Downloaded 225 times
![Trends in Graph Data Management and Mining Srinath Srinivasa IIIT Bangalore [email_address]](https://image.slidesharecdn.com/trendsingraphdatamanagementandmining-090614120630-phpapp01/75/Trends-In-Graph-Data-Management-And-Mining-1-2048.jpg)

































![Thank You! For more interaction, contact me at [email_address]](https://image.slidesharecdn.com/trendsingraphdatamanagementandmining-090614120630-phpapp01/75/Trends-In-Graph-Data-Management-And-Mining-48-2048.jpg)

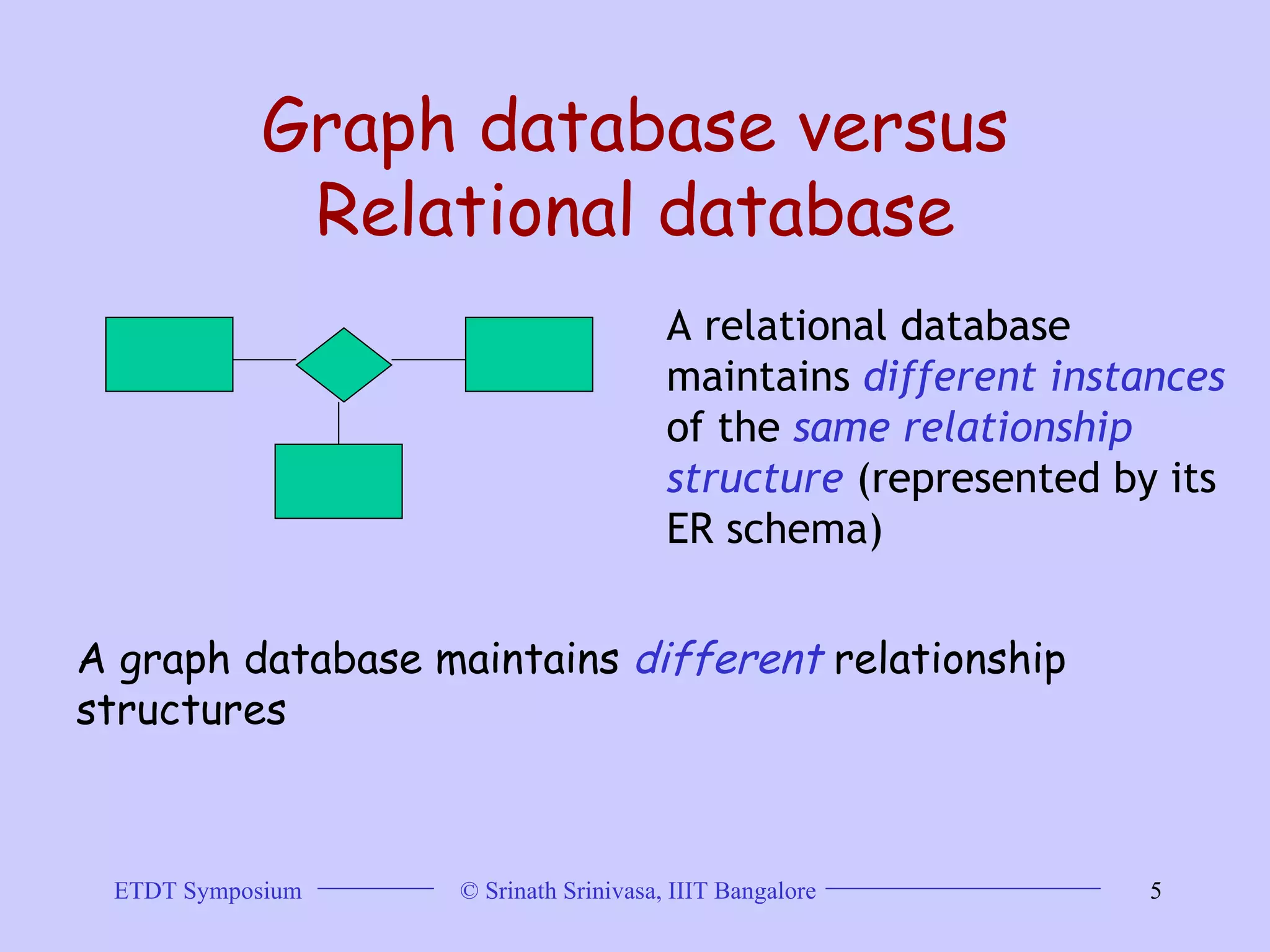
