Download as PDF, PPTX


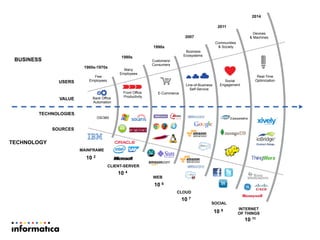


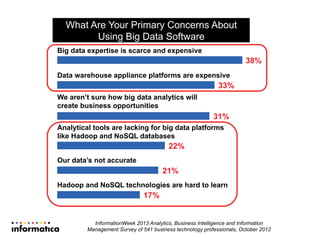

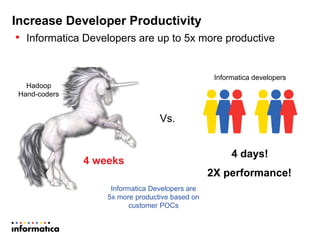

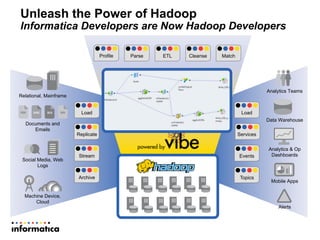
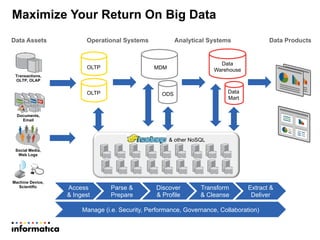
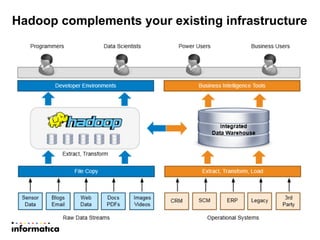
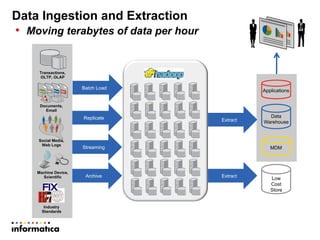
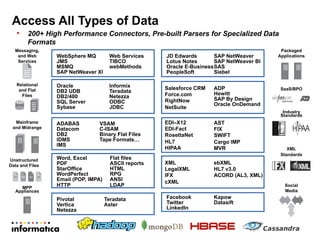

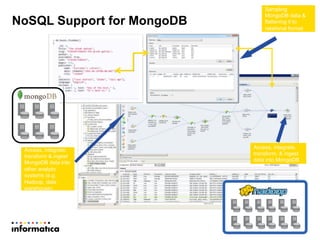


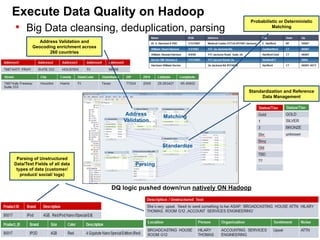



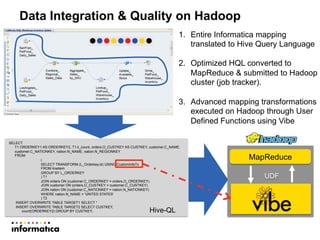

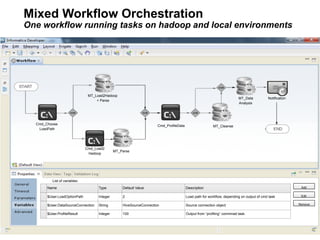
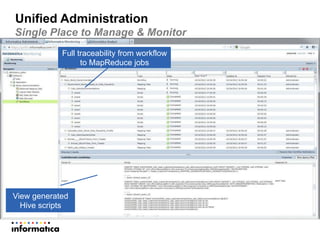
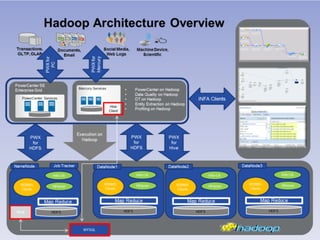


This document discusses building a new generation of intelligent data platforms. It emphasizes that most big data projects spend 80% of time on data integration and quality. It also notes that Informatica developers are 5 times more productive than those coding by hand for Hadoop. The document promotes Informatica's tools for enabling existing developers to work with big data platforms like Hadoop through visual interfaces and pre-built connectors and transformations.
















![[Webinar] Measure Twice, Build Once: Real-Time Predictive Analytics](https://cdn.slidesharecdn.com/ss_thumbnails/infochimpsthinkbigwebinar-130510142153-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Webinar] Getting to Insights Faster: A Framework for Agile Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/agile-big-datav2-131122164332-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






















































































