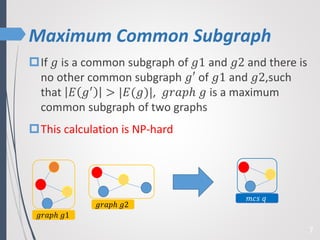
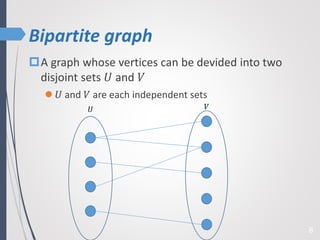
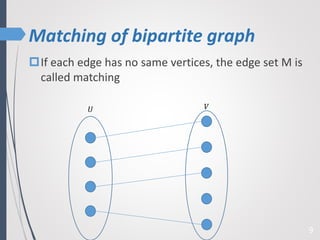
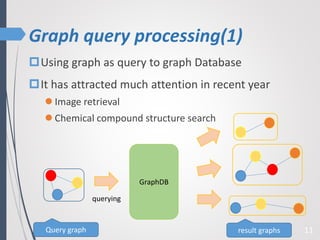
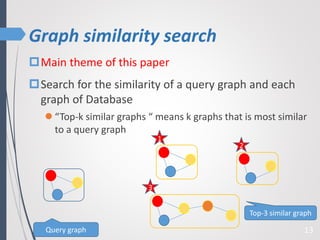
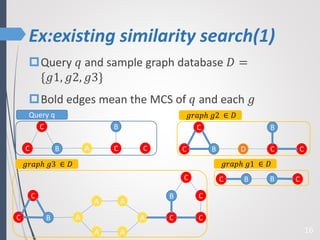
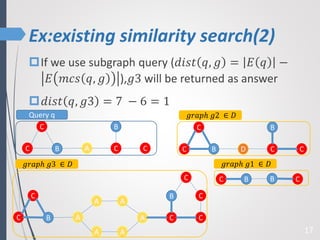
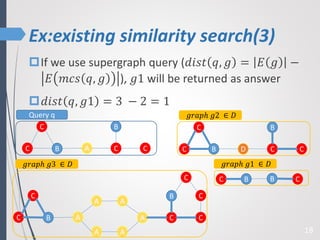
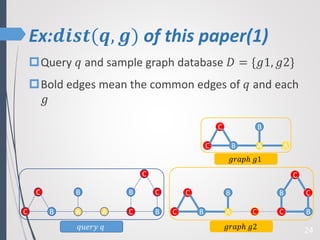
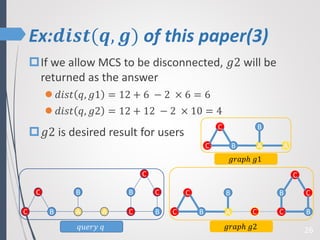
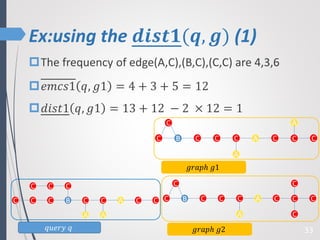
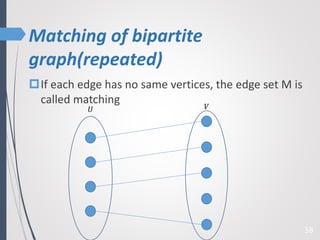
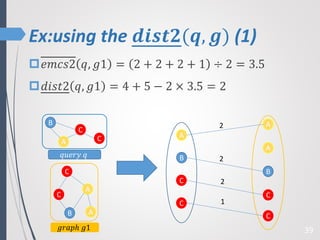
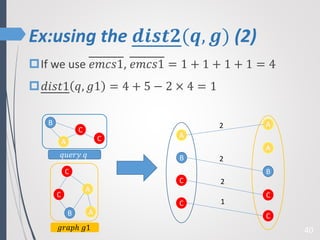
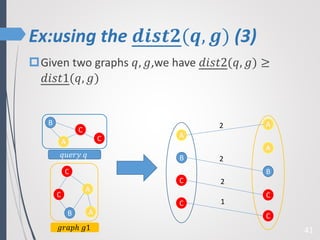
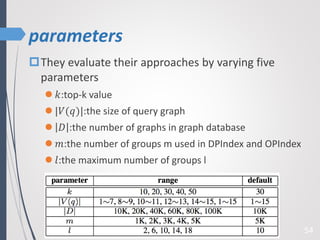
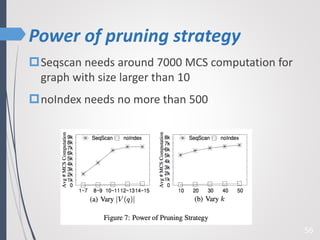
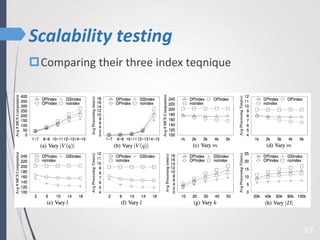
This paper proposes a new technique for top-K graph similarity queries that aims to reduce computational cost. It defines a new distance measure for graphs based on the maximum common subgraph (MCS). It derives several distance lower bounds to prune graphs from consideration without needing to fully compute the MCS. This allows reducing the number of expensive MCS computations. The techniques are evaluated on a real graph dataset to test their performance improvements over existing approaches.