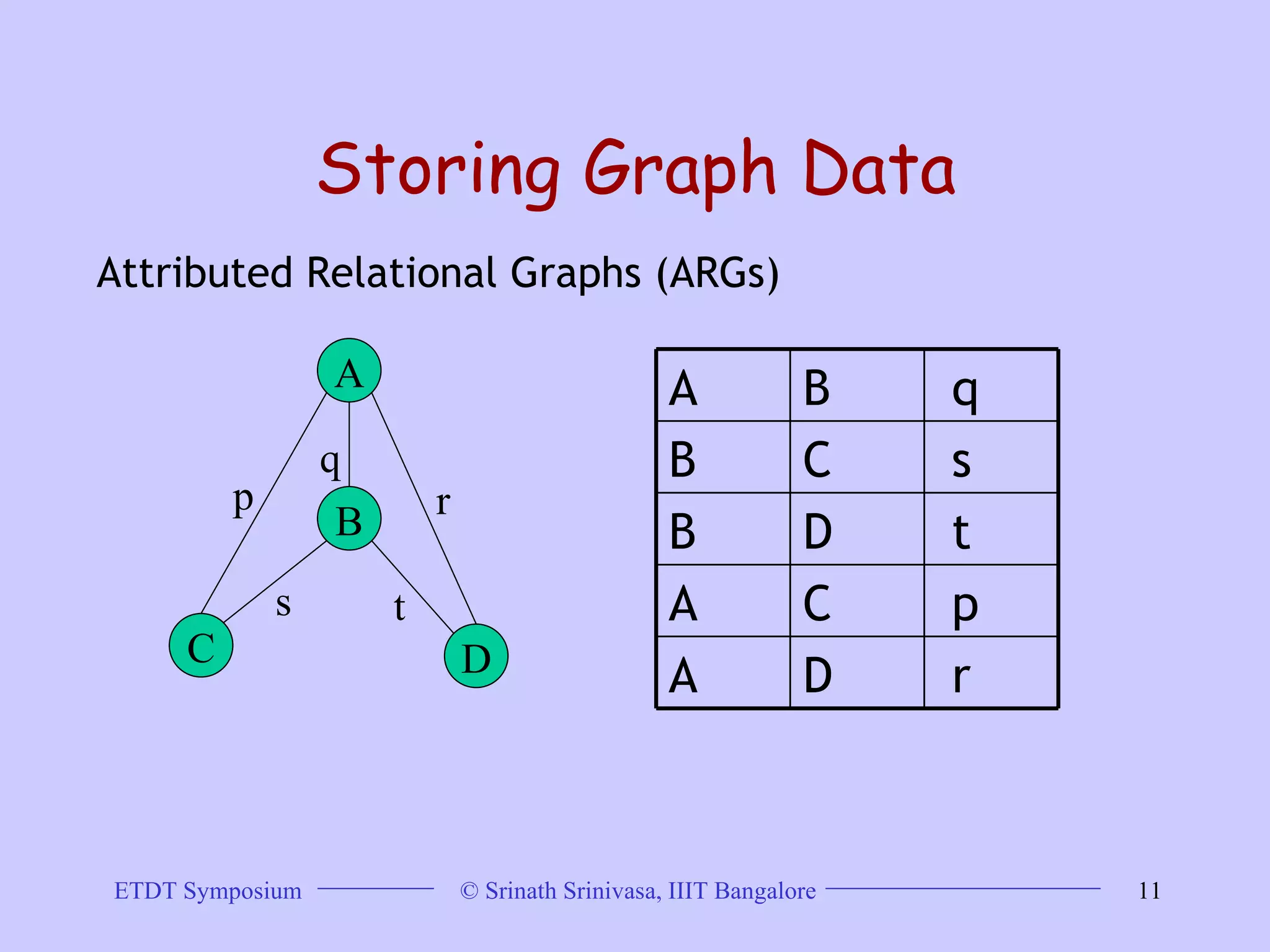
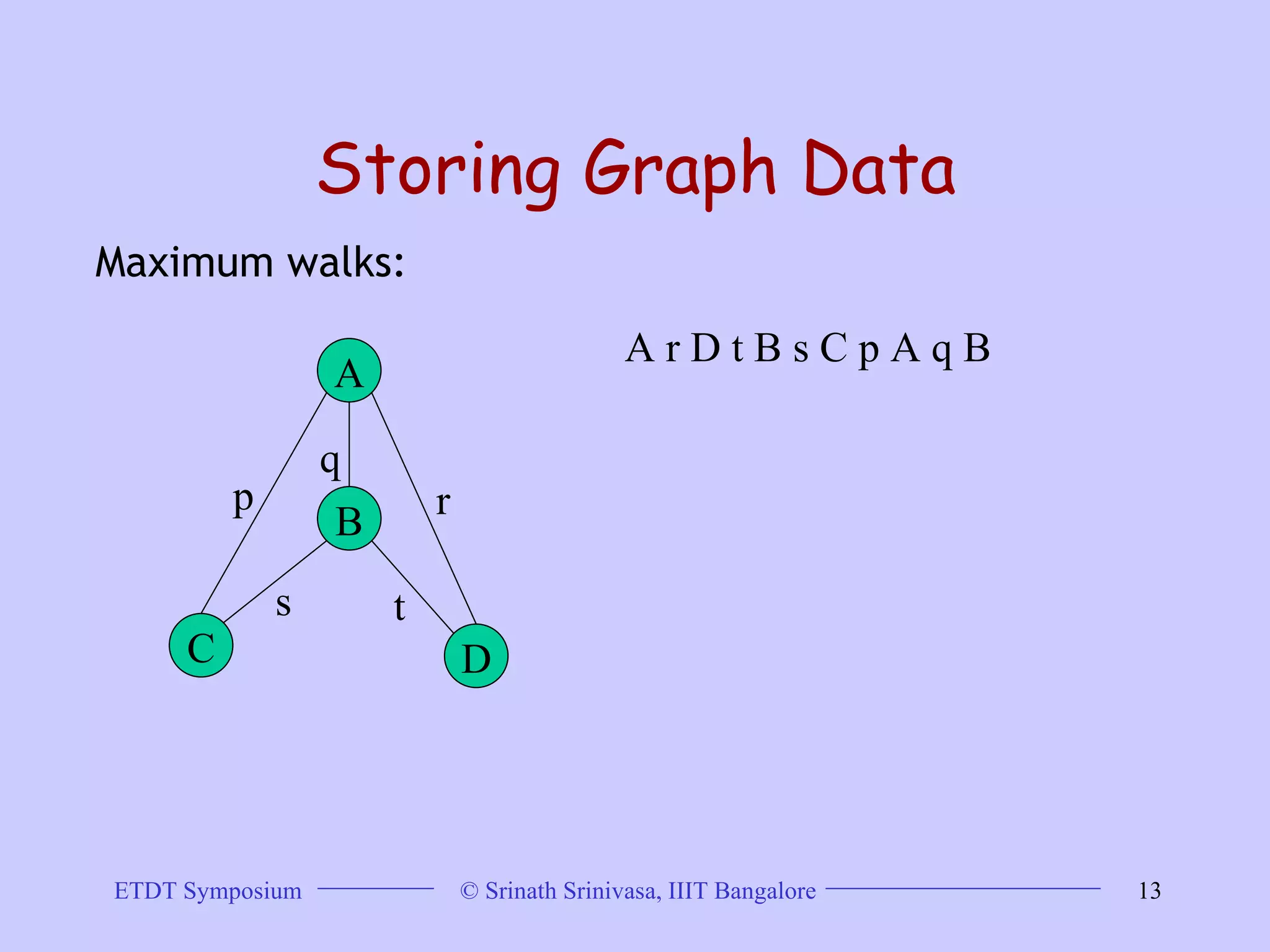
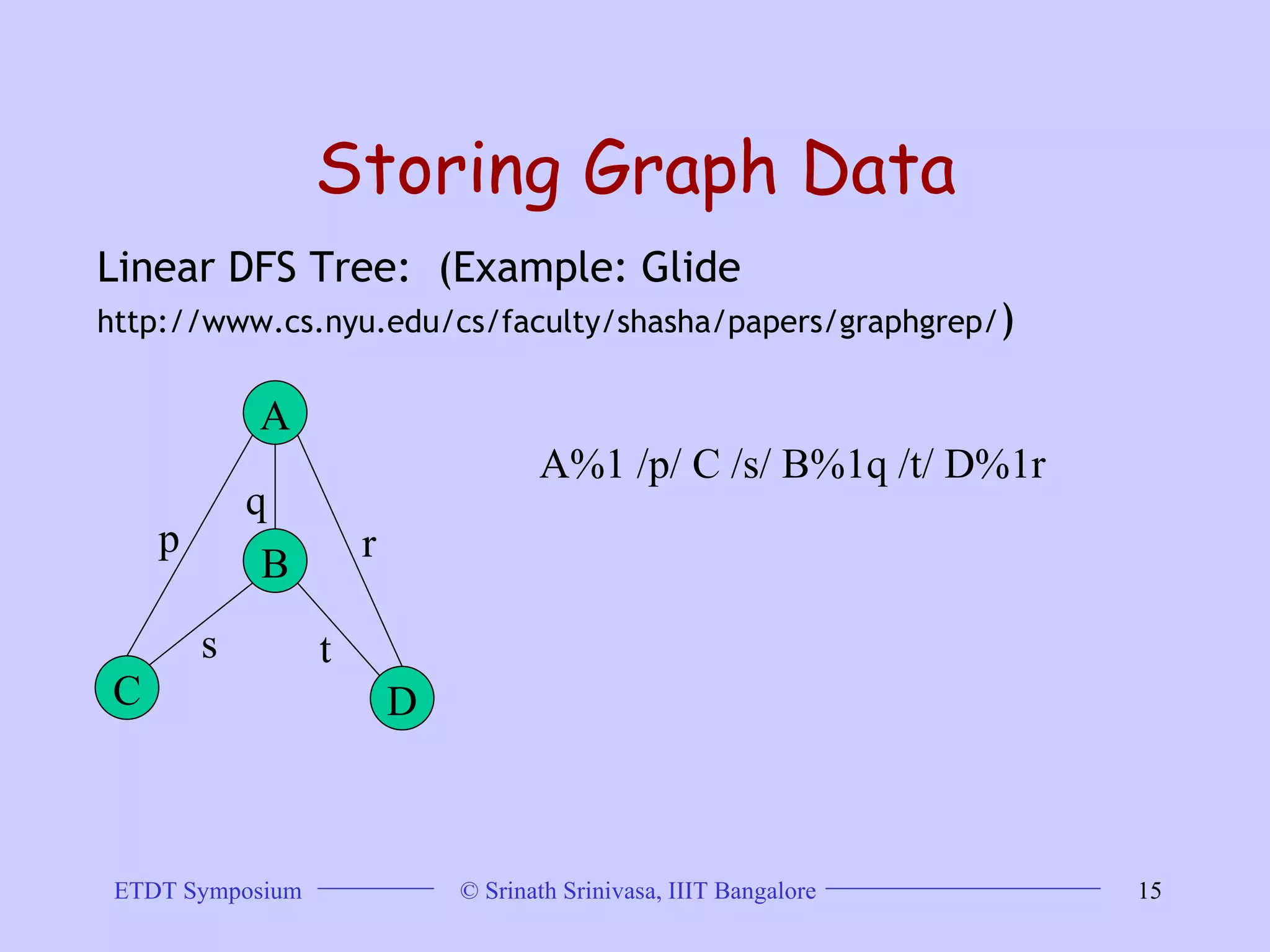
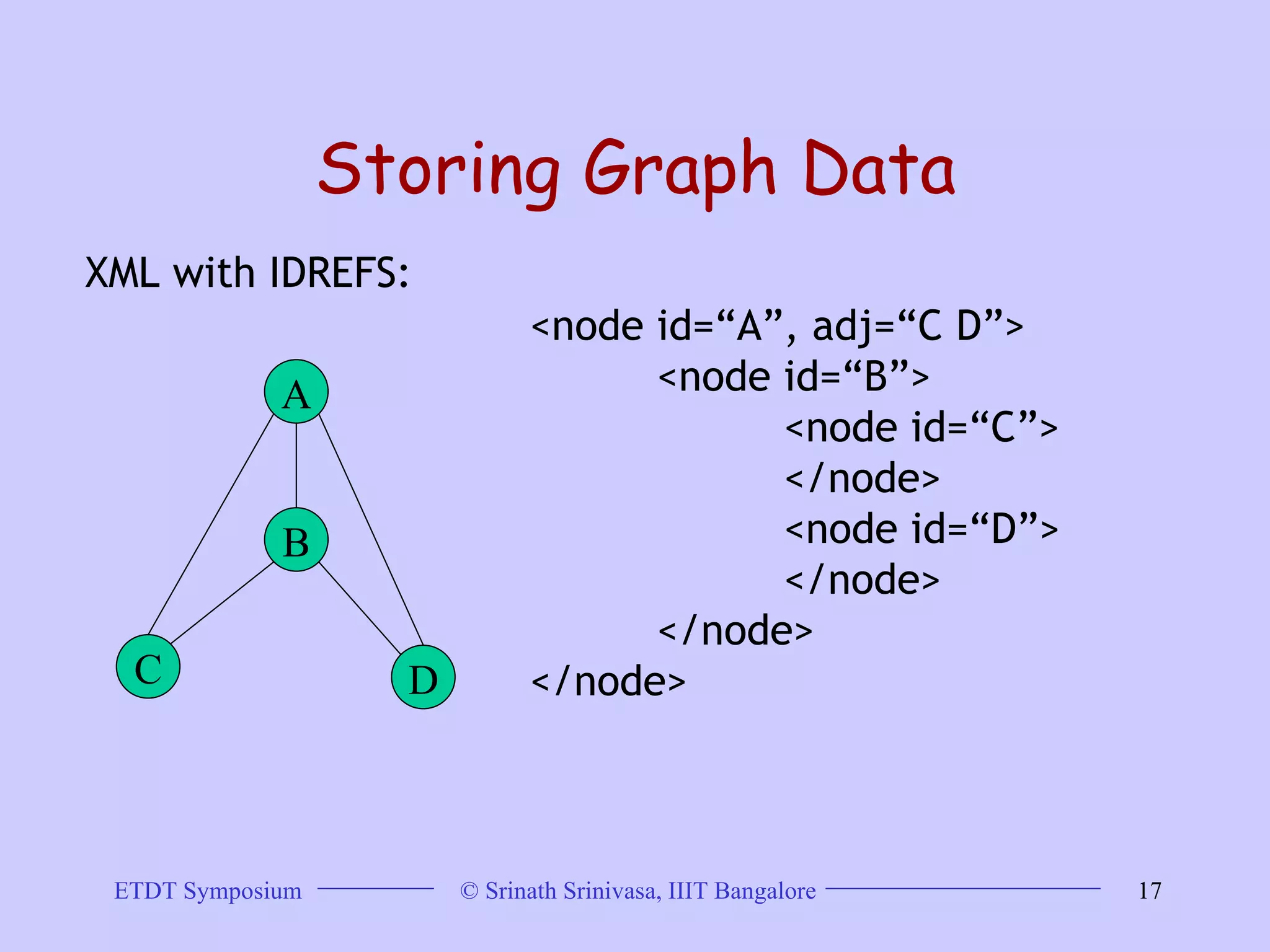
