Download as PDF, PPTX














![DeepPavlov.ai
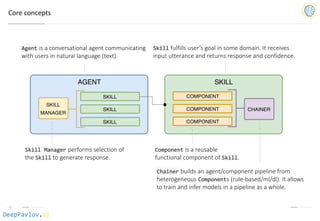
HelloBot in 7 lines in DeepPavlov
SKILL 0
SKILL 1
SKILL MANAGER
SKILL 2
AGENT
from deeppavlov.agents.default_agent.default_agent import DefaultAgent
from deeppavlov.skills.pattern_matching_skill import PatternMatchingSkill
from deeppavlov.agents.processors.highest_confidence_selector import HighestConfidenceSelector
hello = PatternMatchingSkill(responses=['Hello world! :)'], patterns=["hi", "hello", "good day"])
bye = PatternMatchingSkill(['Goodbye world! :(', 'See you around.'], ["bye", "chao", "see you"])
fallback = PatternMatchingSkill(["I don't understand, sorry :/", 'I can say "Hello world!" 8)’])
skill_manager = HighestConfidenceSelector()
HelloBot = Agent([hello, bye, fallback], skills_selector = skill_manager)
print(HelloBot(['Hello!', 'Boo...', 'Bye.’]))](https://image.slidesharecdn.com/deeppavlovos2019-190529124953/85/DeepPavlov-2019-29-320.jpg)
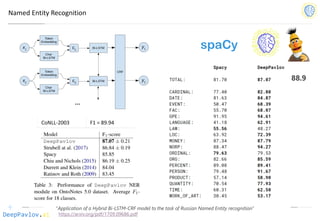
![DeepPavlov.ai
Automatic spelling correction
• We provide two types of pipelines for spelling correction: levenshtein_corrector uses simple Damerau-
Levenshtein distance to find correction candidates and brillmoore uses statistics based error model for
it. In both cases correction candidates are chosen based on context with the help of a kenlm language
model.
Correction method F-measure Speed
(sentences/s)
Yandex.Speller 69.59 5.
[DP] Damerau Levenstein 1 + lm 53.50 29.3
[DP] Brill Moore top 4 + lm 52.91 0.6
Hunspell + lm 44.61 2.1
JamSpell 39.64 136.2
[DP] Brill Moore top 1 39.17 2.4
Hunspell 32.06 20.3](https://image.slidesharecdn.com/deeppavlovos2019-190529124953/85/DeepPavlov-2019-32-320.jpg)


![DeepPavlov.ai
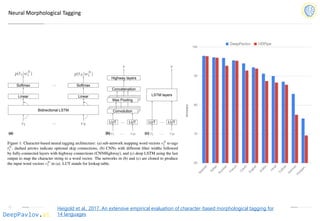
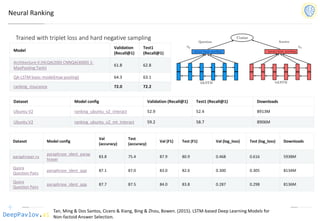
Task-Oriented Dialog (DSTC-2)
Model
Test turn
textual
accuracy
basic bot 0.3809
bot with slot filler & fasttext embeddings 0.5317
bot with slot filler & intents 0.5248
bot with slot filler & intents & embeddings 0.5145
bot with slot filler & embeddings & attention 0.5551
Bordes and Weston (2016) [4] 0.411
Perez and Liu (2016) [5] 0.487
Eric and Manning (2017) [6] 0.480
Williams et al. (2017) [1] 0.556
Jason D. Williams, Kavosh Asadi, Geoffrey Zweig “Hybrid Code Networks: practical and efficient end-to-
end dialog control with supervised and reinforcement learning” – 2017](https://image.slidesharecdn.com/deeppavlovos2019-190529124953/85/DeepPavlov-2019-40-320.jpg)
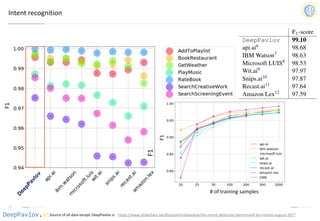
![DeepPavlov.ai
Sequence-To-Sequence Dialogue Bot For Goal-Oriented Task
Model Test BLEU
DeepPavlov implementation of
KV Retrieval Net
13.2
KV Retrieven Net from [1] 13.2
Copy Net from [1] 11.0
Attn. Seq2Seq from [1] 10.2
Rule-Based from [1] 6.60
[1] Mihail Eric, Lakshmi Krishnan, Francois Charette, and Christopher D. Manning, “Key-Value Retrieval Networks for
Task-Oriented Dialogue – 2017
Model Test BLEU
Weather Navigation Schedules
DeepPavlov implementation of
KV Retrieval Net
14.6 12.5 11.9
Wen et al [2] 14.9 13.7 -
[2] Haoyang Wen, Yijia Liu, Wanxiang Che, Libo Qin and Ting Liu. Sequence-to-Sequence Learning for Task-
oriented Dialogue with Dialogue State Representation. COLING 2018.](https://image.slidesharecdn.com/deeppavlovos2019-190529124953/85/DeepPavlov-2019-41-320.jpg)




DeepPavlov is an open-source library for developing conversational AI systems, providing pre-trained NLP models, predefined dialog components, and tools for application integration. It aims to aid AI developers and researchers in creating complex conversational agents with scalability and usability. The library includes a variety of features such as intent recognition, named entity recognition, and support for task-oriented dialogue management.



































































