153.
22](https://image.slidesharecdn.com/1909paclic-190914020811/85/1909-paclic-23-320.jpg)















































![[GAN by Hung-yi Lee]Part 3: The recent research of my group](https://cdn.slidesharecdn.com/ss_thumbnails/part3v2-180809095433-thumbnail.jpg?width=640&height=640&fit=bounds)









![2108 [LangCon2021] kosp2e](https://cdn.slidesharecdn.com/ss_thumbnails/2108langcon2021kosp2e-210902190354-thumbnail.jpg?width=640&height=640&fit=bounds)









![2008 [lang con2020] act!](https://cdn.slidesharecdn.com/ss_thumbnails/2008langcon2020act-200829231450-thumbnail.jpg?width=640&height=640&fit=bounds)



