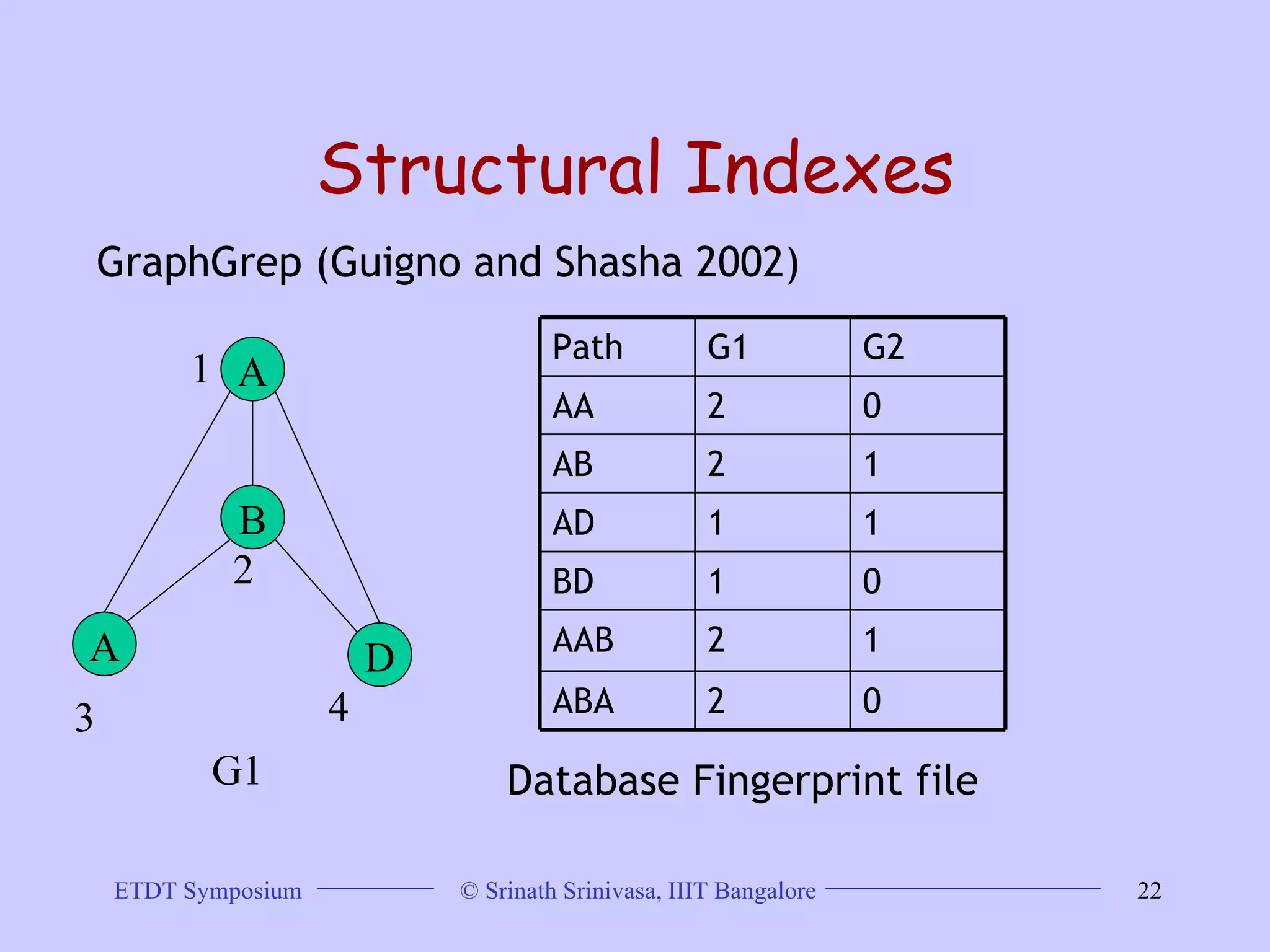
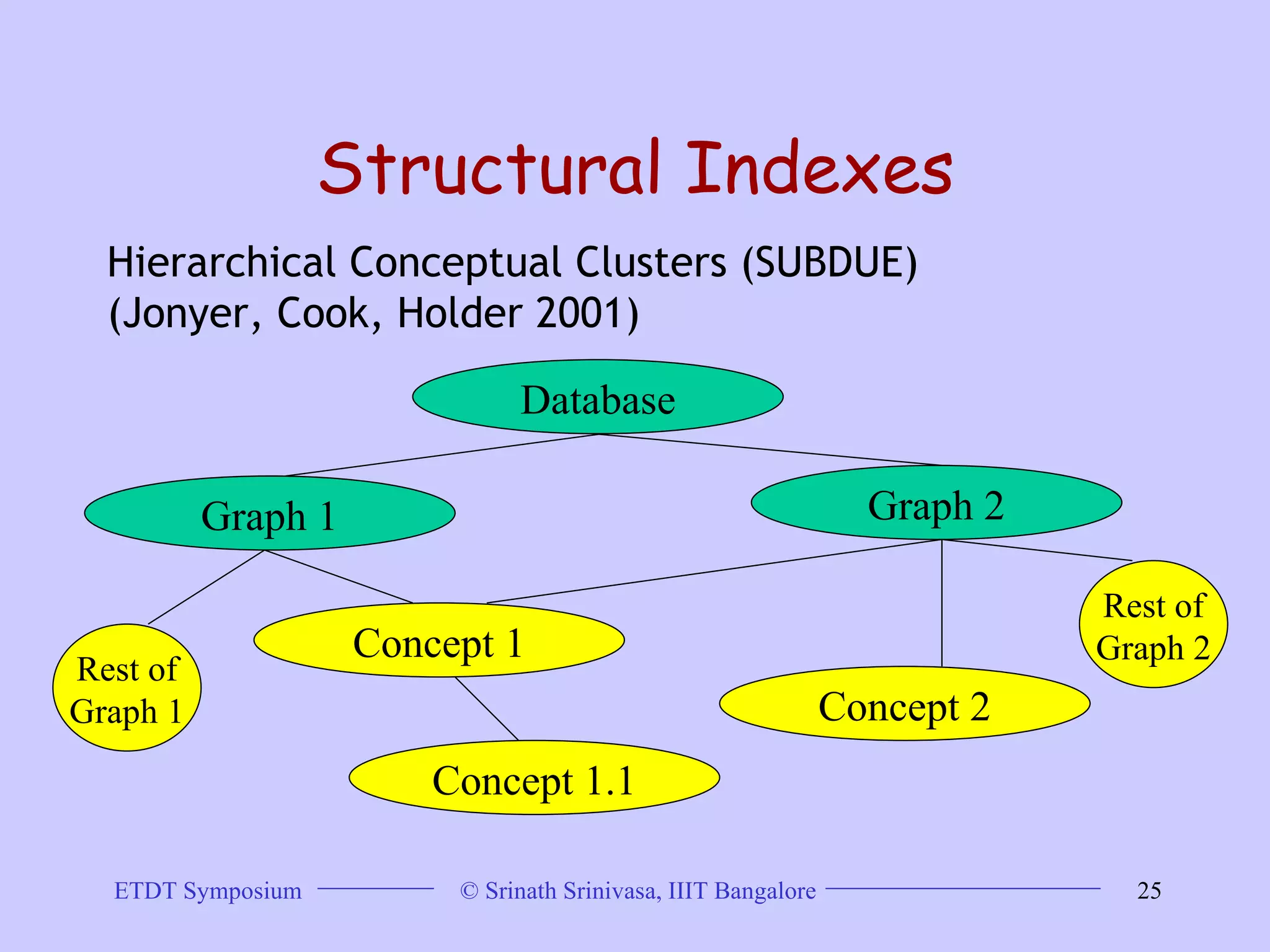
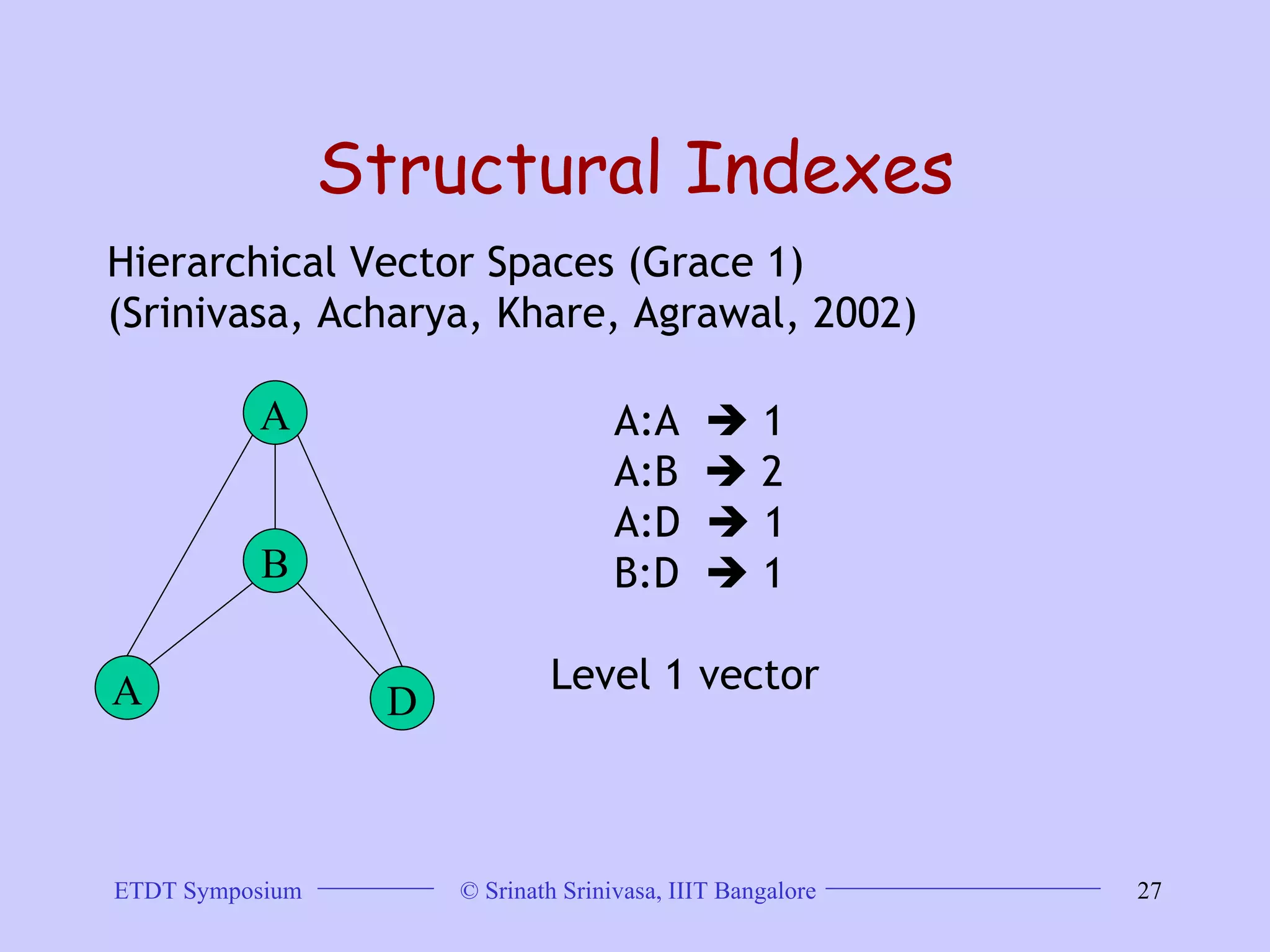
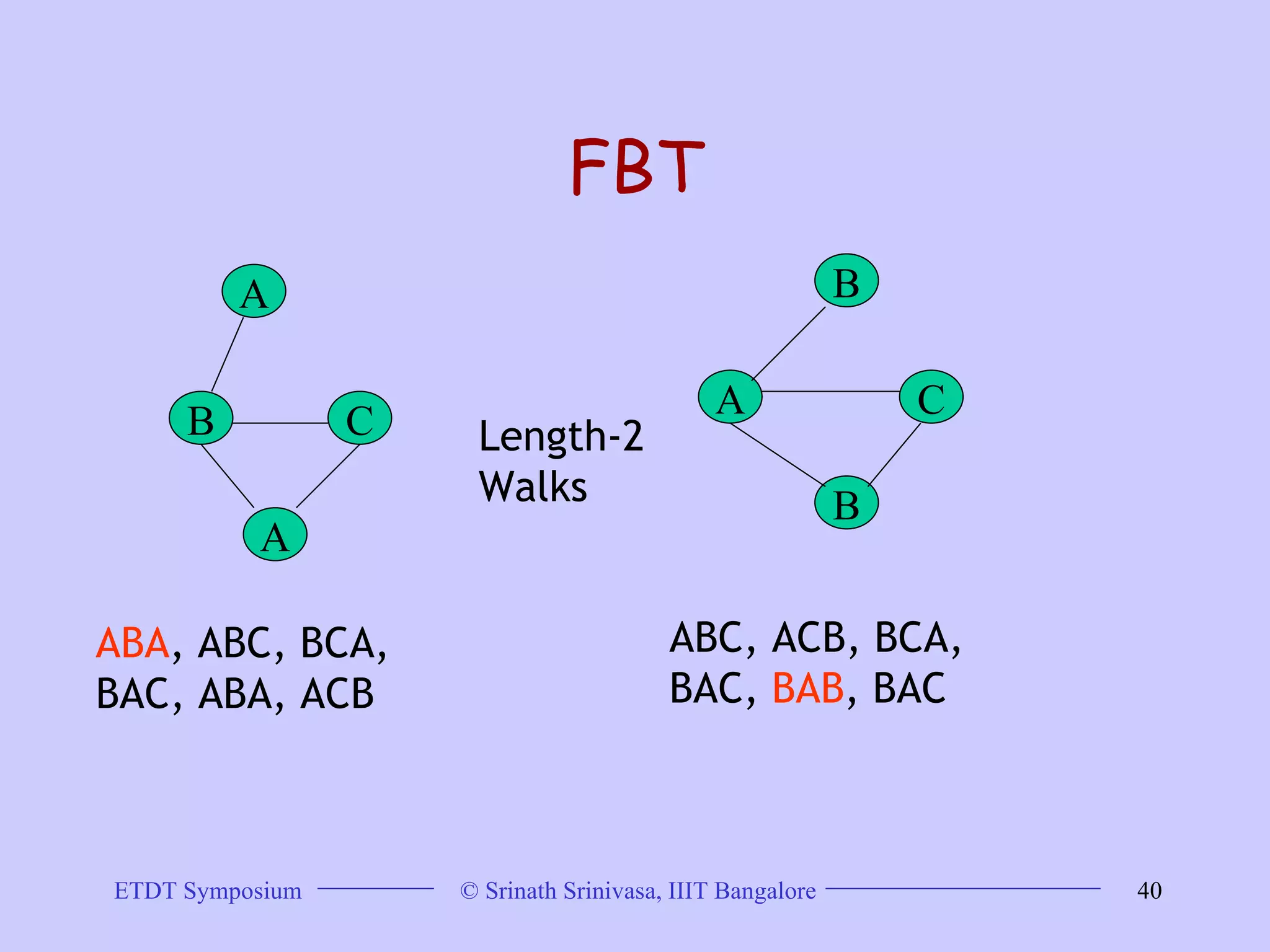
This document discusses trends in graph data management and mining, highlighting the characteristics of graph databases compared to relational databases. It covers various storage models, querying methods, and structural indexes for efficient data retrieval, along with mining frequent subgraphs using techniques like gspan and filtration-based approaches. Applications span various fields, including bioinformatics and software engineering, emphasizing the importance of effective graph representation and querying strategies.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












